
7.7: Película Popcorn
- Page ID
- 150754

Veamos cómo funcionan las pruebas de hipótesis en acción trabajando a través de un ejemplo. Digamos que al dueño de una sala de cine le gusta vigilar muy de cerca la cantidad de palomitas de maíz que entra en cada bolsa que se vende, así que sabe que la bolsa promedio tiene 8 tazas de palomitas de maíz y que esto varía un poco, aproximadamente media taza. Es decir, la media poblacional conocida es\(μ\) = 8.00 y la desviación estándar poblacional conocida es\(σ\) = 0.50. El dueño quiere asegurarse de que el empleado más nuevo esté llenando las bolsas correctamente, por lo que en el transcurso de una semana evalúa aleatoriamente 25 bolsas llenadas por el empleado para probar una diferencia (\(N\)= 25). No quiere que las bolsas se llenen en exceso ni se llenen por debajo, por lo que busca diferencias en ambas direcciones. Este escenario tiene toda la información que necesitamos para comenzar nuestro procedimiento de prueba de hipótesis.
Paso 1: Declarar las Hipótesis Nuestro gerente está buscando una diferencia en el peso medio de las bolsas de palomitas en comparación con la media poblacional de 8. Necesitaremos tanto una hipótesis nula como una alternativa escrita tanto matemáticamente como en palabras. Siempre empezaremos con la hipótesis nula:
\(H_0\): No hay diferencia en el peso de las bolsas de palomitas de maíz de este empleado
\(H_0\):\(\mu = 8.00\)
Observe que formulamos la hipótesis en términos del parámetro poblacional\(μ\), que en este caso sería el verdadero peso promedio de las bolsas llenadas por el nuevo empleado. Nuestra suposición de no diferencia, la hipótesis nula, es que esta media es exactamente la misma que el valor medio poblacional conocido que queremos que coincida, 8.00. Ahora hagamos la alternativa:
\(H_A\): Hay una diferencia en el peso de las bolsas de palomitas de maíz de este empleado
\(H_A\):\(μ ≠ 8.00\)
En este caso, no sabemos si las bolsas estarán demasiado llenas o no lo suficientemente llenas, así que hacemos una hipótesis alternativa de dos colas de que hay una diferencia.
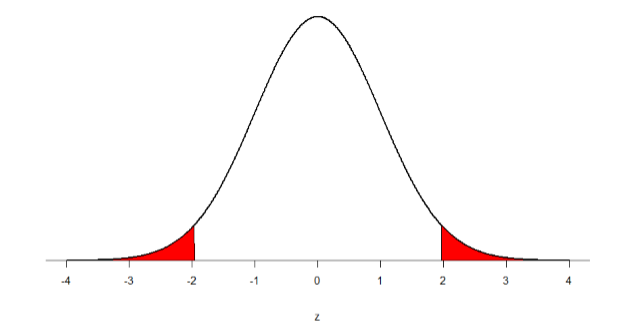
Paso 2: Encontrar los valores críticos Nuestros valores críticos se basan en dos cosas: la direccionalidad de la prueba y el nivel de significancia. Decidimos en el paso 1 que una prueba de dos colas es la direccionalidad apropiada. No se nos dio información sobre el nivel de significancia, por lo que asumimos que\(α\) = 0.05 es lo que usaremos. Como se indicó anteriormente en el capítulo, los valores críticos para una\(z\) prueba de dos colas a\(α\) = 0.05 son\(z*\) = ±1.96. Este será el criterio que usemos para poner a prueba nuestra hipótesis. Ahora podemos sacar nuestra distribución para que podamos visualizar la región de rechazo y asegurarnos de que tenga sentido.
Paso 3: Calcular el estadístico de prueba Ahora llegamos a nuestros cálculos formales. Digamos que el directivo recoge datos y encuentra que el peso promedio de las bolsas de palomitas de maíz de este empleado es de\(\overline{\mathrm{X}}\) = 7.75 tazas. Ahora podemos enchufar este valor, junto con los valores presentados en el problema original, en nuestra ecuación para\(z\):
\[z=\dfrac{7.75-8.00}{0.50 / \sqrt{25}}=\dfrac{-0.25}{0.10}=-2.50 \nonumber \]
Entonces nuestro estadístico de prueba es\(z\) = -2.50, que podemos basar en nuestra distribución de región de rechazo:
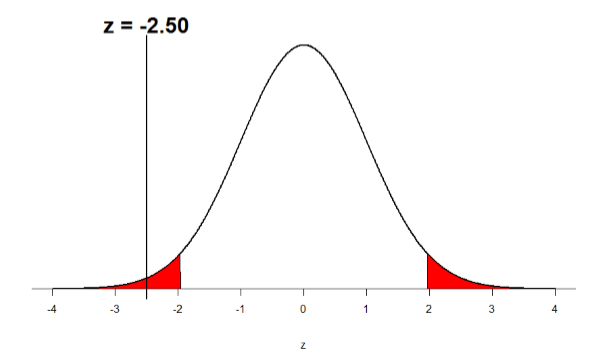
Figura\(\PageIndex{2}\): Ubicación de la estadística de prueba
Paso 4: Tomar la Decisión Mirando Figura\(\PageIndex{2}\), podemos ver que nuestra\(z\) estadística obtenida cae en la región de rechazo. También podemos compararlo directamente con nuestro valor crítico: en términos de valor absoluto, -2.50 > -1.96, por lo que rechazamos la hipótesis nula. Ahora podemos escribir nuestra conclusión:
Rechazar\(H_0\). Con base en la muestra de 25 bolsas, podemos concluir que la bolsa promedio de palomitas de maíz de este empleado es menor (\(\overline{\mathrm{X}}\)= 7.75 tazas) que el peso promedio de las bolsas de palomitas de maíz en esta sala de cine,\(z\) = 2.50,\(p\) < 0.05.
Cuando escribimos nuestra conclusión, escribimos las palabras para comunicar lo que realmente significa, pero también incluimos el tamaño promedio de la muestra que calculamos (la ubicación exacta no importa, solo en algún lugar que fluye naturalmente y tiene sentido) y el\(z\) -estadístico y\(p\) -valor. No sabemos el\(p\) -valor exacto, pero sí sabemos que porque rechazamos el nulo, debe ser menor que\(α\).