
6.5: Cómo mentir con las estadísticas
- Page ID
- 95150

(El título de esta sección, muchos de los temas que trata, e incluso algunos de los ejemplos que utiliza, están tomados del Huff 1954.)
La base básica en conceptos y técnicas estadísticas fundamentales que se proporciona en la última sección nos da la capacidad de comprender y analizar argumentos estadísticos. Dado que los ejemplos reales de tales argumentos suelen ser manipuladores y engañosos, nuestro objetivo en esta sección es construir sobre los cimientos de los últimos examinando algunas de las falacias estadísticas más comunes: los malos argumentos y las técnicas engañosas utilizadas para tratar de engañarnos con números.
Números impresionantes sin contexto
Estoy considerando comprar una nueva marca de champú. El que estoy viendo promete “85% más de cuerpo”. Eso me suena genial (soy bastante calvo; puedo usar todo el cuerpo extra que pueda obtener). Pero antes de hacer mi compra, tal vez debería considerar el hecho de que la botella de champú no responde a esta sencilla pregunta de seguimiento: ¿85% más de cuerpo que qué? El frasco sí menciona que la formulación en su interior es “nueva y mejorada”. Entonces, ¿tal vez es 85% más de cuerpo que el champú sin mejorar? O posiblemente quieren decir que su champú le da al cabello un 85% más de cuerpo que el de sus competidores. ¿Cuál competidor, sin embargo? ¿El que mejor hace para darle más cuerpo al cabello? ¿El que hace lo peor? ¿El promedio de todas las marcas competidoras? O tal vez es 85% más de cuerpo que algo completamente diferente. Una vez tuve una maestra de secundaria que me aconsejó masajear mi cuero cabelludo durante 10 minutos todos los días para evitar la calvicie (no tomé la sugerencia; tal vez debería haberlo hecho). Quizás este champú produce 85% más de cuerpo que los masajes diarios de 10 minutos. O tal vez sea 85% más de cuerpo que nunca lavarte el cabello en absoluto. Y justo ¿qué es “cuerpo” de todos modos? ¿Cómo se cuantifica y mide? ¿Tomaron pinzas de alta precisión y calibraron sistemáticamente los anchos de los pelos? ¿O es más una función de la cobertura, pelos por pulgada cuadrada de área de superficie del cuero cabelludo?
El triste hecho es que las respuestas a estas preguntas no son próximas. El reclamo de que el champú le dará a mi cabello un 85% más de cuerpo suena impresionante, pero sin alguna información adicional para que yo contextualice esa afirmación, no tengo idea de lo que significa. Se trata de una técnica retórica clásica: tirar un gran número para impresionar a tu público, sin proporcionar el contexto necesario para que evalúen si tu afirmación es realmente tan impresionante o no. Por lo general, en un examen más detenido, no lo es Los anunciantes y políticos utilizan esta técnica todo el tiempo.
En la primavera de 2009, la economía estaba en muy mal estado (las consecuencias de la crisis financiera que comenzó en el otoño del año anterior aún se estaban sintiendo; los índices bursátiles no tocaron fondo hasta marzo de 2009, y la tasa de desempleo seguía en alza). Barack Obama, el presidente recién inaugurado en su momento, quiso enviar el mensaje al pueblo estadounidense de que lo consiguió: los hogares estaban recortando sus gastos debido a la recesión, y así el gobierno haría lo mismo. (Esto suena bien, pero es mala macroeconomía. La mayoría de los economistas coinciden en que durante una recesión como esa, el gobierno debería pedir prestado y gastar más, no menos, para estimular la economía. El presidente lo sabía; marcó el comienzo de un enorme proyecto de ley de gastos gubernamentales a través del Congreso (The American Reinvestment and Recovery Act) a finales de ese año). Después de su primera reunión con su gabinete (los secretarios de Defensa, Estado, Energía, etc.), realizó una rueda de prensa en la que dio a conocer que había ordenado a cada uno de ellos recortar 100 millones de dólares de los presupuestos de sus agencias. Tenía una gran línea para ir con el anuncio: “100 millones ahí, 100 millones aquí —muy pronto, incluso aquí en Washington, se suma al dinero real”. Gracioso. Y que suena impresionante. ¡100 millones de dólares es muchísimo dinero! Al menos, para mí es muchísimo dinero. Tengo, dame un segundo mientras reviso, 64 dólares en mi billetera ahora mismo. Ojalá tuviera 100 millones de dólares. Pero claro que mis finanzas personales son el contexto equivocado en el que evaluar el anuncio del presidente. Está hablando de recortar del presupuesto federal; ese es el contexto. ¿Qué tan grande es eso? En 2009, fueron un poco más los 3 billones de dólares. Son quince departamentos que supervisan los miembros del gabinete. El recorte que Obama ordenó ascendió a mil 500 millones de dólares, entonces. Eso es .05% del presupuesto federal. Ese número no suena tan impresionante ahora que lo ponemos en el contexto adecuado.
