1.10: Fotogrametría y estructura desde el movimiento
- Page ID
- 89328

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Todas las aplicaciones de los datos de teledetección cubiertas en los capítulos anteriores se han basado en imágenes individuales (por ejemplo, clasificación), o en series temporales de imágenes (por ejemplo, detección de cambios). Sin embargo, cuando se adquieren dos (o más) imágenes de una misma área, en rápida sucesión y desde diferentes ángulos, es posible extraer información geométrica sobre el área mapeada, así como nuestros ojos y cerebro extraen información 3D sobre el mundo que nos rodea cuando lo miramos con nuestros dos ojos. Este es el subcampo de la teledetección llamado fotogrametría.
Fotogrametría tradicional (de imagen única y estéreo)
La fotogrametría implica el uso de información sobre la geometría de imágenes (distancia entre el sensor y el objeto, la posición y orientación del sensor y la geometría interna del sensor) para obtener información sobre las posiciones, formas y tamaños de los objetos vistos en las imágenes. La fotogrametría se ha utilizado desde el primer uso de la fotografía aérea, y la idea básica en este campo es permitir la medición de distancias en imagen. Como tal, la fotogrametría te permite averiguar qué tan largo es un segmento de carretera, qué tan lejos está del punto A al punto B, y qué tan grande es realmente tu pista de patinaje local (suponiendo que tengas una imagen bien calibrada de la misma, es decir). Puedes pensarlo en términos de tomar una fotografía aérea y manipularla de una manera que puedas superponerla en un SIG, o en Google Earth. Una vez que las coordenadas geográficas están asociadas con la imagen, se hace posible la medición de distancias.
Imagen vertical única, terreno plano
El escenario más simple posible en la fotogrametría es que se tiene una imagen producida por un sensor que apunta directamente hacia la Tierra, y que la imagen contiene terreno perfectamente nivelado. Si asumimos que la imagen fue tomada por un sensor ubicado ya sea en una aeronave que vuela a muy gran altitud, o en un satélite, y que la imagen cubre solo un área muy pequeña, podemos hacer la suposición simplificadora de que cada parte de la imagen ha sido fotografiada exactamente desde el cenit, y que como resultado el la distancia entre el sensor y la superficie de la Tierra es la misma en toda la imagen (Figura 75).
En este caso, la escala de la imagen es igual a la relación de la distancia focal de la cámara (f, o una medida equivalente para tipos de sensores distintos de las cámaras estenopeicas) y la distancia entre el sensor y el suelo (H):
Si conoces la escala de tu imagen, entonces puedes medir distancias entre objetos del mundo real midiendo su distancia en la imagen y dividiendo por la escala (nótese que la escala es una fracción que tiene 1 en el numerador, por lo que dividir por la escala es lo mismo que multiplicar por el denominador).
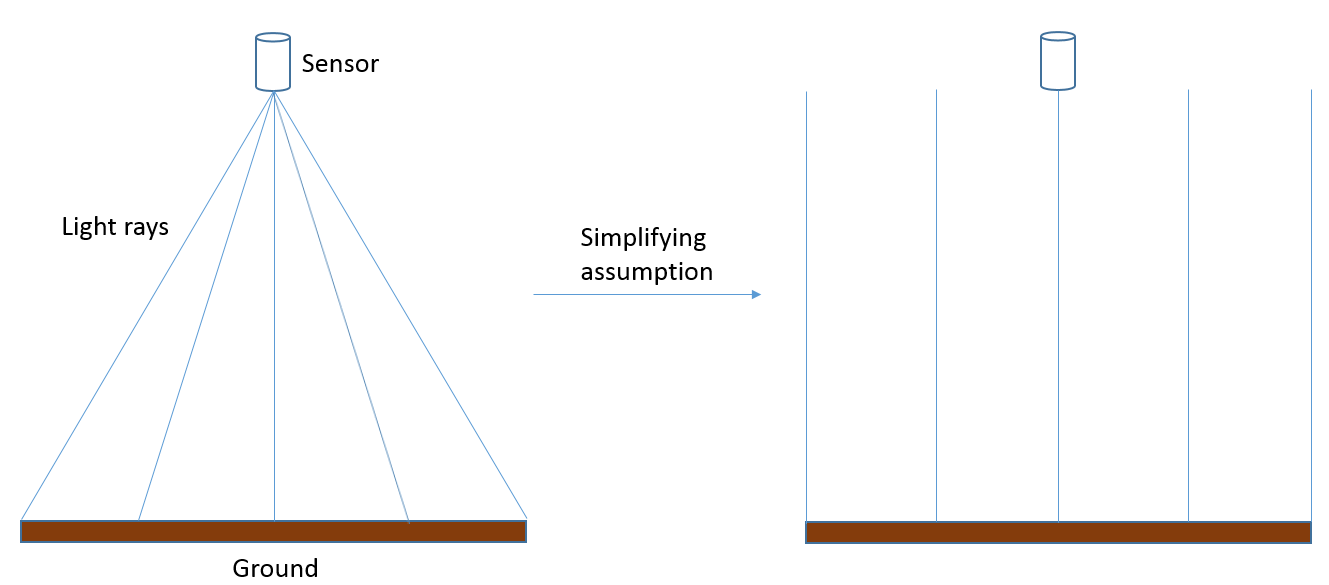
