
8.4: ¿Qué hace que un modelo sea “bueno”?
- Page ID
- 150865

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Generalmente hay dos cosas diferentes que queremos de nuestro modelo estadístico. Primero, queremos que describa bien nuestros datos; es decir, queremos que tenga el menor error posible al modelar nuestros datos. Segundo, queremos que se generalice bien a nuevos conjuntos de datos; es decir, queremos que su error sea lo más bajo posible cuando lo aplicamos a un nuevo conjunto de datos. Resulta que estas dos características a menudo pueden estar en conflicto.
Para entender esto, pensemos de dónde viene el error. Primero, puede ocurrir si nuestro modelo está equivocado; por ejemplo, si dijimos inexactamente que la altura baja con la edad en lugar de subir, entonces nuestro error será mayor de lo que sería para el modelo correcto. De igual manera, si hay un factor importante que falta en nuestro modelo, eso también aumentará nuestro error (como lo hizo cuando dejamos la edad fuera del modelo por altura). Sin embargo, el error también puede ocurrir incluso cuando el modelo es correcto, debido a la variación aleatoria en los datos, a lo que a menudo nos referimos como “error de medición” o “ruido”. A veces esto realmente se debe a un error en nuestra medición —por ejemplo, cuando las mediciones dependen de un ser humano, como usar un cronómetro para medir el tiempo transcurrido en una carrera a pie de pies. En otros casos, nuestro dispositivo de medición es altamente preciso (como una báscula digital para medir el peso corporal), pero lo que se mide se ve afectado por muchos factores diferentes que hacen que sea variable. Si conociéramos todos estos factores entonces podríamos construir un modelo más preciso, pero en realidad eso rara vez es posible.
Usemos un ejemplo para mostrar esto. En lugar de usar datos reales, generaremos algunos datos para el ejemplo usando una simulación por computadora (sobre la cual tendremos más que decir en unos pocos capítulos). Digamos que queremos entender la relación entre el contenido de alcohol en sangre (BAC) de una persona y su tiempo de reacción en un examen de manejo simulado. Podemos generar algunos datos simulados y trazar la relación (ver Panel A de la Figura 8.5).
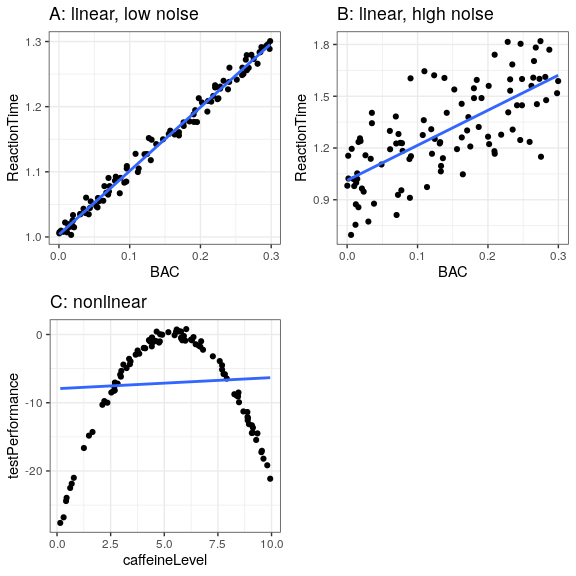
En este ejemplo, el tiempo de reacción sube sistemáticamente con el contenido de alcohol en sangre —la línea muestra el modelo que mejor se ajusta, y podemos ver que hay muy poco error, lo cual es evidente en el hecho de que todos los puntos están muy cerca de la línea.
También podríamos imaginar datos que muestran la misma relación lineal, pero tienen mucho más error, como en el Panel B de la Figura 8.5. Aquí vemos que todavía hay un aumento sistemático del tiempo de reacción con BAC, pero es mucho más variable entre los individuos.
Ambos fueron ejemplos donde el modelo lineal parece apropiado, y el error refleja el ruido en nuestra medición. El modelo lineal especifica que la relación entre dos variables sigue una línea recta. Por ejemplo, en un modelo lineal, el cambio en BAC siempre se asocia con un cambio específico en ReactionTime, independientemente del nivel de BAC.
Por otro lado, hay otras situaciones en las que el modelo lineal es incorrecto, y se incrementará el error debido a que el modelo no está debidamente especificado. Digamos que nos interesa la relación entre la ingesta de cafeína y el rendimiento en una prueba. La relación entre estimulantes como la cafeína y el rendimiento de las pruebas suele ser no lineal, es decir, no sigue una línea recta. Esto se debe a que el rendimiento aumenta con menores cantidades de cafeína (a medida que la persona se vuelve más alerta), pero luego comienza a disminuir con cantidades mayores (a medida que la persona se pone nerviosa y nerviosa). Podemos simular datos de esta forma, y luego ajustar un modelo lineal a los datos (ver Panel C de la Figura 8.5). La línea azul muestra la línea recta que mejor se ajusta a estos datos; claramente, hay un alto grado de error. Si bien existe una relación muy legal entre el rendimiento de la prueba y la ingesta de cafeína, sigue una curva más que una línea recta. El modelo lineal tiene un alto error porque es el modelo incorrecto para estos datos.