2009 proporciona otro ejemplo de esta técnica. Los opositores a la Ley del Cuidado de Salud Asequible (“Obamacare”) se quejaron de la extensión del proyecto de ley: repitieron una y otra vez que tenía mil páginas de largo. Esa denuncia encajaba muy bien con su caracterización de la ley como un boondoggle y una toma gubernamental del sistema de salud. 1,000 páginas seguro suena como muchas páginas. Este libro viene en menos de 250 páginas; ¡imagina si fueran mil! Eso estaría ahí arriba con libros notoriamente largos como Guerra y Paz, Les Miserable, e Infinite Jest. Es largo para un libro, pero ¿son muchas páginas para una pieza de la legislación federal? Bueno, es grande, pero desde luego no inédito. El proyecto de ley de estímulo de ese año tenía aproximadamente la misma duración. El proyecto de ley de presupuesto de 2007 del presidente Bush apenas estaba por debajo de 1,500 páginas. (Este es un recurso útil: http://www.slate.com/articles/news_a...er_weight.html) Su factura de No Child Left Behind registra en apenas menos de 700. El hecho es que las grandes leyes tienen muchas páginas. La Ley del Cuidado de Salud a Bajo Precio no era especialmente inusual.
Error de malentendido
Como discutimos, incorporado a la lógica del muestreo es un margen de error. Es cierto de la medición generalmente que el error aleatorio es inevitable: ya sea que estés midiendo longitud, peso, velocidad, o lo que sea, hay límites inherentes a la precisión y exactitud con la que nuestros instrumentos pueden medir cosas. Los errores de medición están integrados en la lógica de la práctica científica en general; deben ser contabilizados. No hacerlo, o ignorar intencionalmente el error, puede producir informes engañosos de hallazgos.
Esto es particularmente claro en el caso de las encuestas de opinión pública. Como vimos, los resultados de tales encuestas no son los porcentajes precisos que a menudo se reportan, sino rangos de posibles porcentajes (siendo esos rangos solo confiables al nivel de confianza del 95%, típicamente). Y así reportar los resultados de una encuesta, por ejemplo, como “29% de los estadounidenses cree que es Bigfoot”, es un poco engañoso ya que deja fuera el margen de error y el nivel de confianza. Se comete un pecado peor (con bastante frecuencia) cuando se hacen comparaciones entre porcentajes y se omite el margen de error. Esto es típico en la política, cuando se están midiendo los niveles de apoyo a dos contendientes a un cargo. Un titular típico de un periódico podría reportar algo como esto: “Trump se alza en el liderato sobre Clinton en Latest Poll, 44% a 43%”. Este es un titular sexy: es probable que venda papeles (o, hoy en día, genere clics), tanto a los partidarios de Trump (felices) como a los partidarios de Clinton (alarmados). Pero es engañoso: sugiere un nivel de precisión, un resultado definitivo, que los datos simplemente no soportan. Supongamos que el margen de error para esta hipotética encuesta fue de 3%. Lo que realmente nos dicen los resultados de la encuesta, entonces, es que (al nivel de confianza del 95%) el verdadero nivel de apoyo a Trump en la población general está en algún lugar entre 41% y 47%, mientras que el verdadero nivel de apoyo a Clinton está en algún lugar entre 40% y 46%. Esos datos son consistentes con una ventaja de Trump, para estar seguros; pero también permiten una ventaja imponente de 46% a 41% para Clinton. Lo mejor que podemos decir es que es un poco más probable que el verdadero nivel de apoyo de Trump sea más alto que el de Clinton (al menos, estamos bastante seguros; intervalo de confianza del 95% y todo). Cuando las diferencias son menores que el margen de error (realmente, el doble del margen de error al comparar dos números), simplemente no significan mucho. Ese es un hecho que los escritores de titulares suelen ignorar. Esto da a los lectores una impresión engañosa sobre la certeza con la que se puede conocer el estado de la raza.
