
3.2: Estadística de Dispersión
- Page ID
- 149215

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
- Un estadístico de dispersión te dice qué tan extendido está un conjunto de mediciones. La desviación estándar es la más común, pero hay otras.
Resumir datos de una variable de medición requiere un número que represente el “centro” de un conjunto de números (conocido como “estadística de tendencia central” o “estadística de ubicación”), junto con una medida del “spread” de los números (conocido como “estadística de dispersión”). Se utiliza una estadística de dispersión para dar un solo número que describa cuán compacto o extendido es un conjunto de observaciones. Aunque las estadísticas de dispersión no suelen ser muy interesantes por sí mismas, forman la base de la mayoría de las pruebas estadísticas utilizadas en las variables de medición.
Rango
Esta es simplemente la diferencia entre las observaciones más grandes y las más pequeñas. Esta es la estadística de dispersión que la gente usa en la conversación cotidiana; si le estuvieras contando a tu tío Cletus sobre tu investigación sobre el isópodo gigante de aguas profundas Bathynomus giganteus, no hablarías sobre los medios y las desviaciones estándar, dirías que iban desde\(4.4cm\) hasta\(36.5cm\) largo (Biornes-Fourzán y Lozano-Álvarez 1991). Entonces explicarías que los isópodos son roly-polies, y\(36.5cm\) es de aproximadamente pulgadas\(14\) americanas, y el tío Cletus finalmente quedaría impresionado, porque un roly-poly que mide más de un pie de largo es bastante impresionante.
El rango no es muy informativo para fines estadísticos. El rango depende únicamente de los valores más grandes y más pequeños, de manera que dos conjuntos de datos con distribuciones muy diferentes podrían tener el mismo rango, o dos muestras de una misma población podrían tener rangos muy diferentes, puramente por casualidad. Además, el rango aumenta a medida que aumenta el tamaño de la muestra; cuantas más observaciones hagas, mayor será la probabilidad de que muestres un valor muy grande o muy pequeño.
No hay función de rango en las hojas de cálculo; puede calcular el rango usando: Rango = MAX (Ys) −MIN (Ys), donde\(Ys\) representa un conjunto de celdas.
Suma de cuadrados
Esto no es realmente un estadístico de dispersión por sí mismo, pero lo menciono aquí porque forma la base de la varianza y desviación estándar. Restar la media de una observación y cuadrar esta “desviación”. La cuadratura de los desviados hace que todos los cuadrados se desvíen positivos y tiene otras ventajas estadísticas. Haz esto para cada observación, luego suma estos desviados al cuadrado. Esta suma del cuadrado se desvía de la media se conoce como la suma de cuadrados. Está dada por la función de hoja de cálculo DEVSQ (Ys) (no por la función SUMSQ). Probablemente nunca tendrás una razón para calcular la suma de cuadrados, pero es un concepto importante.
Varianza paramétrica
Si tomas la suma de cuadrados y la divides por el número de observaciones (\(n\)), estás calculando la desviación cuadrada promedio de la media. A medida que las observaciones se dispersan cada vez más, se alejan de la media, y la desviación promedio al cuadrado se hace más grande. Esta desviación cuadrada promedio, o suma de cuadrados dividida por\(n\), es la varianza paramétrica. Sólo se puede calcular la varianza paramétrica de una población si se tienen observaciones para cada miembro de una población, lo que casi nunca es el caso. No se me ocurre un buen ejemplo biológico donde sería apropiado usar la varianza paramétrica; solo lo menciono porque hay una función de hoja de cálculo para ello que nunca debes usar, VARP (Ys).
Varianza de la muestra
Casi siempre tienes una muestra de observaciones que estás utilizando para estimar un parámetro de población. Para obtener una estimación imparcial de la varianza poblacional, divida la suma de cuadrados por\(n-1\), no por\(n\). Esta varianza de muestra, que es la que usarás siempre, viene dada por la función de hoja de cálculo VAR (Ys). A partir de aquí, cuando veas “varianza”, significa la varianza muestral.
Podrías pensar que si configuraste un experimento donde le diste suéteres argyle a\(10\) conejillos de indias, y midiste la temperatura corporal\(10\) de todos ellos, deberías usar la varianza paramétrica y no la varianza de la muestra. Al fin y al cabo tendrías la temperatura corporal de toda la población de conejillos de indias con suéteres argyle en el mundo. No obstante, para fines estadísticos debes considerar que tus conejillos de indias con suéter son una muestra de todos los conejillos de indias del mundo que podrían haber usado un jersey argyle, por lo que lo mejor sería usar la varianza muestral. Incluso si vas a la Isla Española y mides la longitud de cada tortuga (Geochelone nigra hoodensis) en la población de tortugas que allí viven, para la mayoría de los propósitos lo mejor sería considerarlas una muestra de todas las tortugas que podrían haber estado viviendo allí.
Desviación estándar
La varianza, si bien tiene propiedades estadísticas útiles que la convierten en la base de muchas pruebas estadísticas, es en unidades cuadradas. Un conjunto de longitudes medidas en centímetros tendría una varianza expresada en centímetros cuadrados, lo cual es simplemente extraño; un conjunto de volúmenes medidos en\(cm^3\) tendría una varianza expresada en\(cm^6\), que es aún más extraña. Tomando la raíz cuadrada de la varianza da una medida de dispersión que se encuentra en las unidades originales. La raíz cuadrada de la varianza paramétrica es la desviación estándar paramétrica, que nunca usará; viene dada por la función de hoja de cálculo STDEVP (Ys). La raíz cuadrada de la varianza muestral viene dada por la función de hoja de cálculo STDEV (Ys). Siempre debes usar la desviación estándar de la muestra; a partir de aquí, cuando veas “desviación estándar”, significa la desviación estándar de la muestra.
