
13.4: Consideraciones adicionales
- Page ID
- 144610

En esta sección, consideramos algunas otras cuestiones relacionadas con las pruebas de hipótesis nulas, incluyendo algunas que son útiles en estudios de planeación e interpretación de resultados. Incluso consideramos algunas críticas de larga data a las pruebas de hipótesis nulas, junto con algunos pasos que los investigadores en psicología han dado para abordarlas.
Errores en las pruebas de hipótesis nulas
En las pruebas de hipótesis nulas, el investigador intenta sacar una conclusión razonable sobre la población a partir de la muestra. Desafortunadamente, no se garantiza que esta conclusión sea correcta. Esta discrepancia se ilustra en la Figura\(\PageIndex{1}\). Las filas de esta tabla representan las dos posibles decisiones que los investigadores pueden tomar en las pruebas de hipótesis nulas: rechazar o retener la hipótesis nula. Las columnas representan los dos estados posibles del mundo: la hipótesis nula es falsa o es verdadera. Las cuatro celdas de la tabla, entonces, representan los cuatro resultados distintos de una prueba de hipótesis nula. Dos de los resultados —rechazar la hipótesis nula cuando es falsa y conservarla cuando es verdad— son decisiones correctas. Los otros dos —rechazar la hipótesis nula cuando es verdadera y conservarla cuando es falsa— son errores.
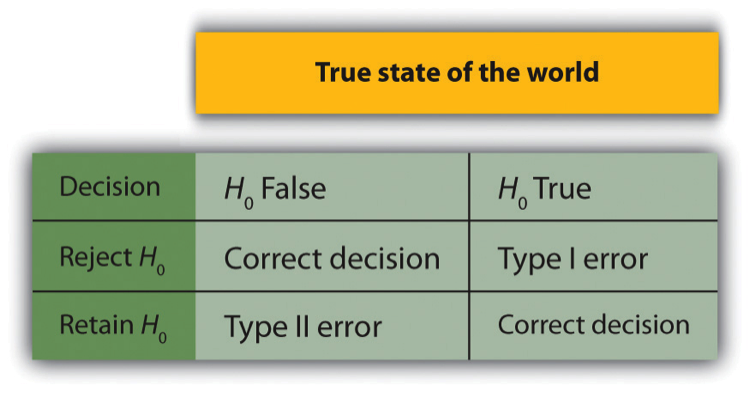
Rechazar la hipótesis nula cuando es verdadera se denomina error Tipo I. Este error significa que hemos llegado a la conclusión de que existe una relación en la población cuando en realidad no la hay. Los errores de tipo I ocurren porque incluso cuando no hay relación en la población, el error de muestreo por sí solo ocasionalmente producirá un resultado extremo. De hecho, cuando la hipótesis nula es verdadera y α es .05, rechazaremos erróneamente la hipótesis nula el 5% de las veces. (Esta posibilidad es la razón por la que α a veces se conoce como la “tasa de error de tipo I”). Conservar la hipótesis nula cuando es falsa se denomina error Tipo II. Este error significa que hemos concluido que no hay relación en la población cuando de hecho existe una relación. En la práctica, los errores de Tipo II ocurren principalmente porque el diseño de la investigación carece del poder estadístico adecuado para detectar la relación (por ejemplo, la muestra es demasiado pequeña). En breve tendremos más que decir sobre el poder estadístico.
En principio, es posible reducir la posibilidad de un error de Tipo I estableciendo α a algo menor que .05. Ponerlo en .01, por ejemplo, significaría que si la hipótesis nula es cierta, entonces solo hay un 1% de posibilidades de rechazarla erróneamente. Pero dificultar el rechazo de verdaderas hipótesis nulas también hace más difícil rechazar las falsas y, por lo tanto, aumenta la probabilidad de que se produzca un error de Tipo II. De igual manera, es posible reducir la probabilidad de un error Tipo II estableciendo α en algo mayor que .05 (e.g., .10). Pero facilitar el rechazo de falsas hipótesis nulas también facilita el rechazo de las verdaderas y, por lo tanto, aumenta la posibilidad de que se produzca un error de Tipo I. Esto proporciona una idea de por qué la convención va a establecer α en .05. Existe cierto acuerdo entre los investigadores en que el nivel .05 de α mantiene las tasas de errores tanto de Tipo I como de Tipo II en niveles aceptables.