75: En realidad, se crea una imagen a partir de la luz que llega al sensor en diferentes ángulos desde diferentes partes de la superficie de la Tierra. Para los propósitos actuales, podemos suponer que estos ángulos de hecho no son diferentes, y que como resultado la distancia entre el sensor y la superficie de la Tierra es la misma a lo largo de una imagen. En realidad, esta suposición no es correcta, y la resolución escala/espacial realmente cambia desde el centro de la imagen hacia los bordes de la imagen. Anders Knudby, CC BY 4.0.
Esta definición de escala sólo es realmente relevante para la fotografía aérea analógica, donde el producto de imagen se imprime en papel y se fija la relación entre la longitud de las cosas en la imagen y la longitud de esas mismas cosas en el mundo real. Para la fotografía aérea digital, o cuando se utilizan imágenes satelitales en fotogrametría, la 'escala' de la imagen depende del nivel de zoom, que el usuario puede variar, por lo que la medida más relevante del detalle espacial es la resolución espacial que ya hemos visto en capítulos anteriores. La resolución espacial se define como la longitud sobre el terreno de un lado de un píxel, y esto no cambia dependiendo del nivel de zoom (lo que cambia al acercar y alejar es simplemente la granulosidad con la que aparece la imagen en su pantalla). Podemos, sin embargo, definir una resolución espacial 'nativa' de una manera similar a la que se utiliza para las imágenes analógicas, basada en la distancia focal (f), el tamaño de los elementos detectores individuales en el sensor de la cámara (d), y la distancia entre el sensor y el suelo (H):
Imagen vertical única, terreno montañoso
La situación se complica más cuando se toma una imagen sobre un terreno que no se puede suponer razonablemente que es perfectamente plano, o cuando la distancia entre el sensor y el suelo es suficientemente pequeña, o el área cubierta por la imagen lo suficientemente grande, que la distancia real entre el sensor y el el suelo cambia sustancialmente entre diferentes partes de la imagen:

76: Cuando se toma una imagen más cerca de la superficie de la Tierra, o sobre un terreno más montañoso, no se puede suponer que la distancia entre el sensor y la superficie de la Tierra sea constante en toda la imagen. Si no se toma en cuenta, esto conduce a un desplazamiento tanto vertical como horizontal de los objetos fotografiados. Anders Knudby, CC BY 4.0.
El terreno montañoso causa una serie de problemas en la fotogrametría, lo que es más importante el desplazamiento vertical y horizontal de los objetos fotografiados. Como se ilustra en la Figura 76, si se supone que el punto X se encuentra sobre la superficie plana (y no en la colina donde realmente se encuentra), con base en la geometría de imagen se asumirá que su posición horizontal está en X', porque ahí es donde el 'haz de luz' cruza el suelo plano. En realidad, por supuesto, su posición horizontal no está en X'. Si se conoce el terreno superficial del área fotografiada, por ejemplo a través de la disponibilidad de un modelo digital de elevación de alta calidad, se puede tomar en cuenta a la hora de georreferenciar la imagen y se puede identificar la intersección correcta entre el 'haz de luz' y el suelo (en la colina). Sin embargo, si no existe un modelo digital de elevación, el efecto del terreno —conocido como desplazamiento en relieve— no puede explicarse explícitamente, aunque sea obvio en las imágenes resultantes.
