
12.3: Ejemplo de Regresión Múltiple
- Page ID
- 150246

library(psych)
describe(data.frame(ds.temp$glbcc_risk,ds.temp$ideol,
ds.temp$age))## vars n mean sd median trimmed mad min max
## ds.temp.glbcc_risk 1 2513 5.95 3.07 6 6.14 2.97 0 10
## ds.temp.ideol 2 2513 4.66 1.73 5 4.76 1.48 1 7
## ds.temp.age 3 2513 60.38 14.19 62 61.01 13.34 18 99
## range skew kurtosis se
## ds.temp.glbcc_risk 10 -0.32 -0.94 0.06
## ds.temp.ideol 6 -0.45 -0.79 0.03
## ds.temp.age 81 -0.38 -0.23 0.28library(car)
scatterplotMatrix(data.frame(ds.temp$glbcc_risk,
ds.temp$ideol,ds.temp$age),
diagonal="density")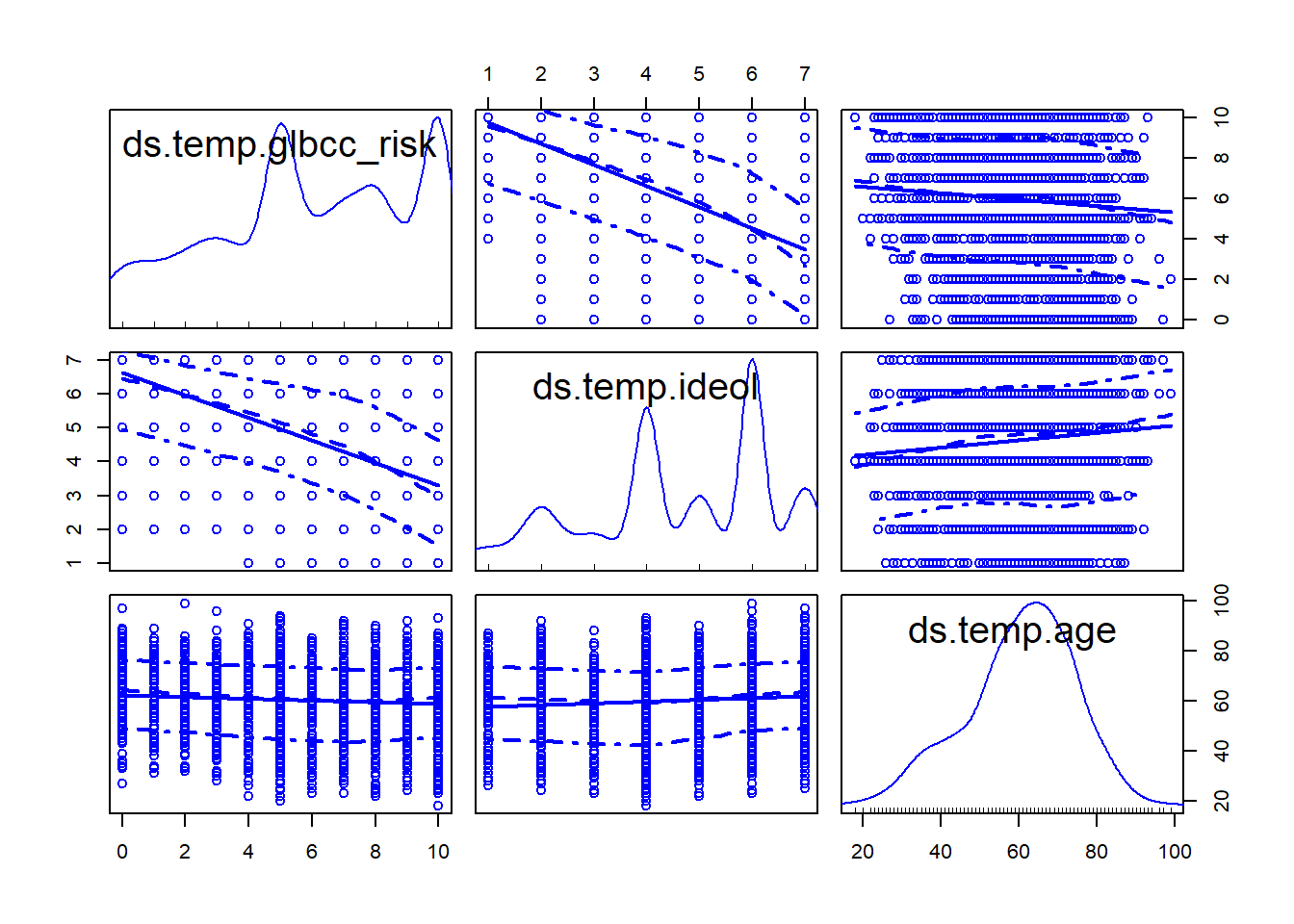
En esta sección, recorremos otro ejemplo de regresión múltiple. Primero, comenzamos con nuestros dos modelos IV.