Al principio de su formación, los científicos aprenden que no pueden reportar valores menores que el error asociado a sus mediciones. Si pesas alguna sustancia, digamos, y luego haces un experimento en el que se convierte en un gas, puedes enchufar tus números a la ley de gas ideal y ponerlos en tu calculadora, pero no puedes reportar todos los números que aparecen después del decimal. El número de los llamados “dígitos significativos” (o a veces “cifras”) que puede usar está limitado por el tamaño del error en sus medidas. Si solo puedes conocer el peso original dentro de .001 gramos, por ejemplo, entonces aunque la calculadora escupe .4237645, solo puedes reportar un resultado usando tres dígitos significativos—.424 después del redondeo.
Cuantos más dígitos significativos informe, más precisa implica que es su medición. Esto puede tener el efecto retórico de hacer que tu audiencia sea más fácil de persuadir. Los números precisos son impresionantes; dan a la gente la impresión de que realmente sabes de lo que estás hablando, de que has hecho algún trabajo analítico cuantitativo serio. Supongamos que le pregunto a mil estudiantes universitarios cuánto durmieron anoche. (Este ejemplo inspirado en Huff 1954, pp. 106 - 107.) Sumo todos los números y divido por 1,000, y mi calculadora me da 7.037 horas. Si le dijera a la gente que había hecho un estudio que mostrara que el estudiante universitario promedio duerme 7.037 horas por noche, quedarían bastante impresionados: mis métodos de investigación fueron tan minuciosos que puedo reportar los tiempos de sueño hasta las milésimas de hora. Probablemente tengan una imagen mental de mi laboratorio, con un equipo elaborado conectado a estudiantes universitarios en camas, midiendo cosas como movimientos oculares rápidos y patrones respiratorios para determinar los instantes precisos en los que comienza y termina el sueño. Pero no tengo ese laboratorio. Yo sólo le pregunté a un montón de gente. Pregúntate: ¿cuánto dormiste anoche? Tengo alrededor de 9 horas (es fin de semana). La palabra clave en esa oración es 'acerca de'. ¿Podría haber sido un poco más o menos de 9 horas? ¿Podrían haber sido 9 horas y 15 minutos? ¿8 horas y 45 minutos? Claro. El error en el reporte de cualquier persona de lo mucho que durmió anoche seguramente será algo así como un cuarto de hora. Eso quiere decir que no tengo derecho a esas 37 milésimas de hora que reporté de mi pequeña encuesta. Lo mejor que puedo hacer es decir que el estudiante universitario promedio obtiene aproximadamente 7 horas de sueño por noche, más o menos 15 minutos más o menos. 7.037 es preciso, pero la precisión de esa cifra es espuria (no genuina, falsa).
Ignorar el error adjunto a las mediciones puede tener profundos efectos en la vida real. Consideremos las elecciones presidenciales de Estados Unidos del 2000. George W. Bush derrotó a Al Gore ese año, y todo se redujo al estado de Florida, donde el margen final de victoria (después de que se iniciaron los recuentos, luego se pararon, luego se iniciaron de nuevo, luego finalmente se detuvo por orden de la Suprema Corte de Estados Unidos) fue de 327 votos. Ese año se emitieron alrededor de 6 millones de votos en Florida. El margen de 327 es de aproximadamente .005% del total. Aquí está la cosa: contar votos es una medida como cualquier otra; hay un error adjunto a ella. Quizás recuerdes que en muchos condados de Florida, estaban usando boletas de tarjetas perforadas, donde los votantes indican su preferencia perforando un agujero a través de un círculo perforado en el periódico junto al nombre de su candidato. A veces, el trozo de papel circular —el llamado “chad ”— no se separa completamente de la boleta, y cuando esa boleta se pasa por la máquina de conteo de votos, el chad termina cubriendo el agujero y se registra erróneamente un no voto. Otros tipos de métodos de conteo de votos, incluso conteo manual (¡puede ser tan alto como 2% para el conteo manual! Ver aquí: https://www.sciencedaily.com/release...0202151713.htm) —tienen su propio error. Y sea cual sea el método que se utilice, el error va a ser mayor que el margen del .005% que decidió la elección. Como dijo un destacado matemático, “Estamos midiendo bacterias con un criterio”. (John Paulos, “Estamos midiendo bacterias con una vara de medir”, 22 de noviembre de 2000, The New York Times.) Es decir, el instrumento que estamos usando (contando, a máquina o a mano) es demasiado crudo para medir el tamaño de lo que nos interesa (la diferencia entre Bush y Gore). Sugirió que voltearan una moneda para decidir Florida. Simplemente es imposible saber quién ganó esa elección.