Imágenes estéreo
Hasta hace una década, probablemente el uso más avanzado de la fotogrametría era usar un par estéreo (dos imágenes que cubren la misma área desde diferentes puntos de vista) para derivar directamente un modelo digital de elevación a partir de las imágenes, lo que también permitía cosas como medir las alturas de cosas como edificios, árboles, autos, y así sucesivamente. El principio básico de la estereoscopía, como se llama la técnica, es una réplica de lo que haces con tus dos ojos todo el tiempo —al ver un objeto o un paisaje desde dos ángulos diferentes es posible reconstruir un modelo tridimensional del mismo. Si bien hay un arte sofisticado para hacer esto con alta precisión (un arte que no podemos explorar como parte de este curso), revisaremos la idea básica aquí.

77: Ilustración de cómo las posiciones horizontales aparentes del punto A y B cambian entre las dos imágenes que forman una visión estéreo del área. El tamaño del sensor ha sido muy exagerado para mostrar la ubicación de cada punto en el plano principal. Anders Knudby, CC BY 4.0.
En la Figura 77, la Imagen 1 y la Imagen 2 representan una vista estéreo del paisaje que contiene algún terreno plano y dos cerros, con los puntos A y B. En el lado izquierdo de la figura (Imagen 1), a y b denotan las ubicaciones en las que se registraría cada punto en el plano principal de esa imagen, lo que corresponde a donde se encuentra el puntos estarían en la imagen resultante. En el lado derecho de la figura, la cámara se ha movido hacia la izquierda (siguiendo la trayectoria de vuelo del avión o el movimiento del satélite en su órbita), y nuevamente b' y a' denotan las ubicaciones en las que se registraría cada punto en el plano principal de esa imagen. Lo importante a tener en cuenta es que a es diferente de a' porque el sensor se ha movido entre las dos imágenes, y de manera similar b es diferente de b'. Más específicamente, como se ilustra en la Figura 78, la distancia entre a y a' es mayor que la distancia entre b y b', porque A está más cerca del sensor que B. Estas distancias, conocidas como paralaje, son las que transmiten información sobre la distancia entre el sensor y cada punto, y así sobre la altitud a la que se ubica cada punto. En realidad, derivar la altura de A en relación con el nivel del suelo plano o el nivel relativo del mar o un dato vertical, o incluso mejor derivar un modelo de elevación digital para toda el área, requiere un posicionamiento relativo cuidadoso de las dos imágenes (generalmente se realiza mediante la localización de muchas características de superficie que se pueden reconocer en ambas imágenes) así como conocer algo sobre la posición y orientación del sensor cuando se adquirieron las dos imágenes (normalmente se hace con información basada en GPS), y finalmente conocer algo sobre la geometría interna del sensor (normalmente esta información la proporciona el fabricante del sensor).

La matemática aplicada en la estereoscopía es bastante complicada, pero en la práctica incluso un novato puede producir modelos digitales de elevación útiles a partir de imágenes estéreo con software comercial. Si bien existe algún software de fotogrametría especializado, los grandes paquetes comerciales de software de teledetección suelen incluir un 'módulo de fotogrametría' que puede ayudarlo a producir modelos digitales de elevación incluso si no es un fotogrametrista experto. En lo anterior, hemos asumido imágenes de aspecto nadir (es decir, que el sensor apuntaba directamente hacia la Tierra para cada imagen) porque los conceptos se complican cuando este no es el caso, pero también existen soluciones matemáticas para las imágenes oblicuas. De hecho, uno de los atributos útiles de varios satélites modernos que transportan sensores de imagen es su capacidad de inclinación, lo que permite que dos imágenes sean capturadas por un mismo sensor durante la misma órbita. A medida que el satélite se acerca a su objetivo, se puede apuntar hacia adelante para capturar una imagen, y más tarde en la órbita se puede apuntar hacia atrás para obtener una imagen de la misma área nuevamente desde un ángulo diferente.
