
3.8: Interior R
- Page ID
- 150017
Los vectores en modos y factores numéricos, lógicos o de carácter son suficientes para representar datos simples. Sin embargo, si los datos son estructurados y/o variables, frecuentemente se necesitan objetos R más complicados: matrices, listas y marcos de datos.
Matrices
Matrix es una forma popular de presentar datos tabulares. Hay dos cosas importantes que hay que saber sobre ellos en R. En primer lugar, pueden tener diversas dimensiones. Y en segundo lugar, no hay, de hecho, matrices verdaderas en R.
Comenzamos con la segunda declaración. Matriz en R es solo un tipo especializado de vector con atributos adicionales que ayudan a identificar valores como pertenecientes a filas y columnas. Aquí creamos la\(2\times2\) matriz simple a partir del vector numérico:
Código\(\PageIndex{1}\) (R):
Como revela el comando str (), los objetos m y ma son muy similares. Lo que es diferente es la forma en que se presentan en la pantalla.
La igualdad de matrices y vectores es aún más clara en el siguiente ejemplo:
Código\(\PageIndex{2}\) (R):
En parece un truco pero la razón subyacente es simple. Asignamos el atributo dim (“dimensions”, size) al vector mb y declaramos el valor del atributo como c (2, 2), como 2 filas y 2 columnas.
¿Por qué las matrices mb y ma son diferentes?
Otra forma popular de crear matrices es vincular vectores como columnas o filas con cbind () y rbind (). El comando relacionado t () se utiliza para transponer la matriz, girarla en sentido horario por\(90^\circ\).
Para indexar una matriz, use corchetes:
Código\(\PageIndex{3}\) (R):
La regla aquí es simple: entre corchetes, primero va primera dimensión (filas), y segundo a columnas. Entonces para indexar, usa matrix [filas, columnas]. La misma regla es aplicable a los marcos de datos (ver abajo).
El índice vacío es equivalente a todos los valores:
Código\(\PageIndex{4}\) (R):
Las formas comunes de indexar la matriz no permiten seleccionar la selección diagonal, y mucho menos en forma de L (“movimiento de caballero”) o escasa. Sin embargo, R satisfará incluso estas necesidades exóticas. Seleccionemos los valores diagonales de ma:
Código\(\PageIndex{5}\) (R):
(Aquí mi es una matriz de indexación. Para indexar objeto bidimensional, debe tener dos columnas. Cada fila de la matriz de indexación describe la posición del elemento a seleccionar. Por ejemplo, la segunda fila de mi es equivalente a [2, 2]. Como alternativa, existe el comando diag () pero solo funciona para diagonales.)
Mucho menos exótico es la indexación con matriz lógica. Ya hicimos indexación similar en el ejemplo de imputación de datos faltantes. Así es como funciona en matrices:
Código\(\PageIndex{6}\) (R):
Dado que las matrices son vectores, todos los elementos de la matriz deben ser del mismo modo: ya sea numérico, o carácter, o lógico. Si cambiamos el modo de un elemento, el resto de ellos cambiará automáticamente:
Código\(\PageIndex{7}\) (R):
Las matrices bidimensionales son las más populares, pero también hay matrices multidimensionales:
Código\(\PageIndex{8}\) (R):
(En lugar de attr (..., “dim”) usamos dim análogo (...) comando.)
m3 es una matriz, “matriz 3D”. No se puede mostrar como una sola tabla, y R la devuelve como una serie de tablas. Hay arrays de mayor dimensionalidad; por ejemplo, el bui db">titatic es el array 4D. Para indexar matrices, R requiere los mismos corchetes pero con tres o más elementos dentro.
Listas
La lista es esencialmente la colección de cualquier cosa:
Código\(\PageIndex{9}\) (R):
Aquí vemos que la lista es una cosa compuesta. Los vectores y matrices solo pueden incluir elementos del mismo tipo mientras que las listas acomodan cualquier cosa, incluyendo otras listas.
