
2.5: ¿Qué hace que una buena medición?
- Page ID
- 150753

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)En muchos campos como la psicología, lo que estamos midiendo no es una característica física, sino que es un concepto teórico inobservable, al que solemos referirnos como constructo. Por ejemplo, digamos que quiero probar qué tan bien entiende la distinción entre las cuatro escalas diferentes de medición descritas anteriormente. Podría darte un quiz pop que te haría varias preguntas sobre estos conceptos y contaría cuántas acertabas. Esta prueba podría ser o no una buena medida de la construcción de tu conocimiento real, por ejemplo, si tuviera que escribir la prueba de una manera confusa o usar un lenguaje que no entiendes, entonces la prueba podría sugerir que no entiendes los conceptos cuando realmente lo haces. Por otro lado, si doy una prueba de opción múltiple con respuestas incorrectas muy obvias, entonces podrías tener un buen desempeño en la prueba aunque en realidad no entiendas el material.
Por lo general, es imposible medir un constructo sin cierta cantidad de error. En el ejemplo anterior, puede que conozcas la respuesta pero podrías leer mal la pregunta y equivocarla. En otros casos existe un error intrínseco a la cosa que se está midiendo, como cuando medimos cuánto tiempo tarda una persona en responder en una simple prueba de tiempo de reacción, que variará de un ensayo a otro por muchas razones. Por lo general, queremos que nuestro error de medición sea lo más bajo posible.
A veces hay un estándar contra el cual se pueden probar otras mediciones, a lo que podríamos referirnos como un “estándar oro” — por ejemplo, la medición del sueño se puede hacer usando muchos dispositivos diferentes (como dispositivos que miden el movimiento en la cama), pero generalmente se consideran inferiores al estándar oro de polisomnografía (que utiliza la medición de las ondas cerebrales para cuantificar la cantidad de tiempo que una persona pasa en cada etapa del sueño). A menudo el estándar oro es más difícil o costoso de realizar, y se usa el método más barato aunque pueda tener mayor error.
Cuando pensamos en lo que hace una buena medición, solemos distinguir dos aspectos diferentes de una buena medición.
2.5.1 Confiabilidad
La confiabilidad se refiere a la consistencia de nuestras mediciones. Una forma común de confiabilidad, conocida como “confiabilidad test-retest”, mide qué tan bien coinciden las mediciones si la misma medición se realiza dos veces. Por ejemplo, podría darle un cuestionario sobre su actitud hacia las estadísticas hoy, repetir este mismo cuestionario mañana, y comparar sus respuestas en los dos días; esperaríamos que fueran muy similares entre sí, a menos que haya ocurrido algo entre las dos pruebas que debería haber cambiado su visión de las estadísticas (¡como leer este libro!).
Otra forma de evaluar la confiabilidad viene en los casos en que los datos incluyen juicios subjetivos. Por ejemplo, digamos que un investigador quiere determinar si un tratamiento cambia qué tan bien interactúa un niño autista con otros niños, lo que se mide haciendo que los expertos vigilen al niño y califiquen sus interacciones con los otros niños. En este caso nos gustaría asegurarnos de que las respuestas no dependan del calificador individual, es decir, nos gustaría que hubiera una alta confiabilidad entre evaluadores. Esto se puede evaluar haciendo que más de un calificador realicen la calificación, y luego comparando sus calificaciones para asegurarse de que coincidan bien entre sí.
La confiabilidad es importante si queremos comparar una medición con otra. La relación entre dos variables diferentes no puede ser más fuerte que la relación entre cualquiera de las variables y sí misma (es decir, su confiabilidad). Esto significa que una medida poco confiable nunca puede tener una fuerte relación estadística con ninguna otra medida. Por esta razón, los investigadores que desarrollan una nueva medición (como una nueva encuesta) a menudo harán todo lo posible para establecer y mejorar su confiabilidad.
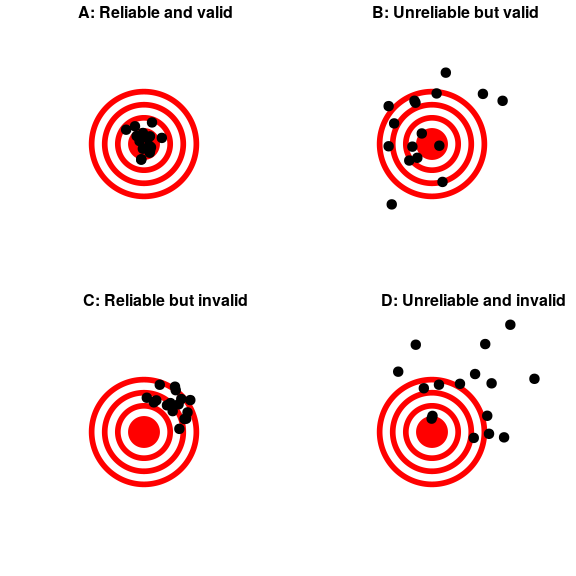
2.5.2 Validez
La confiabilidad es importante, pero por sí sola no es suficiente: Después de todo, podría crear una medición perfectamente confiable en un test de personalidad recodificando cada respuesta usando el mismo número, independientemente de cómo responda realmente la persona. Queremos que nuestras medidas también sean válidas —es decir, queremos asegurarnos de que realmente estamos midiendo el constructo que creemos que estamos midiendo (Figura 2.1). Hay muchos tipos diferentes de validez que se discuten comúnmente; nos centraremos en tres de ellos.
Vigencia facial. ¿La medición tiene sentido en su cara? Si te dijera que iba a medir la presión arterial de una persona mirando el color de su lengua, probablemente pensarías que esta no era una medida válida en su cara. Por otro lado, el uso de un manguito de presión arterial tendría validez facial. Esta suele ser una primera comprobación de la realidad antes de sumergirnos en aspectos más complicados de la validez.
Validez de constructo. ¿La medición está relacionada con otras mediciones de manera apropiada? Esto a menudo se subdivide en dos aspectos. Validez convergente significa que la medición debe estar estrechamente relacionada con otras medidas que se piensa que reflejan el mismo constructo. Digamos que me interesa medir qué tan extrovertida es una persona usando un cuestionario o una entrevista. La validez convergente se demostraría si ambas mediciones diferentes están estrechamente relacionadas entre sí. Por otro lado, las mediciones pensadas para reflejar diferentes constructos deben no estar relacionadas, lo que se conoce como validez divergente. Si mi teoría de la personalidad dice que la extraversión y la escrupulosidad son dos constructos distintos, entonces también debería ver que mis medidas de extraversión no están relacionadas con las medidas de escrupulosidad.
Validez predictiva. Si nuestras mediciones son verdaderamente válidas, entonces también deberían ser predictivas de otros resultados. Por ejemplo, digamos que pensamos que el rasgo psicológico de la búsqueda de sensaciones (el deseo de nuevas experiencias) está relacionado con la toma de riesgos en el mundo real. Para probar la validez predictiva de una medición de búsqueda de sensaciones, probaríamos qué tan bien los puntajes de la prueba predicen puntajes en una encuesta diferente que mide la toma de riesgos en el mundo real.