
2.2: Mira los datos
- Page ID
- 150326

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Ya probamos una forma de ver los números, y no fue útil. Veamos algunas otras formas de ver los números, usando gráficas.
Detener, tiempo de trazado (o o oh) U puede trazar esto
Vamos a convertir todos los números en puntos, luego mostrarlos en una gráfica. Tenga en cuenta, cuando hacemos esto, aún no hemos resumido nada sobre los datos. En cambio, solo miramos todos los datos en un formato visual, en lugar de mirar los números.
happiness<-rnorm(500,100,500) plot(happiness)

La figura\(\PageIndex{1}\) muestra 500 mediciones de felicidad. La gráfica tiene dos ejes. El eje x horizontal, que va de izquierda a derecha está etiquetado como “Índice”. El eje y vertical, que va hacia arriba y hacia abajo, se etiqueta como “felicidad”. Cada punto representa una medida de la felicidad de cada persona de nuestro estudio simulado. Antes de hablar de lo que podemos y no podemos ver de los datos, vale la pena mencionar que la forma en que trazar los datos hará que algunas cosas sean más fáciles de ver y otras más difíciles de ver. Entonces, ¿qué podemos ver ahora de los datos?
Hay muchos puntos por todas partes. Parece que hay 500 de ellos porque el índice va a 500. Parece que algunos puntos van tan altos como 1000-1500 y tan bajos como -1500. Parece que hay más puntos en la zona media de la parcela, algo así como repartidos alrededor de 0.
Llévate a casa: podemos ver todos los números a la vez poniéndolos en una parcela, y eso es mucho más fácil y más útil que mirar los números brutos.
Bien, entonces si estos puntos representan lo felices que son 500 personas, ¿qué podemos decir de esas personas? Primero, los puntos están en todo el lugar, por lo que diferentes personas tienen diferentes niveles de felicidad. ¿Hay alguna tendencia? ¿Hay más gente feliz que infeliz, o viceversa? Es difícil verlo en la gráfica, así que hagamos una diferente, llamada histograma
Histogramas
Hacer un histograma será nuestro primer acto de resumir oficialmente algo sobre los datos. Ya no veremos los bits individuales de datos, en cambio veremos cómo se agrupan los números. Veamos un histograma de los datos de felicidad, y luego explicarlo.
happiness<-rnorm(500,100,500) hist(happiness)

