
16.3: Escalera de Poderes de Tukey
- Page ID
- 152352

Objetivos de aprendizaje
- Dar la escalera Tukey de transformaciones
- Encontrar una transformación que revele una relación lineal
- Encontrar una transformación para aproximarse a una distribución normal
Introducción
Suponemos que tenemos una colección de datos bivariados
\[(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\]
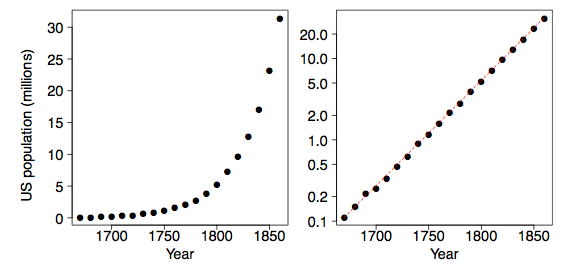
y que nos interesa la relación entre variables\(x\) y\(y\). Trazar los datos en un diagrama de dispersión es el primer paso. Como ejemplo, considere la población de Estados Unidos para los\(200\) años previos a la Guerra Civil. Por supuesto, el censo decenal comenzó en\(1790\). Estos datos se trazan de dos maneras en la Figura\(\PageIndex{1}\). Malthus predijo que el crecimiento geométrico de las poblaciones junto con el crecimiento aritmético de la producción de grano tendría resultados catastróficos. De hecho, la población estadounidense siguió una curva exponencial durante este periodo.
Escalera de transformación de Tukey
Tukey (\(1977\)) describe una forma ordenada de reexpresar variables usando una transformación de potencia. Puede estar familiarizado con la regresión polinómica (una forma de regresión múltiple) en la que el modelo lineal simple\(y = b_0 + b_1X\) se extiende con términos como\(b_2X^2 + b_3X^3 + b_4X^4\). Alternativamente, Tukey sugiere explorar relaciones simples como
\[y = b_0 + b_1X^λ\]
o
\[y^λ = b_0 + b_1X \label{eq1}\]
donde\(λ\) es un parámetro elegido para hacer que la relación sea lo más cercana posible a una línea recta. Las relaciones lineales son especiales, y si una transformación del tipo\(x^\lambda\) o y λ funciona como en la Ecuación\ ref {eq1}, entonces deberíamos considerar cambiar nuestra escala de medición para el resto del análisis estadístico.
No hay restricción en los valores de lo\(λ\) que podamos considerar. Obviamente elegir\(λ = 1\) deja los datos sin cambios. Los valores negativos de también\(λ\) son razonables. Por ejemplo, la relación
\[y = b_0 + \dfrac{b_1}{x}\]
estaría representado por\(λ = −1\). El valor no\(λ = 0\) tiene ningún valor especial, ya que\(X^0 = 1\), que es sólo una constante. Tukey (\(1977\)) sugiere que es conveniente definir simplemente la transformación cuando\(λ = 0\) ser la función logaritmo en lugar de la constante\(1\). En breve volveremos a visitar esta convención. En la siguiente tabla se dan ejemplos de la escalera Tukey de transformaciones.
| \(\lambda\) | \(-2\) | \(-1\) | \(-1/2\) | \(0\) | \(1/2\) | \(1\) | \(2\) |
| \(y\) | \(\tfrac{1}{x^2}\) | \(\tfrac{1}{x}\) | \(\tfrac{1}{\sqrt{x}}\) | \(\log x\) | \(\sqrt{x}\) | \(x\) | \(x^2\) |
Si\(x\) toma valores negativos, entonces se debe tener especial cuidado para que las transformaciones tengan sentido, si es posible. Generalmente nos limitamos a variables donde\(x > 0\) evitar estas consideraciones. Para algunas variables dependientes como el número de errores, es conveniente agregar\(1\) a\(x\) antes de aplicar la transformación.
Además, si el parámetro de transformación\(λ\) es negativo, entonces la variable transformada\(x^\lambda\) se invierte. Por ejemplo, si\(x\) está aumentando, entonces\(1/x\) está disminuyendo. Elegimos redefinir la transformación de Tukey para que sea\(-x^\lambda\) si con el\(λ < 0\) fin de preservar el orden de la variable después de la transformación. Formalmente, la transformación de Tukey se define como
\[y=\left\{\begin{matrix} x^\lambda & if & \lambda >0\\ \log x & if & \lambda =0\\ -(x^\lambda) & if & \lambda <0 \end{matrix}\right.\]
En Tabla\(\PageIndex{2}\) reproducimos Tabla\(\PageIndex{1}\) usando la definición modificada cuando\(λ < 0\).