En 2011, el recién electo gobernador de Wisconsin Scott Walker, junto con sus aliados en la legislatura estatal, aprobaron un proyecto de ley de presupuesto que tuvo el efecto, entre otras cosas, de recortar el salario de los empleados del sector público en una cantidad bastante significativa. Hubo mucho alboroto; es posible que hayas visto las protestas en las noticias. Personas que estaban en contra del proyecto de ley hicieron su caso de diversas maneras. Una de las líneas de ataque fue económica: privar a tantos residentes de Wisconsin de tanto dinero dañaría la economía del estado y causaría pérdidas de empleos (los trabajadores estatales gastarían menos, lo que perjudicaría los resultados de las empresas locales, lo que haría que despidieran a sus empleados). Un artículo periodístico en su momento citaba a un profesor de economía que afirmó que el proyecto de ley del Gobernador le costaría al estado 21 mil 843 empleos. (Steven Verburg, “Estudio: el presupuesto podría dañar la economía del estado”, 20 de marzo de 2011, Wisconsin State Journal.) No 21, 844 empleos; no es tan malo. Sólo 21,843. Este número suena impresionante; es muy preciso. Pero claro que esa precisión es espuria. Estimar los efectos económicos de las políticas públicas es un negocio sumamente incierto. No sé qué tipo de modelo estaba utilizando este economista para hacer su estimación, pero sea lo que sea, es imposible que sus resultados sean lo suficientemente confiables como para reportar tantos dígitos significativos. Mi conjetura es que en el mejor de los casos el 2 en 21,843 tiene algún significado en absoluto.
Porcentajes difíciles
Los argumentos estadísticos están llenos de porcentajes, y hay muchas maneras de engañar a la gente con ellos. La clave para no dejarse engañar por este tipo de cifras, por lo general, es tener en cuenta de qué es un porcentaje. Números inapropiados, cambiantes o elegidos estratégicamente pueden darte porcentajes engañosos.
Cuando los números son muy pequeños, usar porcentajes en lugar de fracciones es engañoso. La Escuela de Medicina Johns Hopkins, cuando se inauguró en 1893, fue una de las pocas escuelas de medicina que permitía a las mujeres matricularse. (No porque la administración de la escuela fuera particularmente esclarecida. Sólo pudieron abrir con el apoyo económico de cuatro mujeres adineradas que hicieron de esto una condición para sus donaciones.) En esos tiempos benignos, a la gente le preocupaba que las mujeres se inscribieran en escuelas con hombres por diversas razones tontas. Una de ellas era el temor de que las señoritas impresionables se enamoraran de sus profesores y se casaran con ellos. Absurdo, ¿verdad? Bueno, tal vez no: ¡en la primera clase para inscribirse en la escuela, 33% de las mujeres efectivamente se casaron con sus profesores! Al parecer, los sexistas tenían razón. Esa cifra suena impresionante, hasta que aprendes que el denominador es 3. Tres mujeres se inscribieron en Johns Hopkins ese primer año, y una de ellas se casó con su profesor de anatomía. Usar el porcentaje en lugar de la fracción exagera de manera engañosa. Otro ejemplo maquillado: vivo en un pueblito relativamente seguro. Si viera un titular en mi periódico local que dijera “Los robos a mano armada están arriba al 100% respecto del año pasado” estaría bastante alarmado. Es decir, hasta que me di cuenta de que el año pasado hubo un robo a mano armada en la ciudad, y este año hubo dos. Eso es un incremento del 100%, pero usar el porcentaje de un número tan pequeño es engañoso.
Puedes engañar a la gente cambiando el número que estás tomando un porcentaje de mid-stream. Supongamos que usted es un empleado de mi mencionado LogiCorp. Evalúa argumentos por $10.00 por hora. Un día, convoco a todos mis empleados para una reunión. La economía ha dado un giro para peor, lo anuncio, y tenemos menos argumentos entrando para la evaluación; los negocios se están desacelerando. Sin embargo, no quiero despedir a nadie, así que sugiero que todos compartamos el dolor: recortaré el salario de todos en un 20%; pero cuando la economía vuelva a recuperarse, te lo compensaré. Entonces aceptas ir de acuerdo con este plan, y sufres a través de un año de hacer apenas $8.00 por hora evaluando argumentos. Pero cuando se acaba el año, convoco a todos y anuncio que las cosas han ido mejorando y estoy listo para arreglar las cosas: a partir de hoy, todos obtienen un aumento del 20%. Primero un recorte del 20%, ahora un aumento del 20%; volvemos a donde estábamos, ¿verdad? Mal. Cambié los números mid- stream. Cuando recorté tu paga inicialmente, tomé veinte por ciento de $10.00, lo que es una reducción de $2.00. Cuando te di un aumento, te di el veinte por ciento de tu tarifa de pago reducido de $8.00 por hora. Eso es sólo $1.60. Su tarifa de pago final es de apenas $9.60 por hora. (Este ejemplo inspirado en Huff 1954, pp. 110 - 111.)
