
6.1: Análisis de Correlación
- Page ID
- 150165

Para comenzar con las relaciones, primero se necesita encontrar una correlación, por ejemplo, medir la extensión y el signo de la relación, y probar si esto es estadísticamente confiable.
Obsérvese que la correlación no refleja la naturaleza de la relación (Figura\(\PageIndex{1}\)). Si encontramos una correlación significativa entre variables, esto podría significar que A depende de B, B depende de A, A y B dependen entre sí, o A y B dependen de una tercera variable C pero no tienen relación entre sí. Un ejemplo famoso es la correlación entre la venta de helados y los incendios en el hogar. Sería extraño sugerir que comer helado hace que la gente inicie incendios, o que experimentar incendios haga que la gente compre helado. De hecho, ambos parámetros dependen de la temperatura del aire\(^{[1]}\).

Los números por sí solos podrían ser engañosos, así que hay una regla simple: trazarlo primero.
Trazarlo primero
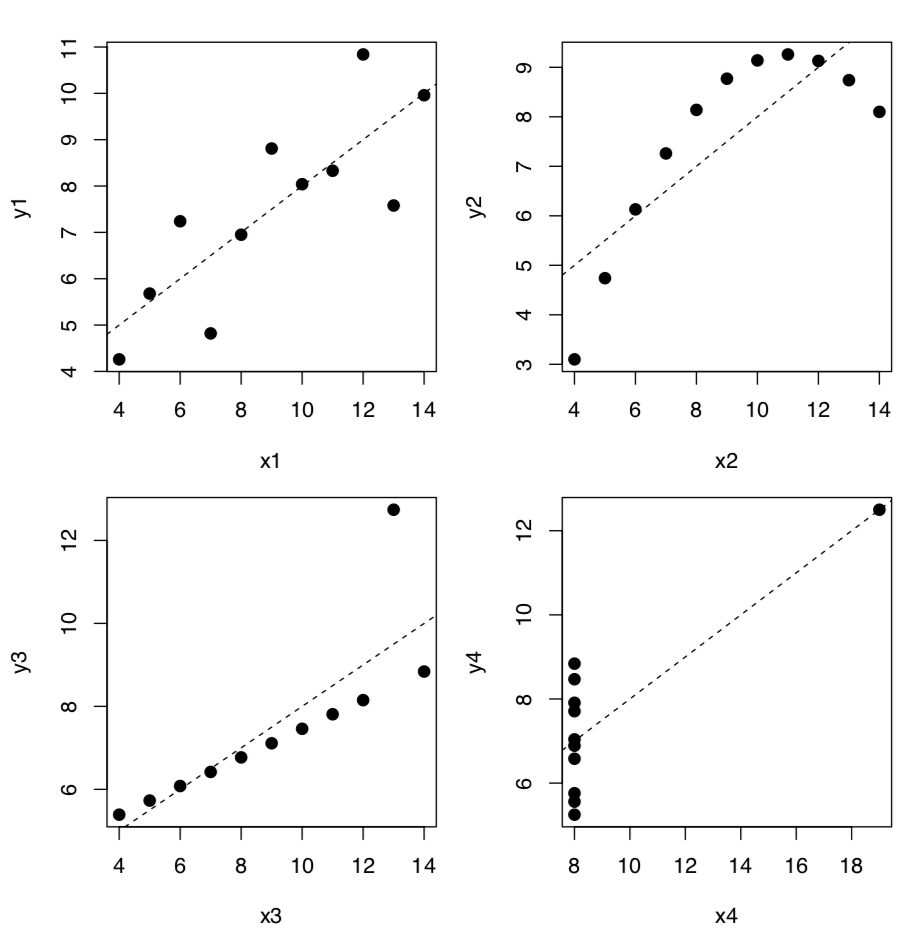
El ejemplo más llamativo de relaciones donde los números por sí solos hacen para proporcionar una respuesta confiable, es el cuarteto de Anscombe, cuatro conjuntos de dos variables que tienen medias y desviaciones estándar casi idénticas:
Código\(\PageIndex{1}\) (R):
(Data anscombe está incrustado en R. Para compactar entrada y salida, se utilizaron varios trucos. Por favor encuéntralos tú mismo.)