Los elementos de la lista podrían tener nombres:
Código\(\PageIndex{10}\) (R):
La función Nombres no es exclusiva de las listas, ya que muchos otros tipos de objetos R también podrían tener elementos con nombre. Los valores dentro de los vectores, y las filas y columnas de matrices pueden tener sus propios nombres únicos:
Código\(\PageIndex{11}\) (R):
>
>
Rick Amanda Peter Alex Kathryn Ben George
69 68 93 87 59 82 72
>
col1 col2
fila1 1 2
fila2 3 4
Para eliminar nombres, utilice:
Código\(\PageIndex{12}\) (R):
Vamos ahora a indexar una lista. Como recuerdas, extraemos elementos de vectores con corchetes:
Código\(\PageIndex{13}\) (R):
Para matrices/arrays, utilizamos varios argumentos, en el caso de los bidimensionales son números de fila y columna:
Código\(\PageIndex{14}\) (R):
Ahora, hay al menos tres formas de obtener elementos de las listas. Primero, podemos usar los mismos corchetes:
Código\(\PageIndex{15}\) (R):
Aquí el objeto resultante es también una lista. Segundo, podemos usar corchetes dobles:
Código\(\PageIndex{16}\) (R):
Después de esta operación obtenemos el contenido de la sublista, objeto del tipo que tenía antes de unirse a la lista. El primer objeto en este ejemplo es un vector de caracteres, mientras que el quinto es en sí mismo una lista.
Metafóricamente, los corchetes sacan el huevo de la canasta mientras que los corchetes dobles también lo descascaran.
Tercero, podemos crear nombres para los elementos de la lista y luego llamarlos con signo de dólar:
Código\(\PageIndex{17}\) (R):
El signo de dólar es un azúcar sintáctico que permite escribir l $ primero en lugar de l más complicado. Esa última pieza R podría considerarse como una cuarta forma de indexar la lista, con vector de caracteres de nombres.
Consideremos ahora el siguiente ejemplo:
Código\(\PageIndex{18}\) (R):
Esto sucede porque el signo de dólar (y el valor predeterminado [[too) permiten una coincidencia parcial de manera similar a los argumentos de función. Esto ahorra tiempo de escritura pero podría ser potencialmente peligroso.
Con un signo de dólar o vector de caracteres, el objeto que obtenemos por indexación conserva su tipo original, al igual que con doble corchete. Tenga en cuenta que la indexación con signo de dólar sólo funciona en listas. Si tiene que indexar otros objetos con elementos nombrados, use corchetes con vectores de caracteres:
Código\(\PageIndex{19}\) (R):
> nombres (w) <- c (“Rick”, “Amanda”, “Peter”, “Alex”, “Kathryn”,
+ “Ben”, “George”)
>
Jenny
68
Las listas son muy importantes de aprender porque muchas funciones en R almacenan su salida como listas:
Código\(\PageIndex{20}\) (R):
Por lo tanto, si queremos extraer alguna pieza de la salida (como valor p, ver más en los capítulos siguientes), necesitamos usar los principios de indexación de listas de lo anterior:
Código\(\PageIndex{21}\) (R):
Marcos de datos
Ahora pasemos al tipo de representación de datos más importante, los marcos de datos. Tienen el parecido más cercano con las hojas de cálculo y su tipo, y se utilizan más comúnmente en R. El marco de datos es un tipo “híbrido”, “quimérico” de objetos R, lista unidimensional de vectores de la misma longitud. En otras palabras, el marco de datos es una lista de vectores-columnas\(^{[1]}\).
Cada columna del marco de datos debe contener datos del mismo tipo (como en vectores), pero las columnas mismas pueden ser de diferentes tipos (como en listas). Vamos a crear un marco de datos a partir de nuestros vectores existentes:
Código\(\PageIndex{22}\) (R):
(No era absolutamente necesario ingresar row.names () ya que nuestro objeto w aún podría retener nombres y ellos, por regla, se convertirán en nombres de fila de todo el marco de datos.)
Este marco de datos representa datos en forma breve, con muchas columnas-características. La forma larga de los mismos datos podría, por ejemplo, verse así:
Rick peso 69
Rick altura 174.0
Rick talla L
Rick sexo masculino
Amanda peso 68
...
En forma larga, las entidades se mezclan en una columna, mientras que la otra columna especifica id de característica Esto es realmente útil cuando finalmente llegamos al análisis de datos bidimensionales.
Los comandos fila.names () o rownames () especifican nombres de filas de marcos de datos (objetos). Para columnas de marco de datos (variables), use names () o colnames ().
Alternativamente, especialmente si los objetos w, x, m.o o sex.f están ausentes por alguna razón del espacio de trabajo, puede escribir:
Código\(\PageIndex{23}\) (R):
... y luego verificar inmediatamente la estructura:
Código\(\PageIndex{24}\) (R):
Dado que el marco de datos es de hecho una lista, podemos aplicarlo con éxito todos los métodos de indexación para listas. Más que eso, los marcos de datos disponibles para la indexación también como matrices bidimensionales:
Código\(\PageIndex{25}\) (R):
Para estar absolutamente seguro de que cualquiera de estos dos métodos da la misma salida, ejecute:
Código\(\PageIndex{26}\) (R):
Para seleccionar varias columnas (todos estos métodos dan los mismos resultados):
Código\(\PageIndex{27}\) (R):
(Tres de estos métodos funcionan también para estas filas de marcos de datos. Pruébalos todos y encuentra cuáles no son aplicables. Tenga en cuenta también que la selección negativa funciona solo para vectores numéricos; para usar varios valores negativos, escriba algo así como d [, -c (2:4)]. Piensa por qué el colon no es suficiente y necesitas c () aquí.)