A menudo, las personas toman una decisión estratégica sobre qué número tomar un porcentaje, eligiendo el que les dé una figura más impactante, retóricamente efectiva. Supongamos que yo, como director general de LogiCorp, me fijé una meta ambiciosa para la compañía durante el próximo año: propongo que aumentemos nuestra productividad de 800 argumentos evaluados por día a 1,000 argumentos diarios. Al final del año, estamos evaluando 900 argumentos diarios. No alcanzamos nuestra meta, pero sí hicimos una mejora. En mi informe anual a los inversionistas, proclamo que tuvimos 90% de éxito. Eso suena bien; 90% está muy cerca del 100%. Pero es engañoso. Elegí tomar un porcentaje de mil: 900 dividido por 1,000 nos dan 90%. Pero, ¿es esa la forma apropiada de medir el grado en que cumplimos con la meta? Quería aumentar nuestra producción de 800 a 1,000; es decir, quería un incremento total de 200 argumentos diarios. ¿Cuánto de un aumento realmente obtuvimos? Pasamos de 800 a 900; eso es un incremento de 100. Nuestro objetivo era 200, pero sólo conseguimos hasta 100. Es decir, sólo llegamos al 50% de nuestra meta. Eso no suena tan bien.
Otro caso de elecciones estratégicas. Los opositores al derecho al aborto podrían señalar que 97% de los ginecólogos en Estados Unidos han tenido pacientes que buscan abortos. Esto crea la impresión de que hay una epidemia de búsqueda de abortos, que ocurre regularmente. Alguien del otro lado del debate podría señalar que solo 1.25% de las mujeres en edad fértil se hacen un aborto cada año. Eso no es una epidemia. Cada uno de los participantes en este debate ha elegido un número conveniente para tomar un porcentaje de. Para el activista antiaborto, ese es el número de ginecólogos. Es cierto que 97% tienen pacientes que buscan abortos; solo 14% de ellos realmente realizan el procedimiento, sin embargo. El 97% exagera la prevalencia del aborto (para lograr un efecto retórico). Para la activista pro-elección, es conveniente tomar un porcentaje del número total de mujeres en edad fértil. Es cierto que una pequeña fracción de ellas consigue abortos en un año determinado; pero hay que tener en cuenta que sólo un pequeño porcentaje de esas mujeres están embarazadas en un año determinado. De hecho, entre las que realmente quedan embarazadas, algo así como el 17% tienen un aborto. El 1.25% minimiza la prevalencia del aborto (nuevamente, para lograr un efecto retórico).
La falacia de la tasa base
La tasa base es la frecuencia con la que ocurre algún tipo de evento, o se observa algún tipo de fenómeno. Cuando ignoramos esta información, o nos olvidamos de ella, cometemos una falacia y cometemos errores en el razonamiento.
La mayoría de los accidentes automovilísticos ocurren a plena luz del día, a bajas velocidades y cerca de casa. Entonces, ¿eso significa que estoy más seguro si conduzco muy rápido, de noche, bajo la lluvia, lejos de mi casa? Por supuesto que no. Entonces, ¿por qué hay más accidentes en las condiciones anteriores? Las tarifas base: mucho más de nuestro tiempo de manejo lo pasamos a bajas velocidades, durante el día, y cerca de casa; relativamente poco se gasta manejando rápido por la noche, bajo la lluvia y lejos de casa. (Este ejemplo inspirado en Huff 1954, pp. 77 - 79.)
Considera a una mujer anteriormente conocida como Mary (cambió su nombre a Moon Flower). Es pacifista comprometida, vegana y ambientalista; es voluntaria con Green Peace; su ejercicio favorito es el yoga. ¿Cuál es más probable: que sea autora best-seller de la nueva era, medicina alternativa, libros de autoayuda, o que sea mesera? Si respondiste que es más probable que sea una autora más vendida de libros de autoayuda, fuiste víctima de la falacia de tasa base. Concedido, Moon Flower se ajusta al estereotipo del tipo de persona que sería el autor de este tipo de libros a la perfección. Sin embargo, es mucho más probable que una persona con esas características sea mesera que un autor de best-sellers. ¿Por qué? Tasas base. Hay lejos, lejos (¡lejos! ) más camareras en el mundo que autores más vendidos (de la nueva era, medicina alternativa, libros de autoayuda). La tasa base de camarera es mayor que la de autoría más vendida en muchos órdenes de magnitud.
