
10.3: Diseños de investigación de una sola asignatura
- Page ID
- 144620

Características generales de los diseños de un solo sujeto
Antes de analizar cualquier diseño específico de investigación de una sola asignatura, será útil considerar algunas características que son comunes a la mayoría de ellos. Muchas de estas características se ilustran en la Figura\(\PageIndex{1}\), que muestra los resultados de un estudio genérico de una sola asignatura. Primero, la variable dependiente (representada en el eje y de la gráfica) se mide repetidamente a lo largo del tiempo (representada por el eje x) a intervalos regulares. Segundo, el estudio se divide en distintas fases, y el participante es probado bajo una condición por fase. Las condiciones a menudo se designan con mayúsculas: A, B, C, etc. Así, la Figura\(\PageIndex{1}\) representa un diseño en el que el participante se probó primero en una condición (A), luego se probó en otra condición (B), y finalmente se volvió a ensayar en la condición original (A). (Esto se llama un diseño de inversión y se discutirá con más detalle en breve).
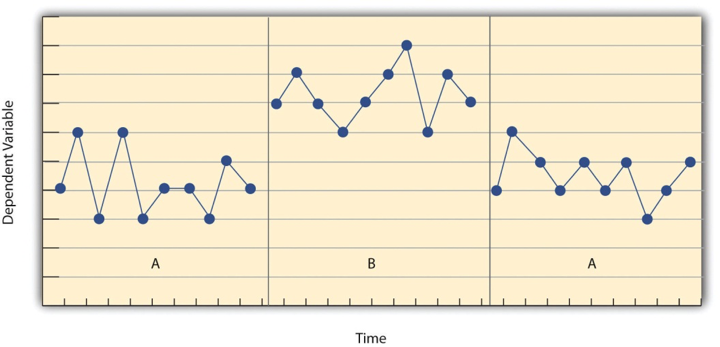
Otro aspecto importante de la investigación de un solo sujeto es que el cambio de una condición a la siguiente no suele ocurrir después de una cantidad fija de tiempo o número de observaciones. En cambio, depende del comportamiento del participante. Específicamente, el investigador espera hasta que el comportamiento del participante en una condición se vuelva bastante consistente de la observación a la observación antes de cambiar las condiciones. Esto a veces se conoce como la estrategia de estado estacionario (Sidman, 1960) [1]. La idea es que cuando la variable dependiente ha alcanzado un estado estacionario, entonces cualquier cambio a través de las condiciones será relativamente fácil de detectar. Recordemos que nos encontramos con este mismo principio al discutir la investigación experimental de manera más general. El efecto de una variable independiente es más fácil de detectar cuando se minimiza el “ruido” en los datos.
Diseños de inversión
El diseño de investigación de una sola asignatura más básico es el diseño de inversión, también llamado diseño ABA. Durante la primera fase, A, se establece una línea base para la variable dependiente. Este es el nivel de respuesta antes de que se introduzca cualquier tratamiento, y por lo tanto la fase basal es una especie de condición de control. Cuando se alcanza la respuesta en estado estacionario, la fase B comienza cuando el investigador introduce el tratamiento. Puede haber un periodo de ajuste al tratamiento durante el cual el comportamiento de interés se vuelve más variable y comienza a aumentar o disminuir. Nuevamente, el investigador espera hasta que esa variable dependiente alcance un estado estacionario para que quede claro si ha cambiado y cuánto ha cambiado. Finalmente, el investigador retira el tratamiento y vuelve a esperar hasta que la variable dependiente alcance un estado estacionario. Este diseño básico de reversión también se puede extender con la reintroducción del tratamiento (ABAB), otro retorno a la línea base (ABABA), y así sucesivamente.
El estudio de Hall y sus colegas empleó un diseño de inversión ABAB. La figura\(\PageIndex{2}\) aproxima los datos de Robbie. El porcentaje de tiempo que pasó estudiando (la variable dependiente) fue bajo durante la primera fase basal, aumentó durante la primera fase de tratamiento hasta que se niveló, disminuyó durante la segunda fase basal y volvió a aumentar durante la segunda fase de tratamiento.