Entre todas estas formas, la más popular es el signo de dólar y los corchetes (Figura\(\PageIndex{1}\)). Si bien primero es más corto, el segundo es más universal.
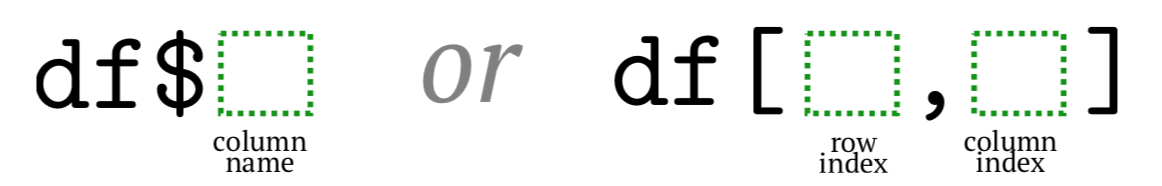
La selección por índices de columna es fácil y ahorra espacio pero requiere recordar estos números. Aquí podría ayudar el comando Str () (tenga en cuenta la mayúscula) que reemplaza los signos de dólar con números de columna (y también indica con estrella* firmar la presencia de NA, además muestra los nombres de fila si no son predeterminados) :( ver Código\(\PageIndex{24}\) (R):)
'data.frame': 7 obs. de 4 variables:
1 peso: int 69 68 93 87 59 82 72
2 altura: num 174 162 188 192 165...
3 tamaño: ORD.Factor w/ 5 niveles “S"<"M"<"L"<"XL"<..: 3 1 4
4 sexo: Factor w/ 2 niveles “femenino”, "masculino”: 2 1 2 2 1 2
fila.nombres [1:7] “Rick” “Amanda” “Peter” “Alex” “Kathryn”...
Ahora, ¿cómo hacer un subconjunto, seleccionar varios objetos (filas) que tienen características particulares? Una forma es a través de vectores lógicos. Imagina que solo somos interesantes en los valores obtenidos de las hembras:
Código\(\PageIndex{28}\) (R):
(Para seleccionar solo filas, usamos la expresión lógica d$sex==female antes de la coma).
Por sí misma, la expresión anterior devuelve un vector lógico:
Código\(\PageIndex{29}\) (R):
Es por ello que R seleccionó solo las filas que corresponden a TRUE: 2ª y 5ª filas. El resultado es el mismo que:
Código\(\PageIndex{30}\) (R):
Las expresiones lógicas se pueden usar para seleccionar filas y/o columnas completas:
Código\(\PageIndex{31}\) (R):
También es posible aplicar expresiones lógicas más complicadas:
Código\(\PageIndex{32}\) (R):
(El segundo ejemplo muestra cómo comparar con varios valores de caracteres a la vez.)
Si el proceso de selección con corchete, signo de dólar y coma parece demasiado complicado, hay otra manera, con el comando subset ():
Código\(\PageIndex{33}\) (R):
No obstante, la “selección clásica” con [es preferible (ver la explicación más detallada en? subconjunto).
La selección no solo extrae la parte del marco de datos, también permite reemplazar los valores existentes:
Código\(\PageIndex{34}\) (R):
(Ahora el peso está en libras.)
El emparejamiento parcial no funciona con el reemplazo, pero hay otro efecto interesante:
Código\(\PageIndex{35}\) (R):
(Un poco misterioso, ¿no? No obstante, las reglas son simples. Como es habitual, la expresión funciona de derecha a izquierda. Cuando llamamos a d.new$he a la derecha, el emparejamiento parcial independiente lo sustituyó por d.new$height y convertimos centímetros en pies. Entonces comienza el reemplazo. No entiende la coincidencia parcial y por lo tanto d.new$he a la izquierda devuelve NULL. En ese caso, la nueva columna (variable) se crea silenciosamente. Esto se debe a que la suscripción con $ devuelve NULL si se desconoce el subíndice, creando un método poderoso para agregar columnas al marco de datos existente).