ols1 <- lm(glbcc_risk ~ age+ideol, data=ds.temp)
summary(ols1)##
## Call:
## lm(formula = glbcc_risk ~ age + ideol, data = ds.temp)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.7913 -1.6252 0.2785 1.4674 6.6075
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 11.096064 0.244640 45.357 <0.0000000000000002 ***
## age -0.004872 0.003500 -1.392 0.164
## ideol -1.042748 0.028674 -36.366 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.479 on 2510 degrees of freedom
## Multiple R-squared: 0.3488, Adjusted R-squared: 0.3483
## F-statistic: 672.2 on 2 and 2510 DF, p-value: < 0.00000000000000022Los resultados muestran que la relación entre la edad y el riesgo percibido (glbccrsk) es negativa e insignificante. La relación entre ideología y riesgo percibido es negativa y significativa. Los coeficientes de los XX se interpretan de la misma manera que con la regresión simple, excepto que ahora estamos controlando el efecto de los otros XX eliminando su influencia en el coeficiente estimado. Por lo tanto, decimos que a medida que la ideología aumenta una unidad, las percepciones del riesgo de cambio climático (glbccrsk) disminuyen en -1.0427478, controlando por el efecto de la edad.
Como fue el caso de la regresión simple, la regresión múltiple encuentra la intercepción y pendientes que minimizan la suma de los residuales cuadrados. Con solo una IV la relación se puede representar en un plano bidimensional (una gráfica) como una línea, pero cada IV agrega otra dimensión. Dos IVs crean un plano de regresión dentro de un cubo, como se muestra en la Figura\(\PageIndex{3}\). La Figura muestra una gráfica de dispersión del riesgo percibido del cambio climático, la edad y la ideología junto con el plano de regresión. Tenga en cuenta que esta es una muestra de 200 observaciones del conjunto de datos más grande. Si tuviéramos que añadir más IVs, generaríamos un hipercubo... y aún no hemos encontrado una forma inteligente de dibujar eso.