Estructura desde el movimiento (fotogrametría multiimagen)
Como sucede ocasionalmente en el campo de la teledetección, las técnicas desarrolladas inicialmente para otros fines (por ejemplo, imágenes médicas, aprendizaje automático y visión por computador) muestran potencial para el procesamiento de imágenes de teledetección, y ocasionalmente terminan revolucionando parte de la disciplina. Tal es el caso de la técnica conocida como Structure-from-motion (SfM, si la 'f' pretende ser minúscula), cuyo desarrollo estuvo influenciado por la fotogrametría pero se basó en gran medida en la comunidad de visión computadora/inteligencia artificial. La idea básica en SfM se puede explicar con otra visión humana paralela: si la estereoscopia imita la capacidad de su sistema ojo-cerebro para usar dos vistas de un área adquirida desde diferentes ángulos para derivar información 3D sobre ella, SfM imita su capacidad para cerrar un ojo y correr alrededor de un área, derivando información 3D al respecto a medida que te mueves (¡no intentes esto en el aula, solo imagina cómo podría funcionar realmente!). En otras palabras, SfM es capaz de reconstruir un modelo 3D de un área a partir de múltiples imágenes superpuestas tomadas con la misma cámara desde diferentes ángulos (o con diferentes cámaras en realidad, pero eso se vuelve más complicado y rara vez es relevante para las aplicaciones de teledetección).
Hay un par de razones por las que SfM ha revolucionado rápidamente el campo de la fotogrametría, hasta el punto en que la estereoscopia tradicional puede convertirse rápidamente en cosa del pasado. A continuación se enumeran algunas de las diferencias importantes entre ambos:
- La estereoscopía tradicional (de dos imágenes) requiere que la geometría interna de la cámara se caracterice bien. Si bien existen procesos establecidos para averiguar qué es esta geometría, requieren un nivel moderado de experiencia y requieren que el usuario realmente pase y 'calibra' la cámara. SfM realiza esta calibración de cámara utilizando las mismas imágenes que se utilizan para mapear el área de interés.
- En una línea similar, la estereoscopía tradicional requiere que la posición y orientación (apuntamiento) de la cámara se conozca con gran precisión para cada imagen. SfM se beneficia de información aproximada sobre algunos o todos esos parámetros, pero no los necesita estrictamente y es capaz de derivarlos con mucha precisión a partir de las propias imágenes. Debido a que muchas cámaras modernas (como las de tu teléfono) tienen receptores GPS internos que proporcionan información de ubicación aproximada, esto permite que las cámaras de consumo se utilicen para derivar modelos digitales de elevación notablemente precisos.
- Para ambas técnicas, si no se conocen las posiciones de la cámara, el modelo 3D reconstruido a partir de las imágenes puede ser georreferenciado utilizando puntos de imagen de ubicación conocida. De esta manera las dos técnicas son similares.
- La rápida evolución de los drones ha proporcionado a la gente promedio una plataforma para mover una cámara de nivel de consumidor de maneras que anteriormente se limitaban a personas con acceso a aviones tripulados. Las imágenes tomadas por cámaras de grado consumidor basadas en drones son exactamente el tipo de entrada necesaria en un flujo de trabajo SfM, mientras que no funcionan bien en el flujo de trabajo de estereoscopía tradicional.
Como se mencionó anteriormente, SfM utiliza múltiples fotos superpuestas para producir un modelo 3D del área fotografiada en las fotos. Esto se realiza en una serie de pasos como se describe a continuación y se muestra en la Figura 79:
Paso 1) Identificar las mismas características en múltiples imágenes. Para poder identificar las mismas características en fotos tomadas desde diferentes ángulos, desde diferentes distancias, con las cámaras no siempre orientadas de la misma manera, posiblemente incluso bajo diferentes condiciones de iluminación, en casos extremos incluso con diferentes cámaras, SfM comienza identificando características usando el algoritmo SIFT. Estas características suelen ser aquellas que se destacan de su entorno, como esquinas o bordes, u objetos que son más oscuros o más brillantes que sus alrededores. Si bien muchas de estas características son fáciles de identificar para los humanos, y otras no, el algoritmo SIFT está diseñado específicamente para permitir identificar las mismas características a pesar de los desafíos circunstancias descritas anteriormente. Esto le permite funcionar especialmente bien en el contexto de la SfM.