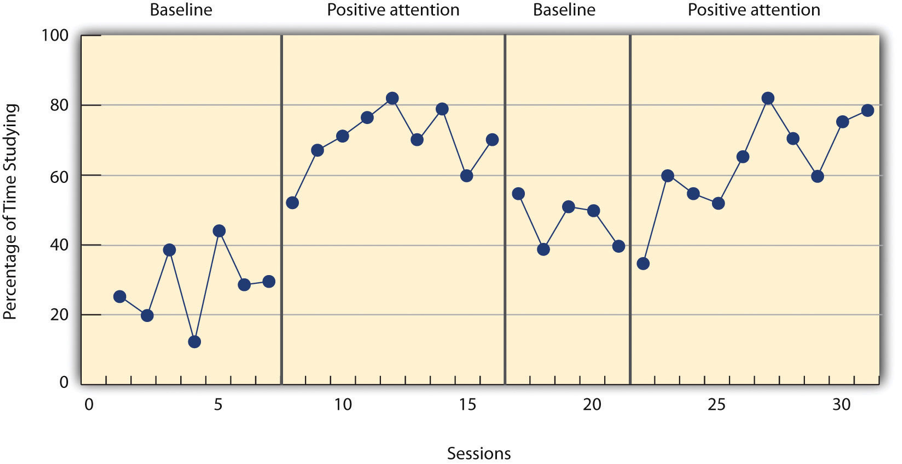
¿Por qué se considera necesaria la reversión —la eliminación del tratamiento— en este tipo de diseño? ¿Por qué usar un diseño ABA, por ejemplo, en lugar de un diseño AB más simple? Observe que un diseño AB es esencialmente un diseño de serie temporal interrumpida aplicado a un participante individual. Recordemos que un problema con ese diseño es que si la variable dependiente cambia después de que se introduce el tratamiento, no siempre está claro que el tratamiento fue el responsable del cambio. Es posible que algo más haya cambiado aproximadamente al mismo tiempo y que esta variable extraña sea responsable del cambio en la variable dependiente. Pero si la variable dependiente cambia con la introducción del tratamiento y luego vuelve a cambiar con la eliminación del tratamiento (asumiendo que el tratamiento no crea un efecto permanente), es mucho más claro que el tratamiento (y la eliminación del tratamiento) es la causa. En otras palabras, la inversión aumenta en gran medida la validez interna del estudio.
Existen parientes cercanos del diseño básico de reversión que permiten la evaluación de más de un tratamiento. En un diseño de reversión de tratamiento múltiple, una fase basal es seguida por fases separadas en las que se introducen diferentes tratamientos. Por ejemplo, un investigador podría establecer una línea de base de comportamiento de estudio para un estudiante disruptivo (A), luego introducir un tratamiento que implique atención positiva por parte del maestro (B), y luego cambiar a un tratamiento que implique un castigo leve por no estudiar (C). Luego, el participante podría regresar a una fase basal antes de reintroducir cada tratamiento, quizás en el orden inverso como una forma de controlar los efectos de arrastre. Este diseño particular de inversión de tratamiento múltiple también podría denominarse un diseño ABCACB.
En un diseño de tratamientos alternos, dos o más tratamientos se alternan de manera relativamente rápida en un horario regular. Por ejemplo, la atención positiva para estudiar podría usarse un día y un castigo leve por no estudiar al siguiente, y así sucesivamente. O un tratamiento podría implementarse por la mañana y otro por la tarde. El diseño de tratamientos alternos puede ser una forma rápida y efectiva de comparar tratamientos, pero solo cuando los tratamientos son de acción rápida.
Diseños de línea base múltiple
Hay dos problemas potenciales con el diseño de inversión, ambos relacionados con la eliminación del tratamiento. Una es que si un tratamiento está funcionando, puede ser poco ético eliminarlo. Por ejemplo, si un tratamiento pareciera reducir la incidencia de autolesiones en un niño con retraso intelectual, sería poco ético eliminar ese tratamiento solo para demostrar que la incidencia de autolesiones aumenta. El segundo problema es que la variable dependiente puede no volver a la línea base cuando se retira el tratamiento. Por ejemplo, cuando se elimina la atención positiva para estudiar, un estudiante podría continuar estudiando a un ritmo mayor. Esto podría significar que la atención positiva tuvo un efecto duradero en el estudio del estudiante, lo que por supuesto sería bueno. Pero también podría significar que la atención positiva no fue realmente la causa del aumento del estudio en primer lugar. Quizás algo más sucedió aproximadamente al mismo tiempo que el tratamiento; por ejemplo, los padres del estudiante podrían haber comenzado a recompensarlo por sus buenas calificaciones. Una solución a estos problemas es utilizar un diseño de línea base múltiple, el cual se representa en la Figura\(\PageIndex{3}\). Hay tres tipos diferentes de diseños de línea base múltiple que ahora consideraremos.