ds200 <- ds.temp[sample(1:nrow(ds.temp), 200, replace=FALSE),]
library(scatterplot3d)
s3d <-scatterplot3d(ds200$age,
ds200$ideol,
ds200$glbcc_risk
,pch=16, highlight.3d=TRUE,
type="h", main="3D Scatterplot")
s3d$plane3d(ols1)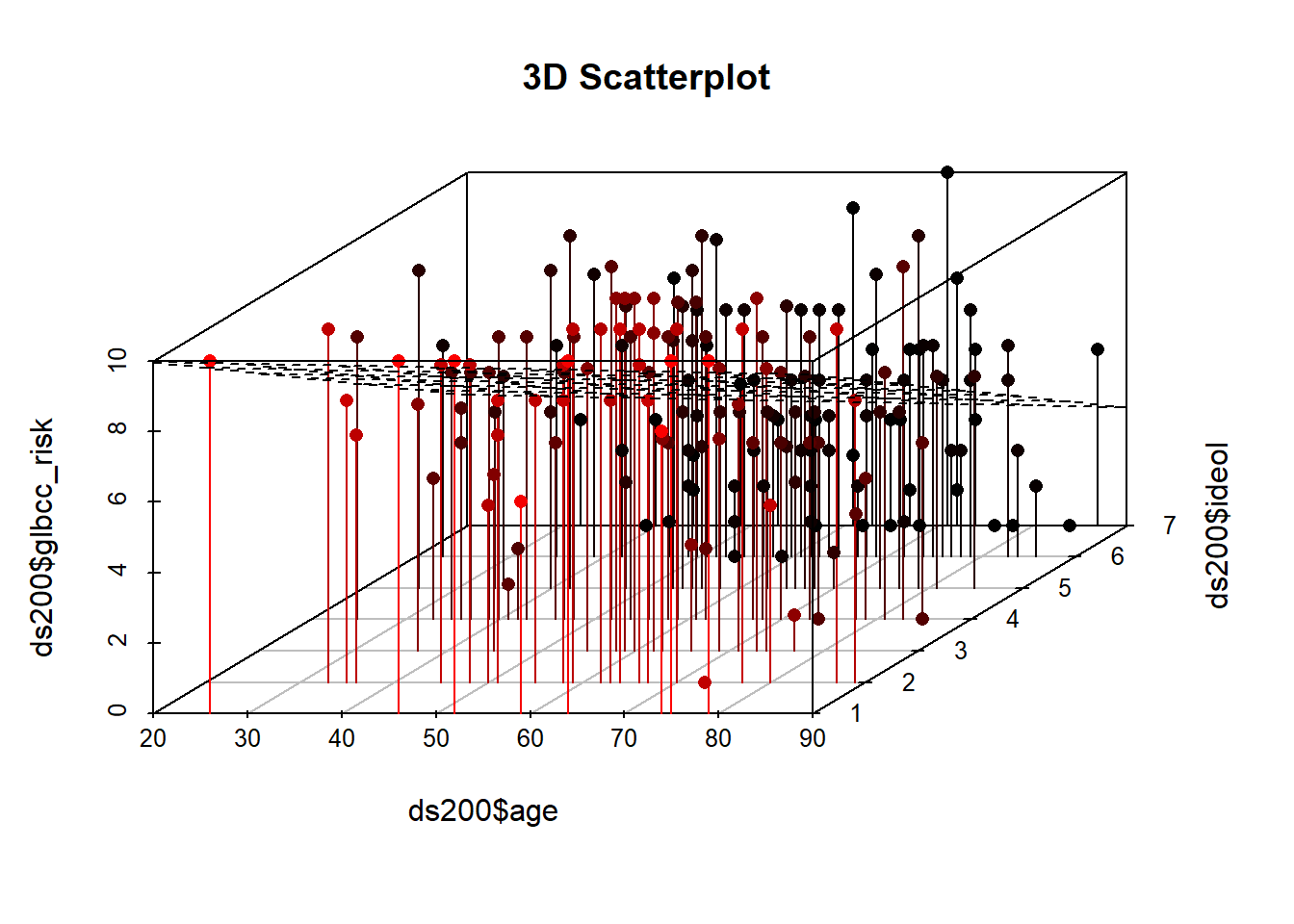
En el siguiente ejemplo se agrega educación al modelo.
ds.temp <- filter(ds) %>%
dplyr::select(glbcc_risk, age, education, income, ideol) %>%
na.omit()
ols2 <- lm(glbcc_risk ~ age + education + ideol, data = ds.temp)
summary(ols2)##
## Call:
## lm(formula = glbcc_risk ~ age + education + ideol, data = ds.temp)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.8092 -1.6355 0.2388 1.4279 6.6334
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.841669 0.308416 35.153 <0.0000000000000002 ***
## age -0.003246 0.003652 -0.889 0.374
## education 0.036775 0.028547 1.288 0.198
## ideol -1.044827 0.029829 -35.027 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.437 on 2268 degrees of freedom
## Multiple R-squared: 0.3607, Adjusted R-squared: 0.3598
## F-statistic: 426.5 on 3 and 2268 DF, p-value: < 0.00000000000000022Vemos que a medida que la educación de un encuestado aumenta una unidad en la escala educativa, el riesgo percibido parece aumentar en 0.0367752, manteniendo constantes la edad y la ideología. Sin embargo, este resultado no es significativo. En el último ejemplo, los ingresos se suman al modelo. Obsérvese que el tamaño y significancia de la educación en realidad aumenta una vez incluidos los ingresos, lo que indica que la educación sólo tiene incidencia en los riesgos percibidos del cambio climático una vez que se considera el efecto independiente del ingreso.