Paso 2) Utilice estas características para derivar información de cámara interior y exterior, así como posiciones 3D de las características. Una vez que se han identificado múltiples características en múltiples imágenes superpuestas, se resuelve un conjunto de ecuaciones para minimizar el error posicional relativo general de los puntos en todas las imágenes. Por ejemplo, considere las siguientes tres (o más) imágenes, en las que se han identificado los mismos múltiples puntos (mostrados como puntos coloreados):

79: Ejemplo de ajuste de bloque de haz en SfM. Sfm1 por Maiteng, Wikimedia Commons, CC BY-SA 4.0.
Sabiendo que el punto rojo en P1 es el mismo que el punto rojo en P2 y P3 y cualquier otra cámara involucrada, y de manera similar para los otros puntos, se puede derivar la posición relativa tanto de los puntos como de las ubicaciones y orientaciones de la cámara (así como los parámetros ópticos involucrados en el proceso de formación de imágenes de la cámara). (Tenga en cuenta que el término 'cámara' como se usa aquí es idéntico a 'imagen').
El resultado inicial de este proceso es una ubicación relativa de todos los puntos y cámaras, es decir, el algoritmo definió la ubicación de cada característica y cámara en un sistema de coordenadas tridimensional arbitrario. Dos piezas de información adicional se pueden utilizar para transformar las coordenadas de este sistema arbitrario a coordenadas del mundo real como latitud y longitud.
Si se conoce la geolocalización de cada cámara antes de este proceso, por ejemplo, si la cámara produjo imágenes geoetiquetadas, las ubicaciones de las cámaras en el sistema de coordenadas arbitrarias pueden compararse con sus ubicaciones reales en el mundo real, y se puede definir una transformación de coordenadas y también aplicarse al ubicaciones de las características identificadas. Alternativamente, si se conocen las ubicaciones de algunas de las características identificadas (por ejemplo, a partir de mediciones GPS en el campo), se puede usar una transformación de coordenadas similar. Para fines de teledetección, una de estas dos fuentes de información de geolocalización del mundo real es necesaria para que el producto resultante sea útil.
Paso 3) Basado en las características ahora geoubicadas, identifique más entidades en múltiples imágenes y reconstruya su posición 3D. Imagina que hay un pequeño punto gris cerca del punto rojo en la Figura 79, digamos ¼ del camino hacia el punto verde, en esa dirección (no lo hay, por eso hay que imaginarlo!). Este pequeño punto gris era demasiado débil para ser utilizado como función SIFT, por lo que no se utilizó para derivar la ubicación inicial de las características y orientaciones de las cámaras. No obstante, ahora que sabemos dónde encontrar el punto rojo en cada imagen, y conocemos la posición relativa de cada uno de los otros puntos, podemos estimar dónde debe encontrarse este punto gris en cada una de las imágenes. Con base en esta estimación, en realidad podríamos encontrar el punto gris en cada imagen, y así estimar su ubicación en el espacio. Una vez identificados y ubicados en el espacio, también podemos asignar un color al punto, basado en su color en cada una de las imágenes en las que se encontró. Hacer esto para millones de características que se encuentran en el conjunto completo de imágenes se llama densificación de nubes de puntos, y es un paso opcional pero casi universalmente adoptado en SfM. En áreas con suficiente diferencia entre los colores de los píxeles vecinos en las imágenes relevantes, este paso a menudo puede conducir a la derivación de la ubicación de cada píxel individual en un área pequeña de una imagen. El resultado de este paso, por lo tanto, es una 'nube de puntos' increíblemente densa, en la que millones de puntos se encuentran en el mundo real. A continuación se muestra un ejemplo:

80: Ejemplo de nube de puntos densa, creada para una parte del Parque Gatineau usando imágenes de drones. Anders Knudby, CC BY 4.0.