| \(\lambda\) | \(-2\) | \(-1\) | \(-1/2\) | \(0\) | \(1/2\) | \(1\) | \(2\) |
| \(y\) | \(\tfrac{-1}{x^2}\) | \(\tfrac{-1}{x}\) | \(\tfrac{-1}{\sqrt{x}}\) | \(\log x\) | \(\sqrt{x}\) | \(x\) | \(x^2\) |
La mejor transformación para la linealidad
El objetivo es encontrar un valor\(λ\) que haga que el diagrama de dispersión sea lo más lineal posible. Para la población estadounidense, la transformación logarítmica aplicada a\(y\) hace que la relación sea casi perfectamente lineal. La línea discontinua roja en el marco derecho de la Figura\(\PageIndex{1}\) tiene una pendiente de aproximadamente\(1.35\); es decir, la población estadounidense creció a un ritmo de aproximadamente\(35\%\) por década.
La transformación logarítmica corresponde a la elección\(λ = 0\) por la convención de Tukey. En la Figura\(\PageIndex{2}\), mostramos el diagrama de dispersión de los datos de población de Estados Unidos para así\(λ = 0\) como para otras opciones de\(λ\).
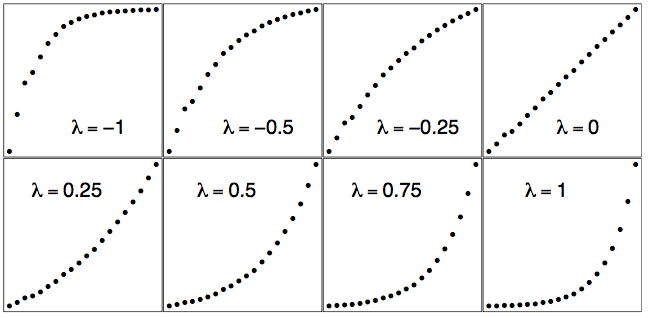
Los datos brutos se trazan en el marco inferior derecho de la Figura\(\PageIndex{2}\) cuando\(λ = 1\). El ajuste logarítmico está en el marco superior derecho cuando\(λ = 0\). Observe cómo el diagrama de dispersión se transforma suavemente de convexo a cóncavo a medida que\(λ\) aumenta. Así intuitivamente hay una mejor opción única de\(λ\) corresponder a la gráfica “más lineal”.
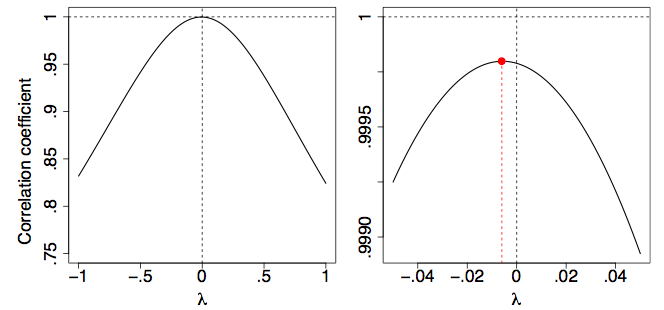
Una manera de hacer que esta elección sea objetivo es utilizar una función objetiva para este propósito. Un enfoque podría ser ajustar una línea recta a los puntos transformados e intentar minimizar los residuos. Sin embargo, un enfoque más fácil se basa en el hecho de que el coeficiente de correlación\(r\),, es una medida de la linealidad de un diagrama de dispersión. En particular, si los puntos caen en línea recta entonces su correlación será\(r = 1\). (No necesitamos preocuparnos por el caso cuando\(r = −1\) desde que hemos definido la variable transformada de Tukey\(x_\lambda\) para que esté correlacionada positivamente consigo\(x\) misma).
En la Figura\(\PageIndex{3}\), se grafica el coeficiente de correlación del diagrama\((x,y_\lambda )\) de dispersión en función de\(λ\). Es claro que la transformación logarítmica (\(λ = 0\)) es casi óptima por este criterio.
