
10.8: Respuestas a ejercicios
- Page ID
- 149929
Respuesta a la pregunta de la humedad del sol. Apliquemos el enfoque que utilizamos para la forma de la hoja:
Código\(\PageIndex{1}\) (R):
(No se muestran las parcelas, por favor hágalas tú mismo.)
Hay cierta periodicidad con un periodo de 0.2 (5 horas). Sin embargo, es probable que la tendencia esté ausente.
Respuesta a la pregunta de infestación de dodder. Inspeccione los datos, cargue y verifique:
Código\(\PageIndex{2}\) (R):
(Tenga en cuenta que se clasifican dos últimas columnas. En consecuencia, aquí solo son aplicables los métodos no paramétricos).
Luego tenemos que seleccionar dos hosts de pregunta y dejar caer los niveles no utilizados:
Código\(\PageIndex{3}\) (R):
Es mejor convertir esto a la forma corta:
Código\(\PageIndex{4}\) (R):
No mire gráficamente estas muestras:
Código\(\PageIndex{5}\) (R):
Hay una diferencia destacada. Ahora a los números:
Código\(\PageIndex{6}\) (R):
¡Interesante! A pesar de la diferencia entre medianas y tamaño de efecto grande, la prueba de Wilcoxon no pudo sostenerla estadísticamente. ¿Por qué? ¿Eran similares las formas de las distribuciones?
Código\(\PageIndex{7}\) (R):
(Tenga en cuenta cómo hacer un diseño complejo con el comando layout (). Este comando toma matriz como argumento, y luego simplemente coloca el número de parcela algo a la posición donde este número ocurre en la matriz. Después de que se creó el diseño, puede verificarlo con el comando layout.show (la).)
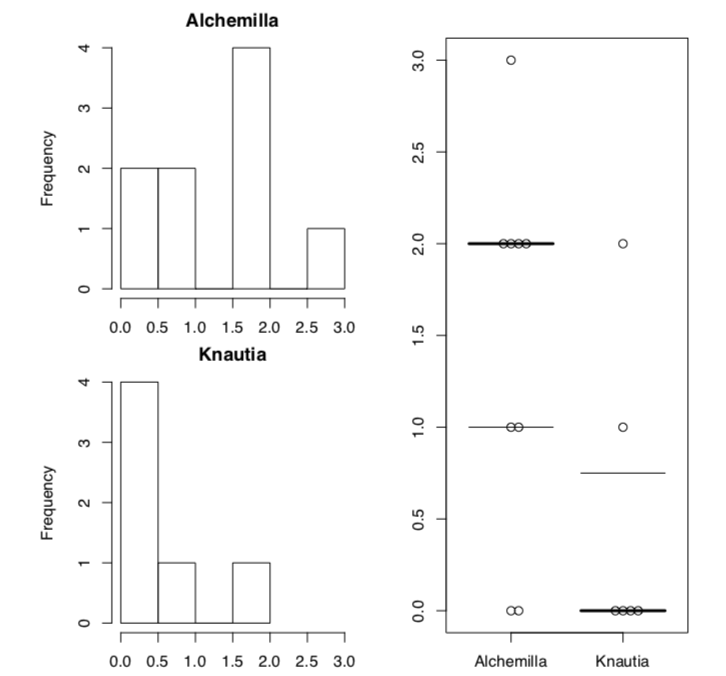
Como sugieren tanto la prueba de Ansari-Bradley como las parcelas, las distribuciones son realmente diferentes (Figura\(\PageIndex{2}\)). Una solución alternativa es usar una prueba de orden de rango robusta que no sea tan sensible a las diferencias en la variación:
Código\(\PageIndex{8}\) (R):
Esta prueba encontró la significación.
Ahora vamos a tratar de bootstrap la diferencia entre medianas:
Código\(\PageIndex{9}\) (R):
(Tenga en cuenta cómo se aplicaron los estratos para evitar la mezcla de dos huéspedes diferentes).
Esto no es diferente a lo que vimos anteriormente en la salida del tamaño del efecto: gran diferencia pero 0 incluido. Esto podría describirse como diferencia “prominente pero inestable”.
Eso no se preguntó en la asignación sino cómo analizar datos completos en caso de formas tan diferentes de distribuciones. Una posibilidad es la prueba de Kruskal con replicaciones de Montecarlo. Por defecto, hace 1000 intentos:
Código\(\PageIndex{10}\) (R):
No hay significación general. No es una sorpresa, las pruebas similares a Anova a veces podrían contradecir con individual o por pares.
Otra posibilidad es una prueba de orden de rango robusta post hoc:
Código\(\PageIndex{11}\) (R):
Ahora encontró algunas diferencias significativas pero no lo reveló para nuestro caso marginal e inestable de Alquimila y Kde.