Supongamos que hay una prueba de detección médica para una enfermedad grave que es muy precisa: solo produce falsos positivos el 1% de las veces, y solo produce falsos negativos el 1% del tiempo (es altamente sensible y altamente específico). La enfermedad es grave, pero rara: solo ocurre en 1 de cada 100 mil personas. Supongamos que te hacen pruebas de detección de esta enfermedad y tu resultado es positivo; es decir, estás marcado como posiblemente teniendo la enfermedad. Dado lo que sabemos, ¿cuál es la probabilidad de que estés realmente enfermo? No es del 99%, a pesar de la precisión de la prueba. Es mucho más baja. Y puedo probarlo, usando la ley de nuestro viejo amigo Bayes'. La clave para ver por qué la probabilidad es muy inferior al 99%, como veremos, es tomar en cuenta la tasa base de la enfermedad.
Hay dos hipótesis a considerar: que estás enfermo (llámalo 'S') y que no estás enfermo (~ S). La evidencia que tenemos es un resultado positivo en la prueba (P). Queremos saber la probabilidad de que estés enfermo, dada esta evidencia: P (S | P). La Ley de Bayes nos dice cómo calcular esto:
\[\mathrm{P}(\mathrm{S} | \mathrm{P})=\frac{\mathrm{P}(\mathrm{S}) \times \mathrm{P(P|S)}}{\mathrm{P(S)} \times \mathrm{P}(\mathrm{P} | \mathrm{S})+\mathrm{P}(\sim \mathrm{S}) \times \mathrm{P}(\mathrm{P} | \sim \mathrm{S})}\]
La tasa base de la enfermedad es la tasa a la que se presenta en la población general. Es raro: solo ocurre en 1 de cada 100 mil personas. Este número corresponde a la probabilidad previa de la enfermedad en nuestra fórmula P (S). Tenemos que multiplicar en el numerador por 1/100,000; esto tendrá el efecto de mantener baja la probabilidad de enfermedad, incluso dado el resultado positivo de la prueba. ¿Y los otros términos de nuestra ecuación? 'P (~ S) 'solo selecciona la probabilidad previa de no estar enfermo; si P (S) = 1/100,000, entonces P (~ S) = 99,999/100,000. 'P (P | S) 'es la probabilidad de que obtengas un resultado positivo en la prueba, asumiendo que de hecho estabas enfermo. Nos dicen que la prueba es muy precisa: solo le dice a las personas enfermas que están sanas 1% del tiempo (1% de tasa de falsos negativos); por lo que la probabilidad de que una persona enferma obtenga un resultado positivo en la prueba es del 99% —P (P | S) = .99. 'P (P | ~ S) 'es la probabilidad de que obtendrías un resultado positivo si no estuvieras enfermo. Esa es la tasa de falsos positivos, que es 1% — P (P | ~ S) = .01. Al enchufar estos números a la fórmula, obtenemos el resultado de que P (S | P) = .000999. Así es, dado un resultado positivo de esta prueba de detección muy precisa, la probabilidad de estar enfermo es poco menos de 1/10,000. La prueba es precisa, pero la enfermedad es tan rara (su tasa base es tan baja) que tus probabilidades de enfermarte siguen siendo muy bajas incluso después de un resultado positivo.