La posibilidad de cometer errores Tipo I y Tipo II tiene varias implicaciones importantes para interpretar los resultados de la investigación propia y ajena. Una es que debemos ser cautelosos al interpretar los resultados de cualquier estudio individual porque existe la posibilidad de que refleje un error de Tipo I o Tipo II. Esta posibilidad es por lo que los investigadores consideran importante replicar sus estudios. Cada vez que los investigadores replican un estudio y encuentran un resultado similar, con razón se vuelven más seguros de que el resultado representa un fenómeno real y no solo un error de Tipo I o Tipo II.

Otro tema relacionado con los errores Tipo I es el llamado problema del cajón de archivos (Rosenthal, 1979) [1]. La idea es que cuando los investigadores obtienen resultados estadísticamente significativos, tienden a enviarlos para su publicación, y los editores y revisores de revistas tienden a aceptarlos. Pero cuando los investigadores obtienen resultados no significativos, tienden a no enviarlos para su publicación, o si los envían, los editores y revisores de revistas tienden a no aceptarlos. Los investigadores terminan guardando estos resultados no significativos en un cajón de archivos (o hoy en día, en una carpeta de su disco duro). Un efecto de esta tendencia es que la literatura publicada probablemente contenga una mayor proporción de errores de Tipo I de lo que cabría esperar solo a partir de consideraciones estadísticas. Incluso cuando existe una relación entre dos variables en la población, es probable que la literatura de investigación publicada exagere la fuerza de esa relación. Imagínese, por ejemplo, que la relación entre dos variables en la población es positiva pero débil (e.g., ρ = +.10). Si varios investigadores realizan estudios sobre esta relación, entonces es probable que el error de muestreo produzca resultados que van desde relaciones negativas débiles (p. ej., r = −.10) hasta relaciones positivas moderadamente fuertes (p. ej., r = +.40). Pero debido al problema del cajón de archivos, es probable que solo se publiquen aquellos estudios que produzcan relaciones positivas de moderadas a fuertes. El resultado es que el efecto reportado en la literatura publicada tiende a ser más fuerte de lo que realmente es en la población.
El problema del cajón de archivos es difícil porque es producto de la forma en que tradicionalmente se ha realizado y publicado la investigación científica. Una solución son los informes registrados, mediante los cuales los editores y revisores de revistas evalúan las investigaciones enviadas para su publicación sin conocer los resultados de esa investigación (ver https://cos.io/rr/). La idea es que si se juzga que la pregunta de investigación es interesante y se juzga que el método es sólido, entonces un resultado no significativo debería ser tan importante y digno de publicación como uno significativo. A falta de un cambio tan radical en la forma en que se evalúa la investigación para su publicación, los investigadores aún pueden esforzarnos por mantener sus resultados no significativos y compartirlos lo más ampliamente posible (por ejemplo, en repositorios disponibles públicamente y en conferencias profesionales). Muchas disciplinas científicas cuentan ahora con revistas dedicadas a publicar resultados no significativos. En psicología, por ejemplo, está la Revista de Artículos en Apoyo a la Hipótesis Null (http://www.jasnh.com).