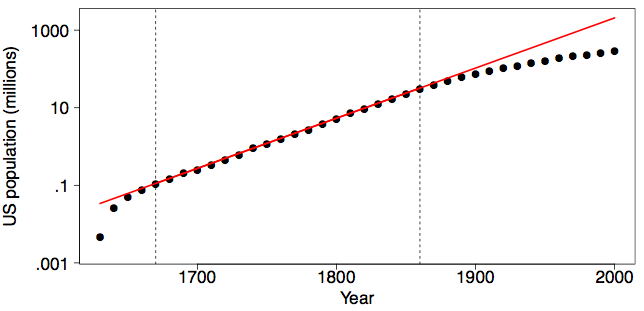
¿Sigue la población estadounidense en el mismo patrón de crecimiento exponencial? En la Figura\(\PageIndex{4}\), mostramos la población estadounidense desde\(1630\) hasta\(2000\) usando la transformación y el ajuste utilizados en el marco derecho de la Figura\(\PageIndex{1}\). Afortunadamente, el crecimiento exponencial (o al menos su tasa) no se sustentó en el siglo XX. Si lo hubiera hecho, la población estadounidense en el año\(2000\) habría superado los\(2\) mil millones (\(2.07\)para ser exactos), más grande que la población de China.
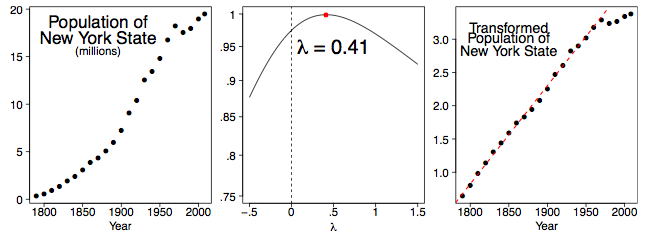
También podemos examinar las cifras de población censales decenales de estados individuales. En Figura\(\PageIndex{5}\), mostramos los datos de población para el estado de Nueva York desde\(1790\) hasta\(2000\), junto con una estimación de la población en\(2008\). Claramente algo inusual sucedió a partir de\(1970\). (Esto inició el período de migración masiva hacia Occidente y Sur a medida que las industrias del cinturón de óxido comenzaron a cerrar). Así, calculamos el mejor\(λ\) valor usando los datos de\(1790\) -\(1960\) en el marco medio de la Figura\(\PageIndex{5}\). El marco derecho muestra los datos transformados, junto con el ajuste lineal para el\(1790-1960\) periodo. El valor de no\(λ = 0.41\) es obvio y uno podría razonablemente optar\(λ = 0.50\) por usar por razones prácticas.
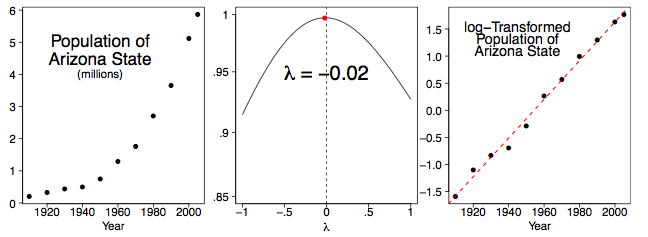
Si nos fijamos en uno de los estados más jóvenes de Occidente, el panorama es diferente. Arizona ha atraído a muchos jubilados e inmigrantes. La figura\(\PageIndex{6}\) resume nuestros hallazgos. En efecto, el crecimiento de la población en Arizona es logarítmico, y parece ser todavía logarítmico a través de\(2005\).
Reducción de sesgo
Muchos métodos estadísticos como\(t\) las pruebas y el análisis de varianza asumen distribuciones normales. Si bien estos métodos son relativamente robustos ante las violaciones de la normalidad, transformar las distribuciones para reducir el sesgo puede aumentar notablemente su poder.
A modo de ejemplo, los datos del estudio de caso “Estereogramas” son muy sesgados. Una prueba t de la diferencia entre las dos condiciones utilizando los datos brutos da como resultado un valor p de\(0.056\), un valor no convencionalmente considerado significativo. Sin embargo, después de una transformación logarítmica (\(λ = 0\)) que reduce mucho el sesgo, el\(p\) valor es el\(0.023\) que convencionalmente se considera significativo.
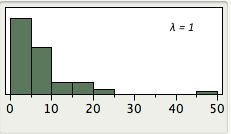
La demostración en la Figura\(\PageIndex{7}\) muestra distribuciones de los datos del estudio de caso Estereogramas transformados con diversos valores de\(λ\). La disminución\(λ\) hace que la distribución sea menos sesgada positivamente. Ten en cuenta que\(λ = 1\) son los datos brutos. Observe que hay un ligero sesgo positivo para\(λ = 0\) pero mucho menos sesgo que el encontrado en los datos brutos (\(λ = 1\)). Los valores por debajo de 0 dan como resultado un sesgo negativo.
Referencias
Tukey, J. W. (1977). Análisis Exploratorio de Datos. Addison-Wesley, Reading, MA.