Los coeficientes del modelo lineal (ver abajo) también son bastante similares pero si trazamos estos datos, la imagen (Figura\(\PageIndex{2}\)) es radicalmente diferente de lo que se refleja en números:
Código\(\PageIndex{2}\) (R):
(Para fines estéticos, ponemos las cuatro parcelas en una misma figura. Tenga en cuenta el operador for que produce ciclo repitiendo una secuencia de comandos cuatro veces. Para saber más, ¿revisa?” para”.)
Al crédito de los métodos numéricos no paramétricos y/o robustos, no son tan fáciles de engañar:
Código\(\PageIndex{3}\) (R):
Esto es correcto para adivinar que las gráficas de caja también deben mostrar la diferencia. Por favor, trata de tramarlos tú mismo.
Correlación
Para medir la extensión y el signo de la relación lineal, necesitamos calcular el coeficiente de correlación. El valor absoluto del coeficiente de correlación varía de 0 a 1. Cero significa que los valores de una variable no están conectados con los valores de la otra variable. Un coeficiente de correlación de\(1\) o\(-1\) es una evidencia de una relación lineal entre dos variables. Un valor positivo de medias la correlación es positiva (cuanto mayor sea el valor de una variable, mayor será el valor de la otra), mientras que los valores negativos significan que la correlación es negativa (cuanto mayor sea el valor de una, menor de la otra).
Es fácil calcular el coeficiente de correlación en R:
Código\(\PageIndex{4}\) (R):
(Por defecto, R calcula el coeficiente de correlación paramétrico de Pearson\(r\).)
En el caso más simple, se le dan dos argumentos (vectores de igual longitud). También se puede llamar con un argumento si se usa una matriz o un marco de datos. En este caso, la función cor () calcula una matriz de correlación, compuesta por coeficientes de correlación entre todos los pares de columnas de datos.
Código\(\PageIndex{5}\) (R):
Como correlación es de hecho el tamaño del efecto de la covarianza, variación conjunta de dos variables, para calcularla manualmente, se necesita conocer varianzas individuales y varianza de la diferencia entre variables:
Código\(\PageIndex{6}\) (R):
Otra forma es usar la función cov () que calcula la covarianza directamente:
Código\(\PageIndex{7}\) (R):
Para interpretar los valores del coeficiente de correlación, podemos usar las funciones symnum () o Topm () (ver abajo), o Mag () junto con apply ():
Código\(\PageIndex{8}\) (R):
Si los números de observaciones en las columnas son desiguales (algunas columnas tienen datos faltantes), el uso del parámetro se vuelve importante. Por defecto es todo lo que devuelve NA siempre que falten valores en un conjunto de datos. Si el uso del parámetro se establece en completo.obs, las observaciones con datos faltantes se excluyen automáticamente. En ocasiones, los valores de datos faltantes están tan dispersos que completo.obs no dejará mucho de ellos. En ese último caso, use parwise.complete.obs que elimina los valores faltantes par por par.
Los coeficientes de correlación paramétrica de Pearson fallan característicamente con los datos de Anscombe:
Código\(\PageIndex{9}\) (R):
Para superar el problema, se puede usar el coeficiente de correlación no paramétrico de Spearman\(\rho\) (“rho” o coeficiente de correlación de rango) que se usa con mayor frecuencia:
Código\(\PageIndex{10}\) (R):
(¡La correlación de Spearman es definitivamente más robusta!)
El tercer tipo de coeficiente de correlación en R es no paramétrico de Kendall\(\tau\) (“tau”):
Código\(\PageIndex{11}\) (R):
A menudo se utiliza para medir la asociación entre dos variables clasificadas o binarias, es decir, como alternativa a los tamaños de efecto de la asociación en tablas de contingencia.