Diseño de línea base múltiple entre los participantes
En una versión del diseño, se establece una línea de base para cada uno de varios participantes, y luego se introduce el tratamiento para cada uno de ellos. En esencia, cada participante es probado en un diseño AB. La clave de este diseño es que el tratamiento se introduce en un momento diferente para cada participante. La idea es que si la variable dependiente cambia cuando se introduce el tratamiento para un participante, podría ser una coincidencia. Pero si la variable dependiente cambia cuando se introduce el tratamiento para múltiples participantes, especialmente cuando el tratamiento se introduce en diferentes momentos para los diferentes participantes, entonces es poco probable que sea una coincidencia.
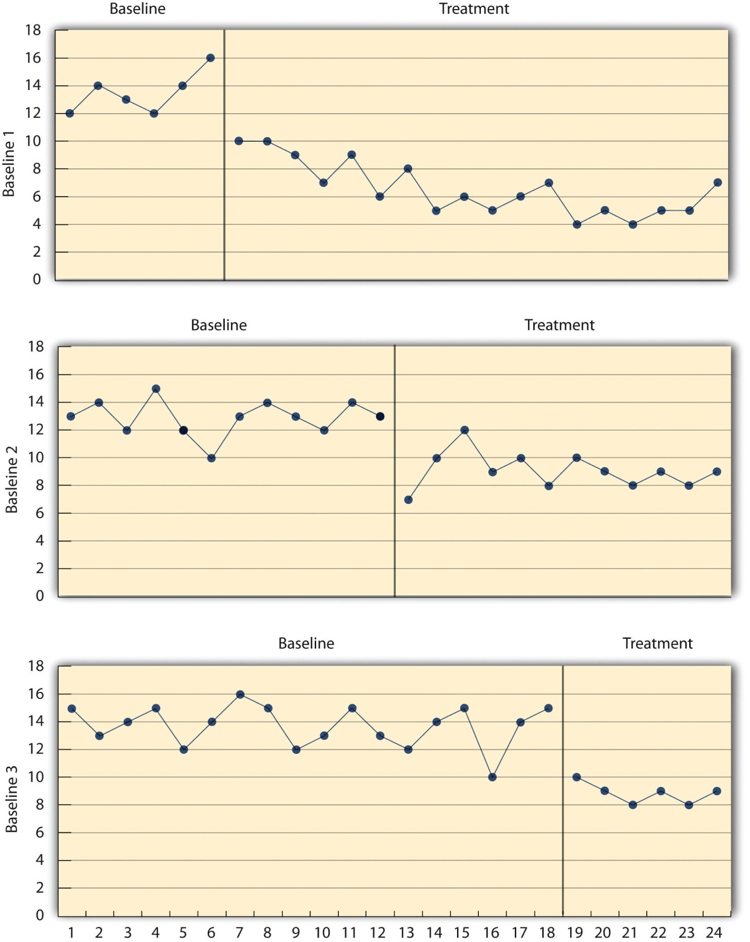
Como ejemplo, considere un estudio de Scott Ross y Robert Horner (Ross & Horner, 2009) [2]. Estaban interesados en cómo un programa de prevención del acoso escolar afectaba el comportamiento de acoso escolar de estudiantes con problemas particulares. En cada una de tres escuelas diferentes, los investigadores estudiaron a dos estudiantes que se habían involucrado regularmente en el acoso escolar. Durante la fase basal, observaron a los estudiantes por periodos de 10 minutos cada día durante el recreo del almuerzo y contaron el número de comportamientos agresivos que exhibieron hacia sus compañeros. Después de 2 semanas, implementaron el programa en una escuela. Después de 2 semanas más, lo implementaron en la segunda escuela. Y después de 2 semanas más, lo implementaron en la tercera escuela. Encontraron que el número de conductas agresivas exhibidas por cada estudiante disminuyó poco después de que el programa fuera implementado en la escuela del alumno. Observe que si los investigadores solo hubieran estudiado una escuela o si hubieran introducido el tratamiento al mismo tiempo en las tres escuelas, entonces no estaría claro si la reducción de las conductas agresivas se debió al programa de bullying o a algo más que sucedió aproximadamente al mismo tiempo que se introdujo (ej., unas vacaciones, un programa de televisión, un cambio en el clima). Pero con su diseño de línea base múltiple, este tipo de coincidencia tendría que ocurrir tres veces distintas, una ocurrencia muy improbable, para explicar sus resultados.
