
7.5: Valores críticos, valores p y nivel de significancia
- Page ID
- 150783

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Un valor de probabilidad bajo arroja dudas sobre la hipótesis nula. ¿Qué tan bajo debe ser el valor de probabilidad para concluir que la hipótesis nula es falsa? Aunque claramente no hay una respuesta correcta o incorrecta a esta pregunta, es convencional concluir que la hipótesis nula es falsa si el valor de probabilidad es menor a 0.05. Investigadores más conservadores concluyen que la hipótesis nula es falsa solo si el valor de probabilidad es menor a 0.01. Cuando un investigador concluye que la hipótesis nula es falsa, se dice que el investigador rechazó la hipótesis nula. El valor de probabilidad por debajo del cual se rechaza la hipótesis nula se denomina nivel α o simplemente\(α\) (“alfa”). También se le llama el nivel de significancia. Si α no se especifica explícitamente, asuma que\(α\) = 0.05.
El nivel de significancia es un umbral que establecemos antes de recolectar datos para determinar si debemos o no rechazar la hipótesis nula. Establecimos este valor de antemano para evitar sesgarnos viendo nuestros resultados y luego determinando qué criterios debemos usar. Si nuestros datos producen valores que cumplen o superan este umbral, entonces tenemos evidencia suficiente para rechazar la hipótesis nula; si no, fallamos en rechazar el nulo (nunca “aceptamos” el nulo).
Hay dos criterios que utilizamos para evaluar si nuestros datos cumplen con los umbrales establecidos por nuestro nivel de significancia elegido, y ambos tienen que ver con nuestras discusiones de probabilidad y distribuciones. Recordemos que la probabilidad se refiere a la probabilidad de un evento, dada alguna situación o conjunto de condiciones. En las pruebas de hipótesis, esa situación es la suposición de que el valor de hipótesis nulo es el valor correcto, o que no hay efecto. El valor establecido en H0 es nuestra condición bajo la cual interpretamos nuestros resultados. Para rechazar esta suposición, y con ello rechazar la hipótesis nula, necesitamos resultados que serían muy improbables si el nulo fuera cierto. Ahora recordemos que los valores de z que caen en las colas de la distribución normal estándar representan valores poco probables. Es decir, la proporción del área bajo la curva como o más extrema que\(z\) es muy pequeña a medida que nos metemos en las colas de la distribución. Nuestro nivel de significancia corresponde al área bajo la cola que es exactamente igual a α: si usamos nuestro criterio normal de\(α\) = .05, entonces el 5% del área bajo la curva se convierte en lo que llamamos la región de rechazo (también llamada región crítica) de la distribución. Esto se ilustra en la Figura\(\PageIndex{1}\).
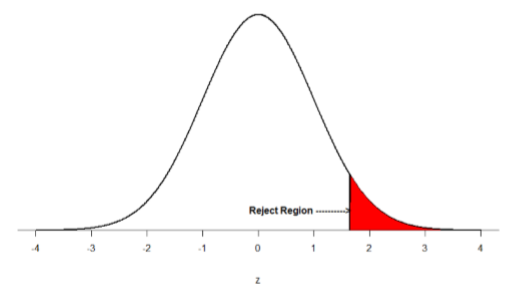
La región de rechazo sombreada nos lleva el 5% del área bajo la curva. Cualquier resultado que caiga en esa región es evidencia suficiente para rechazar la hipótesis nula.
La región de rechazo está delimitada por un\(z\) valor específico, al igual que cualquier área bajo la curva. En las pruebas de hipótesis, el valor correspondiente a una región de rechazo específica se denomina valor crítico,\(z_{crit}\) (“\(z\)-crit”) o\(z*\) (de ahí el otro nombre “región crítica”). Encontrar el valor crítico funciona exactamente igual que encontrar la puntuación z correspondiente a cualquier área bajo la curva como hicimos en la Unidad 1. Si vamos a la tabla normal, encontraremos que la puntuación z correspondiente al 5% del área bajo la curva es igual a 1.645 (\(z\)= 1.64 corresponde a 0.0405 y\(z\) = 1.65 corresponde a 0.0495, así que .05 está exactamente entre ellas) si vamos a la derecha y -1.645 si vamos a la izquierda. La dirección debe estar determinada por su hipótesis alternativa, y dibujar luego sombrear la distribución es útil para mantener la direccionalidad recta.
Supongamos, sin embargo, que queremos hacer una prueba no direccional. Tenemos que poner la región crítica en ambas colas, pero no queremos aumentar el tamaño general de la región de rechazo (por razones que veremos más adelante). Para ello, simplemente lo dividimos por la mitad para que una proporción igual del área bajo la curva caiga en la región de rechazo de cada cola. Para\(α\) = .05, esto significa que 2.5% del área está en cada cola, la cual, con base en la tabla z, corresponde a valores críticos de\(z*\) = ±1.96. Esto se muestra en la Figura\(\PageIndex{2}\).