Los puntos han desaparecido, y ahora tenemos algunas barras. Cada barra es un resumen de los puntos, que representa el número de puntos (recuento de frecuencia) dentro de un rango particular de felicidad, también llamados bins. Por ejemplo, ¿cuántas personas dieron una calificación de felicidad entre 0 y 500? La quinta barra, la que está entre 0 y 500 en el eje x, te dice cuántos. Mira qué altura tiene esa barra. ¿Qué tan alto es? La altura se muestra en el eje y, lo que proporciona un recuento de frecuencia (el número de puntos o puntos de datos). Parece que alrededor de 150 personas dijeron que su felicidad estaba entre 0-500.
De manera más general, vemos que hay muchos bins en el eje x. Hemos dividido los datos en bins de 500. El bin #1 va de -2000 a -1500, el bin #2 va de -1500 a -1000, y así sucesivamente hasta el último bin. Para hacer el histograma, solo contamos el número de puntos de datos que caen dentro de cada bin, luego trazamos esos recuentos de frecuencia como una función de los bins. Voila, un histograma.
¿Qué nos ayuda a ver el histograma sobre los datos? Primero, podemos ver la forma de los datos. La forma del histograma se refiere a cómo va hacia arriba y hacia abajo. La forma nos dice dónde están los datos. Por ejemplo, cuando las barras están bajas sabemos que ahí no hay muchos datos. Cuando las barras están altas, sabemos que ahí hay más datos. Entonces, ¿dónde está la mayor parte de los datos? Parece que está mayormente en el medio dos contenedores, entre -500 y 500. También podemos ver el rango de los datos. Esto nos dice los mínimos y los máximos de los datos. La mayor parte de los datos están entre -1500 y +1500, por lo que no hay tristeza infinita o felicidad infinita en nuestro conjunto de datos.
Cuando haces un histograma puedes elegir qué tan amplia será cada barra. Por ejemplo, a continuación hay cuatro histogramas diferentes de los mismos datos de felicidad. Lo que cambia es el ancho de las papeleras.
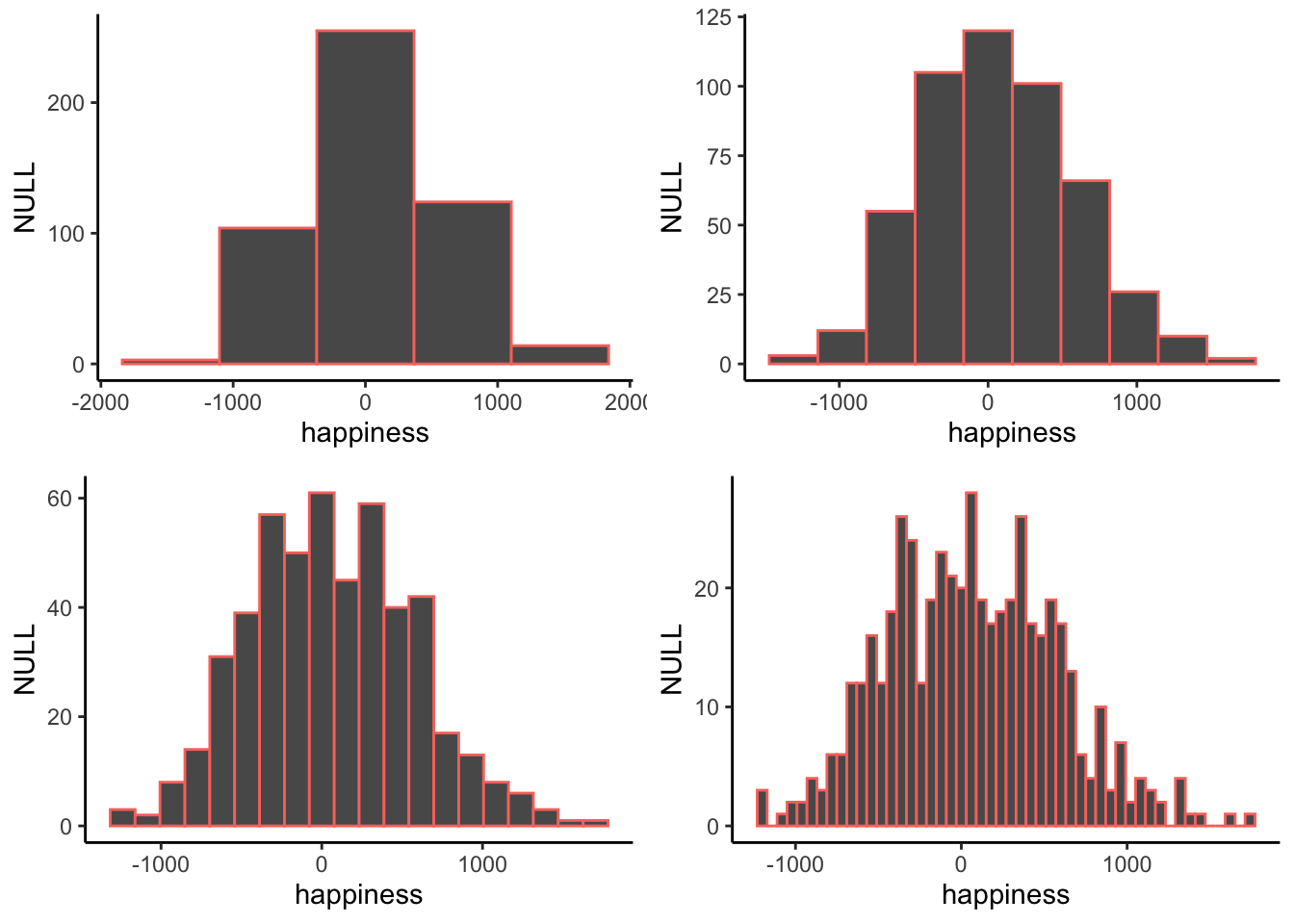
Todos los histogramas tienen aproximadamente la misma forma general: De izquierda a derecha, las barras comienzan pequeñas, luego suben, luego vuelven a ser pequeñas. Es decir, a medida que los números se acercan a cero, empiezan a ocurrir con mayor frecuencia. Vemos esta tendencia general en todos los histogramas. Pero, algunos aspectos de la tendencia se desmoronan cuando las barras se vuelven realmente estrechas. Por ejemplo, aunque las barras generalmente se vuelven más altas al pasar de -1000 a 0, hay algunas excepciones y las barras parecen fluctuar un poco. Cuando las barras son más anchas, hay menos excepciones a la tendencia general. ¿Qué tan ancho o estrecho debe ser tu histograma? Es una pregunta de Goldilocks. Hazlo perfecto para tus datos.