Diseño de línea base múltiple a través de comportamientos
En otra versión del diseño de línea base múltiple, se establecen múltiples líneas base para el mismo participante pero para diferentes variables dependientes, y el tratamiento se introduce en un momento diferente para cada variable dependiente. Imagínese, por ejemplo, un estudio sobre el efecto de establecer metas claras en la productividad de un oficinista que tiene dos tareas principales: hacer llamadas de ventas y escribir informes. Podrían establecerse líneas de base para ambas tareas. Por ejemplo, el investigador podría medir el número de llamadas de ventas realizadas e informes escritos por el trabajador cada semana durante varias semanas. Entonces se podría introducir el tratamiento de establecimiento de metas para una de estas tareas, y en un momento posterior se podría introducir el mismo tratamiento para la otra tarea. La lógica es la misma que antes. Si la productividad aumenta en una tarea después de que se introduce el tratamiento, no está claro si el tratamiento causó el aumento. Pero si la productividad aumenta en ambas tareas después de que se introduce el tratamiento, especialmente cuando el tratamiento se introduce en dos momentos diferentes, entonces parece mucho más claro que el tratamiento fue el responsable.
Diseño de línea base múltiple en todos los parámetros
Aún en una tercera versión del diseño de línea base múltiple, se establecen múltiples líneas de base para el mismo participante pero en diferentes entornos. Por ejemplo, podría establecerse una línea de base para la cantidad de tiempo que un niño pasa leyendo durante su tiempo libre en la escuela y durante su tiempo libre en casa. Entonces un tratamiento como la atención positiva podría introducirse primero en la escuela y después en casa. Nuevamente, si la variable dependiente cambia después de que se introduce el tratamiento en cada entorno, entonces esto le da al investigador la confianza de que el tratamiento es, de hecho, responsable del cambio.
Análisis de datos en investigación de una sola asignatura
Además de su enfoque en participantes individuales, la investigación de un solo sujeto difiere de la investigación grupal en la forma en que los datos se analizan típicamente. Como hemos visto a lo largo del libro, la investigación grupal implica combinar datos entre los participantes. Los datos de grupo se describen utilizando estadísticas como medias, desviaciones estándar, coeficientes de correlación, etc. para detectar patrones generales. Por último, se utilizan estadísticas inferenciales para ayudar a decidir si es probable que el resultado de la muestra se generalice a la población. La investigación de un solo sujeto, por el contrario, se basa en gran medida en un enfoque muy diferente llamado inspección visual. Esto significa trazar los datos de los participantes individuales como se muestra a lo largo de este capítulo, mirar cuidadosamente esos datos y emitir juicios sobre si la variable independiente tuvo un efecto sobre la variable dependiente y en qué medida. Por lo general, no se utilizan estadísticas inferenciales.
Al inspeccionar visualmente sus datos, los investigadores de un solo sujeto toman en cuenta varios factores. Uno de ellos son los cambios en el nivel de la variable dependiente de condición a condición. Si la variable dependiente es mucho mayor o mucho menor en una condición que en otra, esto sugiere que el tratamiento tuvo un efecto. Un segundo factor es la tendencia, que se refiere a incrementos o disminuciones graduales en la variable dependiente a través de las observaciones. Si la variable dependiente comienza a aumentar o disminuir con un cambio en las condiciones, entonces nuevamente esto sugiere que el tratamiento tuvo un efecto. Puede ser especialmente revelador cuando una tendencia cambia de dirección, por ejemplo, cuando un comportamiento no deseado aumenta durante la línea base pero luego comienza a disminuir con la introducción del tratamiento. Un tercer factor es la latencia, que es el tiempo que tarda la variable dependiente en comenzar a cambiar después de un cambio en las condiciones. En general, si un cambio en la variable dependiente comienza poco después de un cambio en las condiciones, esto sugiere que el tratamiento fue el responsable.