En 2014, Uri Simonsohn, Leif Nelson y Joseph Simmons publicaron un artículo (Simonsohn, Nelson, & Simmons, 2014) [2] acusando a investigadores de psicología de crear demasiados errores Tipo I en psicología al dedicarse a prácticas de investigación que llamaron p -hacking. Los investigadores que p-hack toman diversas decisiones en el proceso de investigación para aumentar su probabilidad de un resultado estadísticamente significativo (y error tipo I) eliminando arbitrariamente valores atípicos, eligiendo selectivamente reportar variables dependientes, presentando solo resultados significativos, etc. hasta sus resultados producir un valor p deseable. Su trabajo innovador contribuyó a una conversación importante en el campo sobre los estándares de publicación y la mejora de la confiabilidad de nuestros resultados que continúa hoy en día.
Poder Estadístico
El poder estadístico de un diseño de investigación es la probabilidad de rechazar la hipótesis nula dado el tamaño de la muestra y la fuerza de relación esperada. Por ejemplo, el poder estadístico de un estudio con 50 participantes y una r esperada de Pearson de +.30 en la población es de .59. Es decir, hay un 59% de posibilidades de rechazar la hipótesis nula si efectivamente la correlación poblacional es +.30. El poder estadístico es el complemento de la probabilidad de cometer un error Tipo II. Entonces en este ejemplo, la probabilidad de cometer un error Tipo II sería 1 − .59 = .41. Claramente, los investigadores deben estar interesados en el poder de sus diseños de investigación si quieren evitar cometer errores de Tipo II. En particular, deben asegurarse de que su diseño de investigación tenga el poder adecuado antes de recopilar datos. Una pauta común es que un poder de .80 es adecuado. Esta directriz significa que existe un 80% de probabilidad de rechazar la hipótesis nula para la fuerza de relación esperada.
El tema de cómo calcular el poder para diversos diseños de investigación y pruebas de hipótesis nulas está fuera del alcance de este libro. Sin embargo, existen herramientas en línea que le permiten hacer esto ingresando su tamaño de muestra, fuerza de relación esperada y nivel α para varias pruebas de hipótesis (consulte “Computing Power Online”). Además, la Tabla\(\PageIndex{1}\) muestra el tamaño de muestra necesario para lograr una potencia de .80 para relaciones débiles, medias y fuertes para una prueba t de muestras independientes de dos colas y para una prueba de dos colas de r de Pearson. Observe que esta tabla amplifica el punto hecho anteriormente sobre la fuerza de la relación, el tamaño de la muestra y la significancia estadística. En particular, las relaciones débiles requieren muestras muy grandes para proporcionar un poder estadístico adecuado.
| Prueba de hipótesis nula | ||
|---|---|---|
| Fuerza de la relación | Prueba t- de muestras independientes | Prueba de r de Pearson |
| Fuerte (d = .80, r = .50) | 52 | 28 |
| Mediana (d = .50, r = .30) | 128 | 84 |
| Débil (d = .20, r = .10) | 788 | 782 |
¿Qué debes hacer si descubres que tu diseño de investigación no tiene el poder adecuado? Imagina, por ejemplo, que estás realizando un experimento entre sujetos con 20 participantes en cada una de dos condiciones y que esperas una diferencia media (d = .50) en la población. El poder estadístico de este diseño es de sólo .34. Es decir, aunque haya una diferencia media en la población, solo hay una probabilidad de uno en tres de rechazar la hipótesis nula y aproximadamente una probabilidad de dos en tres de cometer un error de Tipo II. Dado el tiempo y esfuerzo involucrados en la realización del estudio, esto probablemente parece una probabilidad inaceptablemente baja de rechazar la hipótesis nula y una probabilidad inaceptablemente alta de cometer un error de Tipo II.
Dado que el poder estadístico depende principalmente de la fuerza de la relación y el tamaño de la muestra, hay esencialmente dos pasos que puede tomar para aumentar el poder estadístico: aumentar la fuerza de la relación o aumentar el tamaño de la muestra. El aumento de la fuerza de la relación a veces se puede lograr usando una manipulación más fuerte o controlando más cuidadosamente variables extrañas para reducir la cantidad de ruido en los datos (por ejemplo, usando un diseño dentro de los sujetos en lugar de un diseño entre sujetos). La estrategia habitual, sin embargo, es aumentar el tamaño de la muestra. Para cualquier fuerza de relación esperada, siempre habrá alguna muestra lo suficientemente grande como para lograr una potencia adecuada.