¿Cómo verificar si la correlación es estadísticamente significativa? Como hipótesis nula, podríamos aceptar que el coeficiente de correlación es igual a cero (sin correlación). Si se rechaza el nulo, entonces la correlación es significativa:
Código\(\PageIndex{12}\) (R):
La lógica de cor.test () es la misma que en las pruebas anteriores (Cuadro 5.1.1, Figura 5.1.1). En términos de valor p:
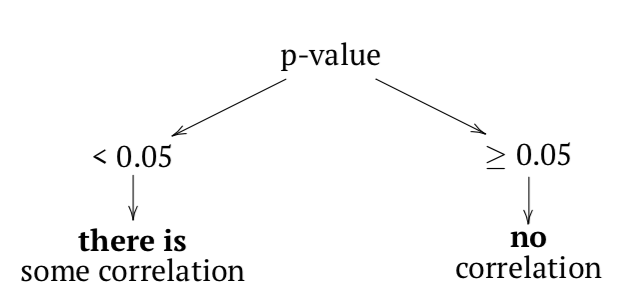
La probabilidad de obtener el estadístico de prueba (coeficiente de correlación), dado el supuesto inicial de correlación cero entre los datos es muy baja, aproximadamente 0.3%. Rechazaríamos H\(_0\) y por lo tanto aceptaríamos una hipótesis alternativa de que la correlación entre variables está presente. Tenga en cuenta el intervalo de confianza, indica aquí que el valor verdadero del coeficiente se encuentra entre 0.2 y 0.7. con 95% de probabilidad.
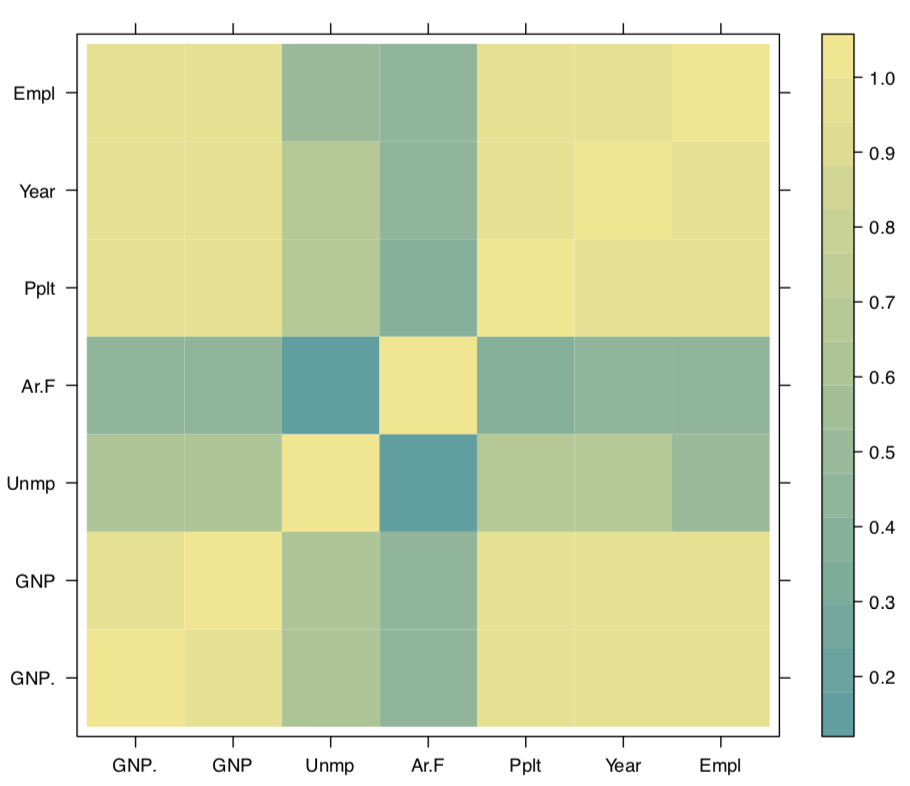
No siempre es fácil leer la tabla de correlación grande, como en el siguiente ejemplo de datos macroeconómicos longley. Afortunadamente, hay varias soluciones alternativas, por ejemplo, la función symnum () que reemplaza los números con letras o símbolos de acuerdo a su valor:
Código\(\PageIndex{13}\) (R):
La segunda forma es representar la matriz de correlación con una gráfica. Por ejemplo, podemos usar el mapa de calor: dividir todo de\(-1\) a\(+1\) en intervalos iguales, asignar el color para cada intervalo y mostrar estos colores (Figura\(\PageIndex{3}\)):
Código\(\PageIndex{14}\) (R):
(Acortamos aquí los nombres largos con el comando abbreviate ().)