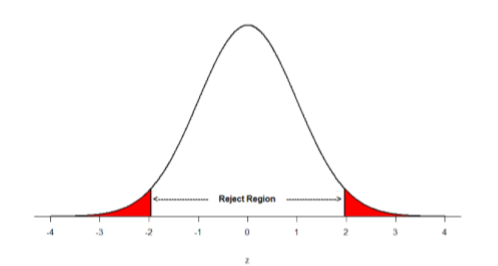
Así, cualquier\(z\) -score que caiga fuera de ±1.96 (mayor a 1.96 en valor absoluto) cae en la región de rechazo. Cuando usamos\(z\) -scores de esta manera, el valor obtenido de\(z\) (a veces llamado\(z\) -obtenido) es algo conocido como estadística de prueba, que es simplemente una estadística inferencial utilizada para probar una hipótesis nula. La fórmula para nuestra\(z\) estadística no ha cambiado:
\[z=\dfrac{\overline{\mathrm{X}}-\mu}{\bar{\sigma} / \sqrt{\mathrm{n}}} \]
Para probar formalmente nuestra hipótesis, comparamos nuestro\(z\) estadístico obtenido con nuestro\(z\) valor crítico. Si\(\mathrm{Z}_{\mathrm{obt}}>\mathrm{Z}_{\mathrm{crit}}\), eso significa que cae en la región de rechazo (para ver por qué, trazar una línea para\(z\) = 2.5 en Figura\(\PageIndex{1}\) o Figura\(\PageIndex{2}\)) y así rechazamos\(H_0\). Si\(\mathrm{Z}_{\mathrm{obt}}<\mathrm{Z}_{\mathrm{crit}}\), no lo rechazamos. Recuerde que a medida que\(z\) se hace más grande, el área correspondiente bajo la curva más allá\(z\) se hace más pequeña. Así, la proporción, o\(p\) -valor, será menor que el área para\(α\), y si el área es menor, la probabilidad se vuelve más pequeña. Específicamente, la probabilidad de obtener ese resultado, o un resultado más extremo, bajo la condición de que la hipótesis nula sea verdadera se hace menor.
El\(z\) -estadístico es muy útil cuando estamos haciendo nuestros cálculos a mano. Sin embargo, cuando usamos software de computadora, nos reportará un\(p\) -valor, que es simplemente la proporción del área bajo la curva en las colas más allá de nuestra\(z\) estadística obtenida. Podemos comparar directamente este\(p\) -valor\(α\) para probar nuestra hipótesis nula: si\(p < α\), rechazamos\(H_0\), pero si\(p > α\), fallamos en rechazar. Obsérvese también que lo contrario siempre es cierto: si utilizamos valores críticos para probar nuestra hipótesis, siempre sabremos si\(p\) es mayor o menor que\(α\). Si rechazamos, sabemos que\(p < α\) debido a que el\(z\) -estadístico obtenido cae más lejos en la cola que el\(z\) -valor crítico que corresponde a\(α\), por lo que la proporción (\(p\)-valor) para ese\(z\) -estadístico será menor. Por el contrario, si no rechazamos, sabemos que la proporción será mayor que\(α\) porque el\(z\) -estadístico no estará tan lejos en la cola. Esto se ilustra para una prueba de una cola en la Figura\(\PageIndex{3}\).
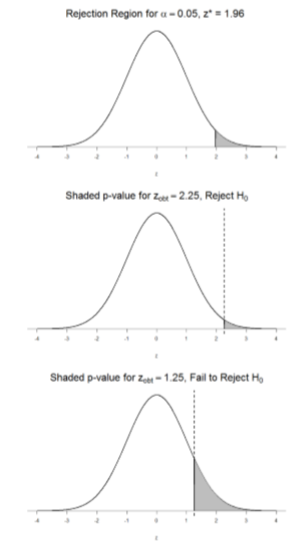
Cuando se rechaza la hipótesis nula, se dice que el efecto es estadísticamente significativo. Por ejemplo, en el estudio de caso Physicians Reacciones, el valor de probabilidad es 0.0057. Por lo tanto, el efecto de la obesidad es estadísticamente significativo y se rechaza la hipótesis nula de que la obesidad no hace diferencia. Es muy importante tener en cuenta que la significancia estadística significa sólo que se rechaza la hipótesis nula de exactamente ningún efecto; no significa que el efecto sea importante, que es lo que generalmente significa “significativo”. Cuando un efecto es significativo, puedes tener confianza en que el efecto no es exactamente cero. Encontrar que un efecto es significativo no te dice qué tan grande o importante es el efecto. No confundir la significación estadística con la significación práctica. Un pequeño efecto puede ser muy significativo si el tamaño de la muestra es lo suficientemente grande. ¿Por qué la palabra “significativo” en la frase “estadísticamente significativo” significa algo tan diferente de otros usos de la palabra? Curiosamente, esto se debe a que el significado de “significativo” en el lenguaje cotidiano ha cambiado. Resulta que cuando se desarrollaron los procedimientos para la prueba de hipótesis, algo era “significativo” si significaba algo. Así, encontrar que un efecto es estadísticamente significativo significa que el efecto es real y no por casualidad. A lo largo de los años, el significado de “significativo” cambió, lo que llevó a la posible mala interpretación.