Problemas con las pruebas de hipótesis nulas y algunas soluciones
Nuevamente, la prueba de hipótesis nula es el enfoque más común de la estadística inferencial en psicología. No está exenta de críticas, sin embargo. De hecho, en los últimos años las críticas se han vuelto tan prominentes que la American Psychological Association convocó a un grupo de trabajo para hacer recomendaciones sobre cómo tratarlas (Wilkinson & Task Force on Statistical Inference, 1999) [3]. En esta sección, consideramos algunas de las críticas y algunas de las recomendaciones.
Críticas a las pruebas de hipótesis nulas
Algunas críticas a las pruebas de hipótesis nulas se centran en el malentendido de los investigadores. Ya hemos visto, por ejemplo, que el valor p es ampliamente malinterpretado como la probabilidad de que la hipótesis nula sea verdadera. (Recordemos que es realmente la probabilidad del resultado de la muestra si la hipótesis nula fuera cierta.) Una mala interpretación estrechamente relacionada es que 1 − p es igual a la probabilidad de replicar un resultado estadísticamente significativo. En un estudio, el 60% de una muestra de investigadores profesionales pensó que un valor de p de .01—para una prueba t- de muestras independientes con 20 participantes en cada muestra significó que había un 99% de probabilidad de replicar el resultado estadísticamente significativo (Oakes, 1986) [4]. Nuestra anterior discusión sobre el poder debería dejar claro que esta cifra es demasiado optimista. Como muestra el Cuadro 13.5, aunque existiera una gran diferencia entre medias en la población, se necesitarían 26 participantes por muestra para lograr una potencia de .80. Y el programa G*Power demuestra que requeriría 59 participantes por muestra para lograr una potencia de .99.
Otro conjunto de críticas se centra en la lógica de las pruebas de hipótesis nulas. Para muchos, la estricta convención de rechazar la hipótesis nula cuando p es menor que .05 y retenerla cuando p es mayor que .05 tiene poco sentido. Esta crítica no tiene que ver con el valor específico de .05 sino con la idea de que debe haber alguna línea divisoria rígida entre los resultados que se consideran significativos y los resultados que no lo son. Imagínese dos estudios sobre la misma relación estadística con tamaños de muestra similares. Uno tiene un valor p de .04 y el otro un valor p de .06. Si bien los dos estudios han producido esencialmente el mismo resultado, es probable que el primero sea considerado interesante y digno de publicación y el segundo simplemente no significativo. Es probable que esta convención evite que se publiquen buenas investigaciones y contribuya al problema del cajón de archivos.
Otro conjunto de críticas se centra en la idea de que las pruebas de hipótesis nulas, incluso cuando se entienden y se llevan a cabo correctamente, simplemente no son muy informativas. Recordemos que la hipótesis nula es que no existe relación entre variables en la población (por ejemplo, d de Cohen o r de Pearson es precisamente 0). Entonces rechazar la hipótesis nula es simplemente decir que existe alguna relación distinta de cero en la población. Pero esta aseveración en realidad no está diciendo mucho. Imagínese si la química pudiera decirnos solo que existe alguna relación entre la temperatura de un gas y su volumen, en lugar de proporcionar una ecuación precisa para describir esa relación. Algunos críticos incluso argumentan que la relación entre dos variables en la población nunca es precisamente 0 si se lleva a cabo con suficientes decimales. En otras palabras, la hipótesis nula nunca es literalmente cierta. ¡Así que rechazarlo no nos dice nada que no sabíamos ya!
Para ser justos, muchos investigadores han venido en defensa de las pruebas de hipótesis nulas. Uno de ellos, Robert Abelson, ha argumentado que cuando se entiende y lleva a cabo correctamente, las pruebas de hipótesis nulas sí sirven para un propósito importante (Abelson, 1995) [5]. Especialmente cuando se trata de nuevos fenómenos, brinda a los investigadores una forma basada en principios de convencer a otros de que sus resultados no deben descartarse como meras ocurrencias fortuitas.