La otra forma interesante de representar correlaciones son elipses de correlación (a partir del paquete de elipse). En ese caso, los coeficientes de correlación se muestran como elipses comprimidas de diversas maneras; cuando el coeficiente está cerca\(-1\) o\(+1\), la elipse es más estrecha (Figura\(\PageIndex{4}\)). La pendiente de la elipse representa el signo de correlación (negativa o positiva):
Código\(\PageIndex{15}\) (R):
Varias formas útiles de visualizar y analizar las correlaciones presentes en el archivo asmisc.r suministrado con este libro:
Código\(\PageIndex{16}\) (R):
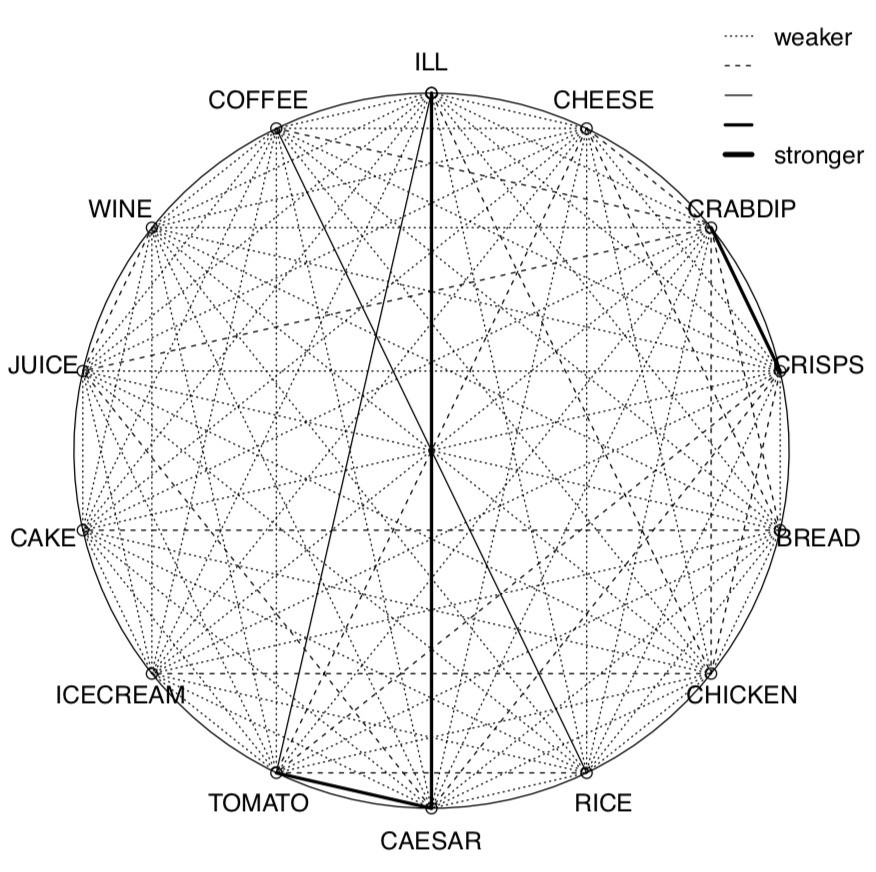
Calculamos aquí el coeficiente de correlación de Kendall para los datos binarios de toxicidad para hacer la imagen utilizada en la página de título. La pleíada () no solo mostró (Figura\(\PageIndex{5}\)) que la enfermedad se asocia con tomate y ensalada César, sino que también encontró otras dos pleíadas de correlación: café/arroz y cangrejo dip/papas fritas. (Por cierto, las pléyadas muestran una aplicación más de R: análisis de redes.)
La función Cor () genera matriz de correlación junto con asteriscos para las pruebas de correlación significativas:
Código\(\PageIndex{17}\) (R):

Finalmente, la función Topm () muestra las correlaciones más grandes por filas:
Código\(\PageIndex{18}\) (R):
El archivo de datos traits.txt contiene los resultados de la encuesta donde se registraron la mayoría de los caracteres de fenotipo humano genéticamente aparentes de muchos individuos. La explicación de estos caracteres se encuentran en el archivo trait_c.txt. Analice estos datos con métodos de correlación.
Referencias
1. Existen, sin embargo, técnicas avanzadas con el objetivo de entender la diferencia entre causalidad y correlación: por ejemplo, las implementadas en el paquete bnlearn.