
7.2: Estimación de modelos lineales
- Page ID
- 150283

Con los modelos estocásticos no sabemos si se cumplen los supuestos de error, ni conocemos los valores de αα y ββ; por lo tanto debemos estimarlos, como denota un hat (e.g., ^αα^ es la estimación para αα). El modelo estocástico como se muestra en la Ecuación (7.4) se estima como:
YI=^α+^βxi+i (7.4) (7.4) YI=α^+β^xi+i
donde ii es el término residual o el término de error estimado. Dado que ninguna línea puede pasar perfectamente por todos los puntos de datos, introducimos un residual,, en la ecuación de regresión. Tenga en cuenta que el valor predicho de YY se denota ^YY^ (yy-hat).
yi=^α+^βxi+i=^yi+ii=yi−^yi=yi−^α−^α−^βxiYI=α^+β^xi+i=yi^+ii=yi−yi^=yi−α^−α−β^Xi
7.2.1 Residuales
Los residuos miden los errores de predicción de hasta qué punto está la observación YiYi de la predicción ^YiYI^. Esto se muestra en la Figura\(\PageIndex{3}\).
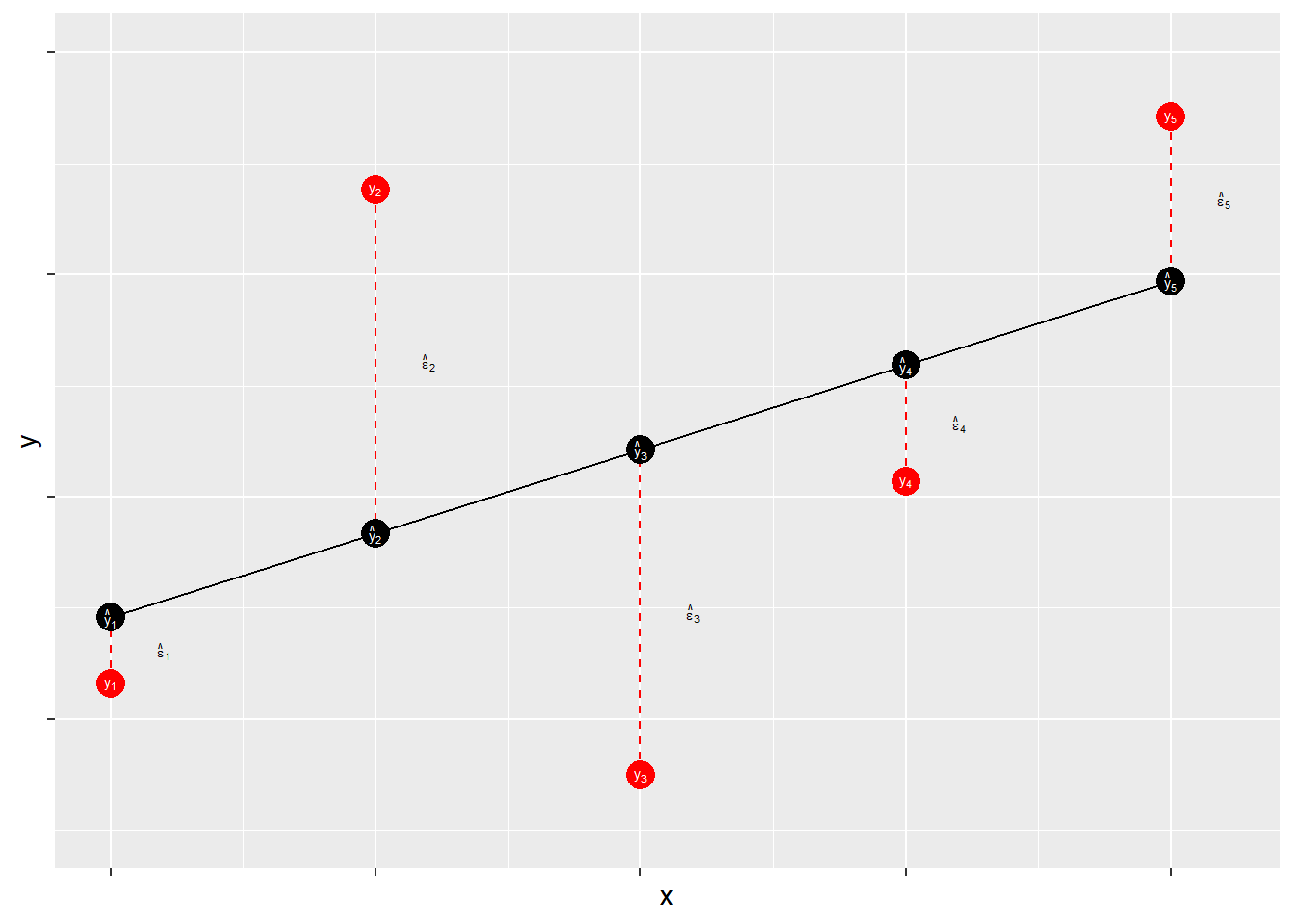
El término residual contiene la acumulación (suma) de errores que pueden resultar de problemas de medición, problemas de modelado y aleatoriedad irreducible. Idealmente, el término residual contiene muchas influencias pequeñas e independientes que dan como resultado una calidad aleatoria general de la distribución de los errores. Cuando esa distribución no es aleatoria —es decir, cuando la distribución del error tiene alguna calidad sistemática— las estimaciones de ^αα^ y ^ββ^ pueden estar sesgadas. Así, cuando evaluemos nuestros modelos nos centraremos en la forma de la distribución de nuestros errores.
¿Qué hay en?
Error de medición
- Operacionalizaciones imperfectas
- Aplicación de medida imperfecta
Error de modelado
- Error de modelar/especificación incorrecta
- Falta la explicación del modelo
- Suposiciones incorrectas sobre asociaciones
- Suposiciones incorrectas sobre las distribuciones
“Ruido” estocástico
- Variabilidad impredecible en la variable dependiente
El objetivo del análisis de regresión es minimizar el error asociado a las estimaciones del modelo. Como se señaló, el término residual es el error estimado, o falla general” (por ejemplo, YI−^YIYI−YI^). Específicamente, el objetivo es minimizar la suma de los errores al cuadrado, 22. Por lo tanto, necesitamos encontrar los valores de ^αα^ y ^ββ^ que minimicen 22.
Tenga en cuenta que para un conjunto fijo de datos {^αα^, ^αα^}, cada posible elección de valores para ^αα^ y ^ββ^ corresponde a una suma residual específica de cuadrados, Esto se puede expresar mediante la siguiente forma funcional:
S (^α, ^β) =ni=12i=( Yi−^Yi) 2=( YI−^α−^βXI) 2 (7.5) (7.5) S (α^, β^) =i=1ni2=( Yi−Yi^) 2=( YI−α^−β^XI) 2
Minimizar esta función requiere especificar estimadores para ^αα^ y ^ββ^ de tal manera que S (^α, ^β) =Z2s (α^, β^) =2 está en el valor más bajo posible. Encontrar este valor mínimo requiere el uso del cálculo, que se discutirá en el siguiente capítulo. Antes de eso, recorremos un ejemplo rápido de regresión simple