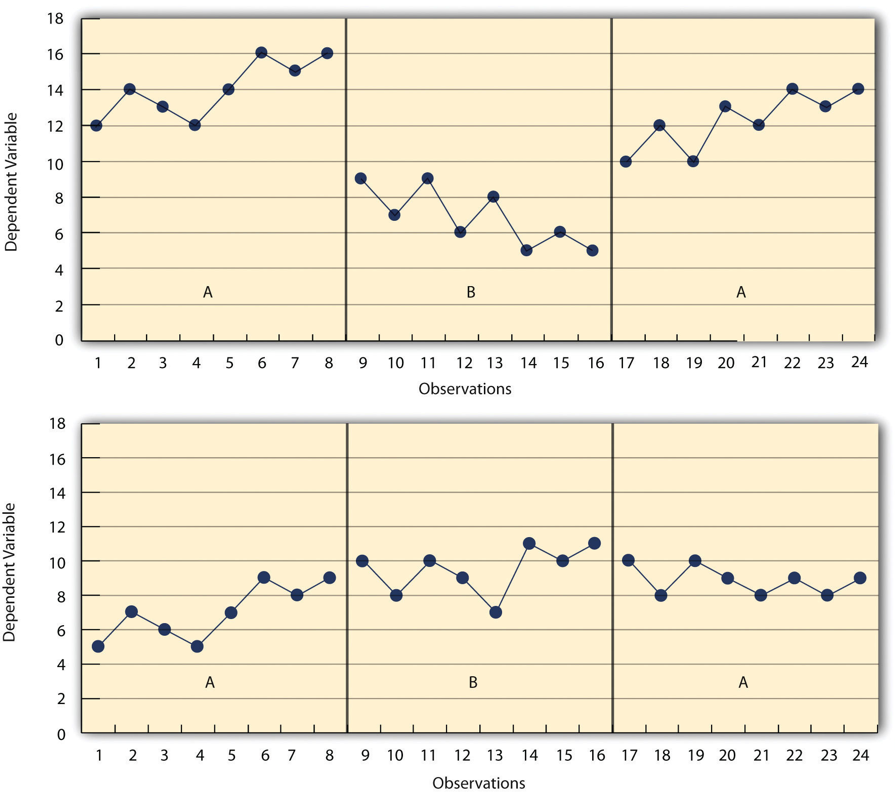
En el panel superior de la Figura\(\PageIndex{4}\), hay cambios bastante obvios en el nivel y tendencia de la variable dependiente de condición a condición. Además, las latencias de estos cambios son cortas; el cambio ocurre inmediatamente. Este patrón de resultados sugiere fuertemente que el tratamiento fue responsable de los cambios en la variable dependiente. En el panel inferior de la Figura\(\PageIndex{4}\), sin embargo, los cambios de nivel son bastante pequeños. Y aunque parece haber una tendencia creciente en el padecimiento de tratamiento, parece que podría ser una continuación de una tendencia que ya había comenzado durante la línea base. Este patrón de resultados sugiere fuertemente que el tratamiento no fue responsable de ningún cambio en la variable dependiente, al menos no en la medida en que los investigadores de un solo sujeto suelen esperar ver.
Los resultados de la investigación de una sola asignatura también se pueden analizar mediante procedimientos estadísticos, y esto es cada vez más común. Hay muchos enfoques diferentes, y los investigadores de un solo tema continúan debatiendo cuáles son los más útiles. Un enfoque es paralelo a lo que se suele hacer en la investigación grupal. Se calcula y compara la media y desviación estándar de las respuestas de cada participante bajo cada condición, y se aplican pruebas estadísticas inferenciales como la prueba t o análisis de varianza (Fisch, 2001) [3]. (Tenga en cuenta que el promedio entre los participantes es menos común). Otro enfoque es calcular el porcentaje de datos no superpuestos (PND) para cada participante (Scruggs & Mastropieri, 2001) [4]. Este es el porcentaje de respuestas en la condición de tratamiento que son más extremas que la respuesta más extrema en una condición de control relevante. En el estudio de Hall y sus colegas, por ejemplo, todas las medidas del tiempo de estudio de Robbie en la primera condición de tratamiento fueron mayores que la medida más alta en la primera línea de base, para un PND del 100%. Cuanto mayor sea el porcentaje de datos no superpuestos, más fuerte será el efecto del tratamiento. Aún así, los enfoques estadísticos formales para el análisis de datos en la investigación de un solo sujeto generalmente se consideran un complemento de la inspección visual, no un reemplazo de la misma.
Referencias
- Sidman, M. (1960). Tácticas de investigación científica: Evaluación de datos experimentales en psicología. Boston, MA: Cooperativa de Autores.
- Ross, S. W., & Horner, R. H. (2009). Prevención del acosador en apoyo a la conducta positiva. Revista de Análisis de Comportamiento Aplicado, 42, 747—759.
- Fisch, G. S. (2001). Evaluación de datos a partir del análisis conductual: Inspección visual o modelos estadísticos. Procesos conductuales, 54, 137—154.
- Scruggs, T. E., & Mastropieri, M. A. (2001). Cómo resumir la investigación de un solo participante: Ideas y aplicaciones. Excepcionalidad, 9, 227—244.