Otro ejemplo de “magia de marco de datos” es el reciclaje. El marco de datos acumula objetos más cortos si se ajustan uniformemente al marco de datos después de repetirse varias veces:
Código\(\PageIndex{36}\) (R):
La siguiente tabla (Tabla\(\PageIndex{1}\)) proporciona un resumen de R subscripting con “[”:
| subíndice | efecto numérico positivo |
| vector | selecciona elementos con esos índices numéricos negativos |
| vector | selecciona todos los caracteres menos esos índices |
| vector | selecciona elementos con esos nombres (o dimnames) lógicos |
| vector | selecciona los elementos VERDADERO (y NA) |
| faltante | selecciona todos |
\(\PageIndex{1}\)Suscripción de Mesa con “[”.
El comando sort () no funciona para los marcos de datos. Para ordenar valores en un marco de datos d, diciendo, primero con sexo y luego con altura, tenemos que usar una operación más complicada:
Código\(\PageIndex{37}\) (R):
El comando order () crea un vector numérico, no lógico, con el orden futuro de las filas:
Código\(\PageIndex{38}\) (R):
Use order () para organizar las columnas de la matriz d en orden alfabético.
Descripción general de los tipos y modos de datos
Esta tabla simple (Tabla\(\PageIndex{2}\)) muestra los cuatro objetos R básicos:
| lineal | rectangular | |
| todos del mismo tipo | vector | matriz |
| tipo mixto | lista | marco de datos |
Tabla Ojects\(\PageIndex{2}\) básicos.
(La mayoría, pero no todos, los vectores también son atómicos, verifíquelo con is.atomic ().)
Debes conocer el tipo (matriz, marco de datos etc.) y modo (numérico, carácter etc.) del objeto con el que trabajas. Command str () es especialmente bueno para eso.
Si algún procedimiento quiere objeto de algún modo o tipo específico, suele ser fácil convertirlo en él con as. <something>() comando.
A veces, no necesitas en absoluto la conversión. Por ejemplo, las matrices ya son vectores, y todos los marcos de datos ya son listas (¡pero lo contrario no es correcto!). En la página siguiente, hay una tabla (Tabla\(\PageIndex{3}\)) que resume R tipos de datos internos y enumera sus características más importantes.
| Tipo y modo de datos | ¿Qué es? | ¿Cómo hacer un subconjunto? | ¿Cómo convertir? |
| Vector: numérico, carácter o lógico | Secuencia de números, cadenas de caracteres o VERDADO/FALSO. Elaborado con c (), operador de colon:, scan (), rep (), seq () etc. | Con números como vector [1] .Con nombres (si se nombra) como vector ["Nombre"] .Con expresión lógica como vector [vector > 3]. | matrix (), rbind (), cbind (), t () a matrix; modos de conversión como.numeric () y as.character () |
| Vector: factor | Forma de codificación de vectores. Tiene valores y niveles (códigos), y a veces también nombres. | Al igual que vector. Los factores también podrían ser re-nivelados u ordenados con factor (). | c () al vector numérico, las gotas () eliminan los niveles no utilizados |
| Matrix | Vector con dos dimensiones. Todos los elementos deben ser del mismo modo. Hecho con matriz (), cbind () etc. | matriz [2, 3] es una celda; matriz [2:3,] o matriz [matriz [, 1] > 3,] filas; matriz [, 3] columna | Matriz es un vector; c () o dim (...) <- NULL elimina cotas |
| Lista | Recogida de cualquier cosa. Podría ser anidado (jerárquico). Hecho con lista (). La mayoría de los resultados estadísticos son listas. | list [2] o (si se nombra) list ["Name"] es elemento; list o list$name contenido del elemento | unlist () a vector, data.frame () solo si todos los elementos tienen la misma longitud |
| Marco de datos | Lista nombrada de cualquier cosa de la misma longitud pero (posiblemente) modos diferentes. Los datos pueden ser cortos (los ids son columnas) y/o largos (los ids son filas). Hecho con read.table (), data.frame () etc. | Como matriz: df [2, 3] (con números) o df [, “Nombre"] (con nombres) o df [df [, 1] > 3,] (lógico) .Lista similar: df [1] o df$nombre.También es posible: subconjunto (df, Nombre > 3) | El marco de datos es una lista; matrix () se convierte en matriz (los modos se unificarán); t () transpone y convierte a matriz |
Tabla\(\PageIndex{3}\) Descripción general de los tipos de datos internos R más importantes y formas de trabajar con ellos.
Referencias
1. De hecho, las columnas de marcos de datos pueden ser también matrices u otros marcos de datos, pero esta característica rara vez es útil.