La raíz cuadrada de la varianza de la muestra en realidad subestima un poco la desviación estándar de la muestra. A Gurland y Tripathi (1971) se les ocurrió un factor de corrección que da una estimación más precisa de la desviación estándar, pero muy pocas personas la utilizan. Su factor de corrección hace que la desviación estándar sea aproximadamente\(3\%\) más grande con un tamaño de muestra de\(9\), y aproximadamente\(1\%\) más grande con un tamaño de muestra de\(25\), por ejemplo, y la mayoría de las personas simplemente no necesitan estimar la desviación estándar con esa precisión. Ni SAS ni Excel utilizan la corrección Gurland y Tripathi; la he incluido como opción en mi hoja de cálculo de estadísticas descriptivas. Si usas la desviación estándar con la corrección Gurland y Tripathi, asegúrate de decir esto cuando escribas tus resultados.
Además de ser más comprensible que la varianza como medida de la cantidad de variación en los datos, la desviación estándar resume lo cerca que están las observaciones a la media de manera comprensible. Muchas variables en biología se ajustan bastante bien a la distribución de probabilidad normal. Si una variable se ajusta a la distribución normal,\(68.3\%\) (o aproximadamente dos tercios) de los valores están dentro de una desviación estándar de la media,\(95.4\%\) están dentro de dos desviaciones estándar de la media, y\(99.7\) (o casi todas) están dentro de las desviaciones\(3\) estándar de la media. Así, si alguien dice que la longitud media de los pies de los hombres es\(270mm\) con una desviación estándar de\(13mm\), sabes que alrededor de dos tercios de los pies de los hombres están entre\(257mm\) y\(283mm\) largos, y aproximadamente\(95\%\) de los pies de los hombres están entre\(244mm\) y\(296mm\) largos. Aquí hay un histograma que ilustra esto:
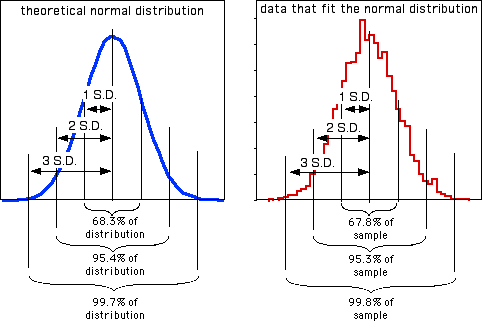
Las proporciones de los datos que están dentro\(1\)\(2\), o desviaciones\(3\) estándar de la media son diferentes si los datos no se ajustan a la distribución normal, como se muestra para estos dos conjuntos de datos muy no normales:

Coeficiente de variación
El coeficiente de variación es la desviación estándar dividida por la media; resume la cantidad de variación como porcentaje o proporción del total. Es útil al comparar la cantidad de variación para una variable entre grupos con diferentes medias, o entre diferentes variables de medición. Por ejemplo, los militares de Estados Unidos midieron la longitud del pie y el ancho del pie en 1774 hombres estadounidenses. La desviación estándar de la longitud del pie fue\(13.1mm\) y la desviación estándar para el ancho del pie fue\(5.26mm\), lo que hace que parezca que la longitud del pie es más variable que la anchura del pie. Sin embargo, los pies son más largos que anchos. Dividiendo por las medias (\(269.7mm\)para longitud,\(100.6mm\) para ancho), los coeficientes de variación son en realidad ligeramente más pequeños para length (\(4.9\%\)) que para width (\(5.2\%\)), lo que para la mayoría de los propósitos sería una medida de variación más útil.
Ejemplo
Aquí están las estadísticas de dispersión para los datos de dace de nariz negra de la página web de tendencia central. En realidad, rara vez tendrías alguna razón para reportar todos estos:
- Rango 90
- Varianza 1029.5
- Desviación estándar 32.09
- Coeficiente de variación 45.8%
Cómo calcular las estadísticas
Hoja de Cálculo
He realizado una hoja de cálculo descriptive.xls que calcula el rango, varianza muestral, desviación estándar muestral (con o sin la corrección de Gurland y Tripathi), y coeficiente de variación, para hasta\(1000\) observaciones.
Páginas web
Esta página web calcula la desviación estándar y otras estadísticas descriptivas para hasta\(10,000\) observaciones.
Esta página web calcula el rango, la varianza y la desviación estándar, junto con otras estadísticas descriptivas. No sé el número máximo de observaciones que puede manejar.
R
El\(R\) compañero de Salvatore Mangiafico cuenta con un programa R de muestra para calcular el rango, la varianza muestral, la desviación estándar y el coeficiente de variación.
SAS
PROC UNIVARIATE calculará el rango, varianza, desviación estándar (sin la corrección de Gurland y Tripathi) y coeficiente de variación. Calcula la varianza muestral y la desviación estándar de la muestra. Para ejemplos, consulte la página web de tendencia central.
Referencia
- Briones-Fourzán, P., y E. Lozano-Álvarez. 1991. Aspectos de la biología del isópodo gigante Bathynomus giganteus A. Milne Edwards, 1879 (Flabellifera: Cirolanidae), frente a la Península de Yucatán. Revista de Biología de Crustáceos 11:375-385.
- Gurland, J., y R.C. Tripathi. 1971. Una aproximación simple para la estimación imparcial de la desviación estándar. Estadístico Americano 25:30-32.