Paso 4) Opcionalmente, use todas estas características posicionadas en 3D para producir un modelo ortomosaico, un modelo de elevación digital u otro producto útil. La nube de puntos densa se puede utilizar para varios propósitos diferentes; algunos de los más comúnmente utilizados es crear un modelo de elevación ortomosaico y uno digital. Un ortomosaico es un tipo de datos ráster, en el que el área se divide en celdas (píxeles) y el color en cada celda es como se vería si esa celda fuera vista directamente desde arriba. Un ortomosaico es así similar a un mapa excepto que contiene información sobre el color de la superficie, y representa cómo sería el área en una imagen tomada desde infinitamente lejos (pero con muy buena resolución espacial). Los ortomosaicos a menudo se utilizan por sí solos porque dan a las personas una rápida impresión visual de un área, y también forman la base para la creación de mapas a través de la digitalización, clasificación y otros enfoques. Además, debido a que la elevación es conocida para cada punto de la nube de puntos, se puede identificar la elevación de cada celda para crear un modelo digital de elevación. Se pueden utilizar diferentes algoritmos para hacer esto, por ejemplo, identificar el punto más bajo en cada celda para crear un modelo digital de terreno 'bare-tierra', o identificando el punto más alto en cada celda para crear un modelo digital de superficie. Incluso se pueden hacer productos más avanzados, por ejemplo, restando el modelo de tierra descubierta del modelo de superficie para derivar estimaciones de cosas como el árbol y la altura del edificio.
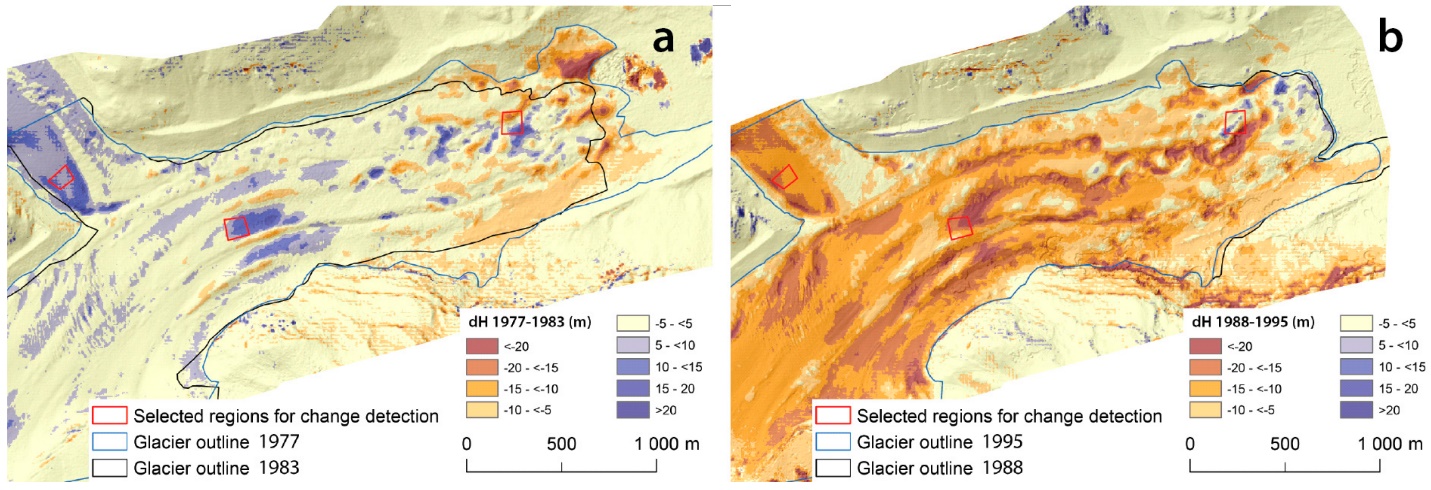
Detección de cambios con fotogrametría
Si bien la creación de modelos digitales de elevación u otros productos usando estereoscopía o enfoques de estructura desde movimiento puede ser útil por sí sola, una aplicación cada vez más común de estas técnicas es para la detección de cambios de superficie. Si, por ejemplo, se crea un modelo digital de elevación para un glaciar un año, y uno nuevo creado dos años después, los cambios en la forma de la superficie del glaciar se pueden mapear con gran precisión. Deslizamientos de tierra, caídas de deshielo, cambios de vegetación, cambios en la profundidad de la nieve a lo largo de una temporada; muchos cambios en el entorno físico pueden detectarse y cuantificarse midiendo los cambios en la posición horizontal o vertical o en la superficie de la Tierra. Dado el desarrollo relativamente reciente de la tecnología SfM, y las capacidades y el costo aún en desarrollo de los drones equipados con cámara, este es un campo de rápido desarrollo que probablemente sea útil en partes sorprendentes e insospechadas del campo de la teledetección. La Figura 81 ilustra este principio comparando el contorno y del glaciar y los cambios en la elevación de la superficie en dos momentos diferentes.