options(scipen = 999) #to turn off scientific notation
ols3 <- lm(glbcc_risk ~ age + education + income + ideol, data = ds.temp)
summary(ols3)##
## Call:
## lm(formula = glbcc_risk ~ age + education + income + ideol, data = ds.temp)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.7991 -1.6654 0.2246 1.4437 6.5968
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 10.9232861851 0.3092149750 35.326 < 0.0000000000000002 ***
## age -0.0044231931 0.0036688855 -1.206 0.22810
## education 0.0632823391 0.0299443094 2.113 0.03468 *
## income -0.0000026033 0.0000009021 -2.886 0.00394 **
## ideol -1.0366154295 0.0299166747 -34.650 < 0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.433 on 2267 degrees of freedom
## Multiple R-squared: 0.363, Adjusted R-squared: 0.3619
## F-statistic: 323 on 4 and 2267 DF, p-value: < 0.0000000000000002212.3.1 Pruebas de Hipótesis y TT-Tests
La lógica de las pruebas de hipótesis con regresión múltiple es una extensión directa de la regresión simple como se describe en el Capítulo 7. A continuación demostraremos cómo utilizar el error estándar de la variable ideológica para probar si la ideología influye en las percepciones del riesgo percibido del cambio climático global. Específicamente, postulamos:
H1H1: A medida que los encuestados se vuelvan más conservadores, percibirán que el cambio climático es menos riesgoso, todo lo demás igual.
Por lo tanto, βideología<0βideología<0. La hipótesis nula es que βideology=0βideology=0.
Para probar H1H1 primero necesitamos encontrar el error estándar del BB para ideología, (BJBj).
SE (Bj) =SE√rSSj (12.1) (12.1) SE (Bj) =SersSj
donde rSSJ=RSSJ= la suma residual de cuadrados de la regresión de xJxJ (ideología) sobre los otros XXs (edad, educación, ingresos) en el modelo. RssJrssJ captura toda la variación independiente en xJxJ. Tenga en cuenta que cuanto más grande sea RssJrssJ, más pequeña SE (Bj) SE (Bj) y la SE (Bj) SE (Bj) más pequeña será la estimación de BjBj.
SESE (el error estándar del modelo) es:
se=√rssn−k−1se=RSSN−k−1
Podemos usar R para encontrar el RSSRSS para ideología en nuestro modelo. Primero encontramos el SESE del modelo:
Se <- sqrt((sum(ols3$residuals^2))/(length(ds.temp$ideol)-5-1))
Se## [1] 2.43312Entonces encontramos el RSSRSS, por ideología:
ols4 <- lm(ideol ~ age + education + income, data = ds.temp)
summary(ols4)##
## Call:
## lm(formula = ideol ~ age + education + income, data = ds.temp)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.2764 -1.1441 0.2154 1.4077 3.1288
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.5945481422 0.1944108986 23.633 < 0.0000000000000002 ***
## age 0.0107541759 0.0025652107 4.192 0.0000286716948757 ***
## education -0.1562812154 0.0207596525 -7.528 0.0000000000000738 ***
## income 0.0000028680 0.0000006303 4.550 0.0000056434561990 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.707 on 2268 degrees of freedom
## Multiple R-squared: 0.034, Adjusted R-squared: 0.03272
## F-statistic: 26.6 on 3 and 2268 DF, p-value: < 0.00000000000000022RSSideol <- sum(ols4$residuals^2)
RSSideol## [1] 6611.636Finalmente, calculamos el SESE para ideología:
SEideol <- Se/sqrt(RSSideol)
SEideol## [1] 0.02992328Una vez que se conoce el SE (Bj) SE (Bj), se puede calcular la prueba tt para el coeficiente ideológico. El valor tt es la relación entre el coeficiente estimado y su error estándar.
t=BJSE (Bj) (12.2) (12.2) T=BJSE (Bj)
Esto se puede calcular usando R.
ols3$coef[5]/SEideol## ideol
## -34.64245Como vemos, el resultado es estadísticamente significativo, y por lo tanto rechazamos la hipótesis nula. También tenga en cuenta que los resultados coinciden con los de la salida R para el modelo completo, como se mostró anteriormente.