¿Qué hacer?
Incluso quienes defienden las pruebas de hipótesis nulas reconocen muchos de los problemas con ella. Pero, ¿qué se debe hacer? Algunas sugerencias aparecen ahora en el Manual de Publicación de la APA. Una es que cada prueba de hipótesis nula debe ir acompañada de una medida del tamaño del efecto como la d de Cohen o la r de Pearson. Al hacerlo, el investigador proporciona una estimación de cuán fuerte es la relación en la población, no solo si la hay o no. (Recuerde que el valor p no puede sustituir como medida de fuerza de relación porque también depende del tamaño de la muestra. Incluso un resultado muy débil puede ser estadísticamente significativo si la muestra es lo suficientemente grande).
Otra sugerencia es usar intervalos de confianza en lugar de pruebas de hipótesis nulas. Un intervalo de confianza alrededor de una estadística es un rango de valores que se calcula de tal manera que algún porcentaje del tiempo (generalmente 95%) el parámetro de población estará dentro de ese rango. Por ejemplo, una muestra de 20 estudiantes universitarios podría tener una estimación calórica media para una galleta con chispas de chocolate de 200 con un intervalo de confianza del 95% de 160 a 240. Es decir, existe una muy buena probabilidad (95%) de que la estimación calórica media para la población de estudiantes universitarios se sitúe entre 160 y 240. Los defensores de los intervalos de confianza argumentan que son mucho más fáciles de interpretar que las pruebas de hipótesis nulas. Otra ventaja de los intervalos de confianza es que proporcionan la información necesaria para hacer pruebas de hipótesis nulas en caso de que alguien quiera. En este ejemplo, la media muestral de 200 es significativamente diferente en el nivel .05 de cualquier media hipotética poblacional que se encuentre fuera del intervalo de confianza. Entonces el intervalo de confianza de 160 a 240 nos dice que la media muestral es estadísticamente significativamente diferente de una hipotética media poblacional de 250 (porque el intervalo de confianza no incluye el valor de 250).
Finalmente, existen soluciones más radicales a los problemas de las pruebas de hipótesis nulas que implican el uso de enfoques muy diferentes para la estadística inferencial. La estadística bayesiana, por ejemplo, es un enfoque en el que el investigador especifica la probabilidad de que la hipótesis nula y cualquier hipótesis alternativa importante sean verdaderas antes de realizar el estudio, realice el estudio y luego actualice las probabilidades con base en los datos. Es demasiado pronto para decir si este enfoque se volverá común en la investigación psicológica. Por ahora, la prueba de hipótesis nula, apoyada por medidas de tamaño de efecto e intervalos de confianza, sigue siendo el enfoque dominante.
Referencias
- Rosenthal, R. (1979). El problema del cajón de archivos y la tolerancia para resultados nulos. Boletín Psicológico, 83, 638—641.
- Simonsohn U., Nelson L. D., & Simmons J. P. (2014). Curva P: una llave para el cajón de archivos. Revista de Psicología Experimental: General, 143 (2), 534—547. doi: 10.1037/a0033242
- Wilkinson, L., & Task Force on Statistical Inference. (1999). Métodos estadísticos en revistas de psicología: Guías y explicaciones. Psicólogo Americano, 54, 594—604.
- Oakes, M. (1986). Inferencia estadística: Un comentario para las ciencias sociales y del comportamiento. Chichester, Reino Unido: Wiley.
- Abelson, R. P. (1995). La estadística como argumento de principios. Mahwah, NJ: Erlbaum.
- Tramimow, D. & Marks, M. (2015). Editorial. Psicología Social Básica y Aplicada, 37, 1—2. [1]https://dx.doi.org/10.1080/01973533.2015.1012991