A veces la gente ignorará las tarifas base a propósito para tratar de engañarte. ¿Sabías que la marihuana es más peligrosa que la heroína? Yo tampoco. Pero mira este gráfico:
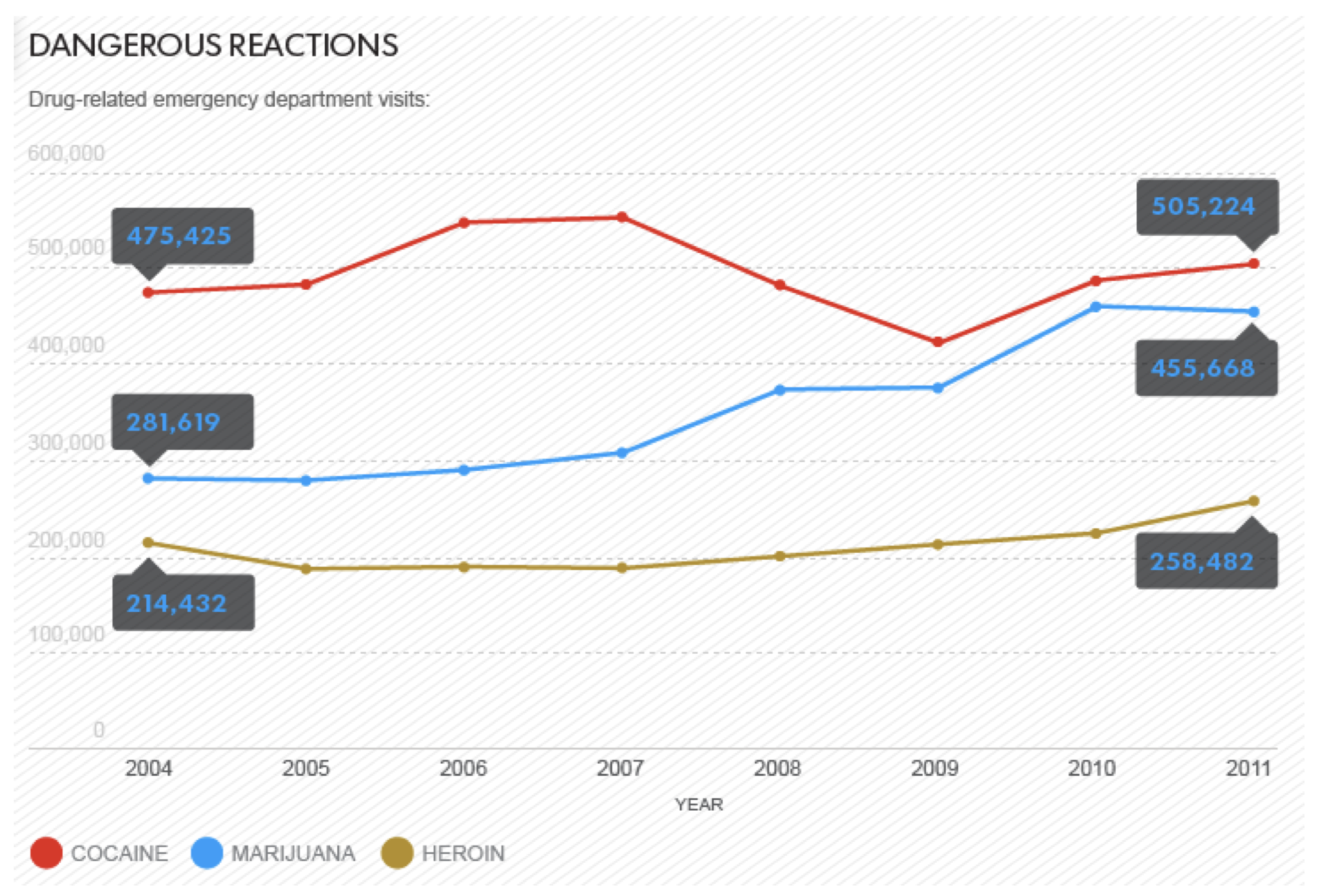
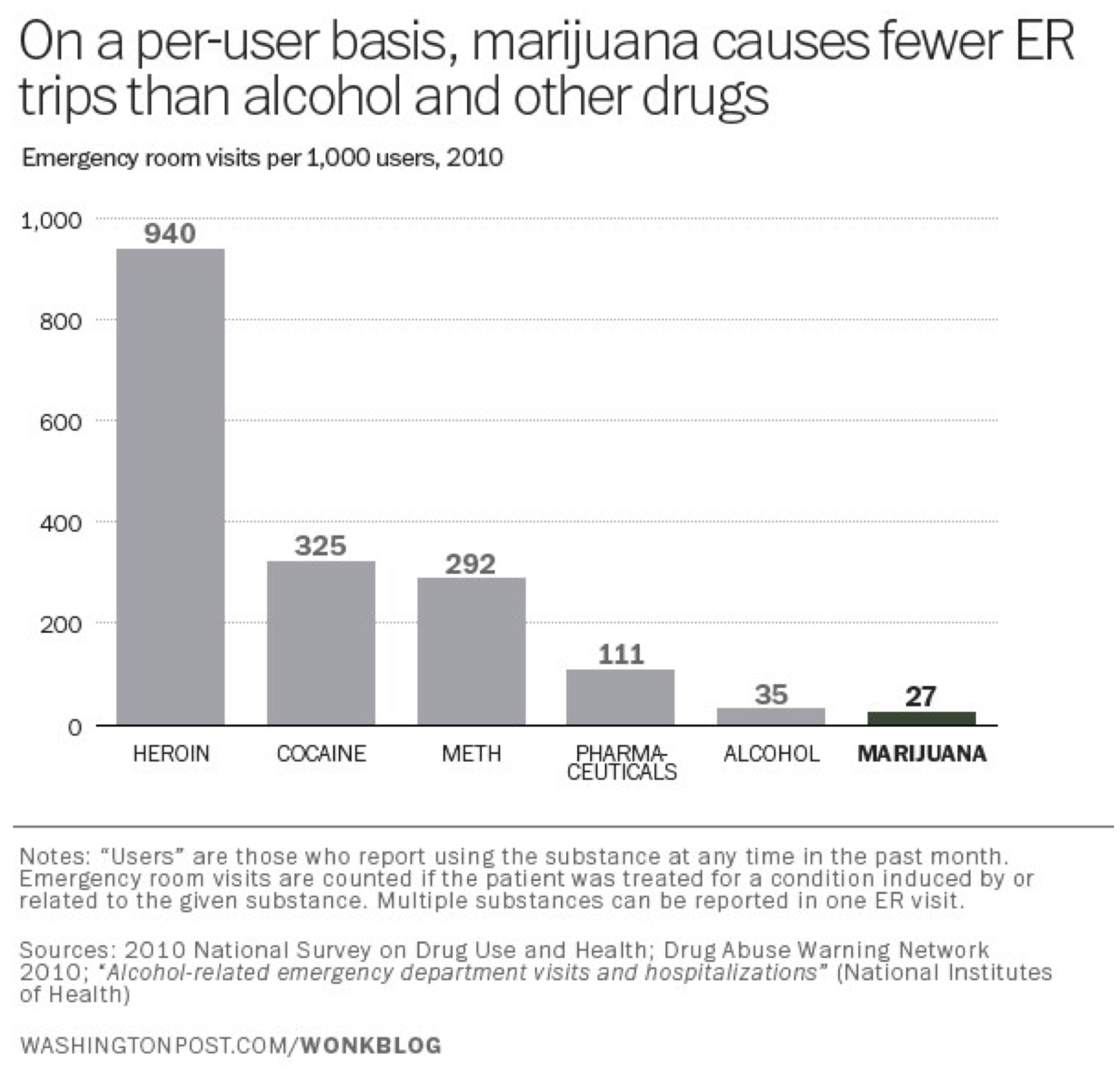
Ese gráfico publicado en una historia en USA Today bajo el titular “La marihuana plantea más riesgos de los que muchos se dan cuenta”. (Liz Szabo, “La marihuana plantea más riesgos de los que muchos se dan cuenta”, 27 de julio de 2014, USA Today. http://www.usatoday.com/story/news/n.../? sf29269095=1) El combo gráfico/titular crea una impresión alarmante: si tanta gente va a urgencias por la marihuana, debe ser más peligroso de lo que me di cuenta. Mira eso: más del doble de visitas a la sala de emergencias por marihuana que por heroína; ¡es casi tan malo como la cocaína! O tal vez no. Lo que este gráfico ignora son las tasas base de consumo de marihuana, cocaína y heroína en la población. Lejos (¡lejos!) más personas consumen marihuana que consumen heroína o cocaína. Una medida más verdadera de los peligros relativos de los diversos medicamentos sería el número de visitas a la sala de emergencias por usuario. Eso te da una tabla muy diferente (del alemán López, “La marihuana envía a más gente a la sala de emergencias que la heroína. Pero esa no es toda la historia”. 2 de agosto de 2014, Vox.com. http://www.vox.com/2014/8/2/5960307/...roin-USA-Today):
Mentir con fotos
Hablando de gráficos, son otra herramienta que puede ser utilizada (abusada) para hacer argumentos estadísticos dudosos. A menudo usamos gráficos y otras imágenes para transmitir gráficamente información cuantitativa. Pero debemos tener especial cuidado de que nuestras imágenes representen con precisión esa información. Hay todo tipo de formas en las que las presentaciones gráficas de datos pueden distorsionar el estado real de las cosas y engañar a nuestra audiencia.
Consideremos, una vez más, mi compañía ficticia, LogiCorp. El negocio ha ido mejorando últimamente, y estoy buscando conseguir algunos inversionistas externos para poder crecer aún más rápido. Entonces decido ir a ese programa de televisión Shark Tank. Ya sabes, el que tiene Mark Cuban y panel de otros ricos, donde les haces una presentación y ellos deciden si vale la pena invertir o no en tu idea. En fin, necesito planear una presentación persuasiva para convencer a uno de los tiburones de que me dé un montón de dinero para LogiCorp. Voy a usar una gráfica para impresionarlos con el potencial de crecimiento futuro de la compañía. Aquí hay una gráfica de mis ganancias en la última década:
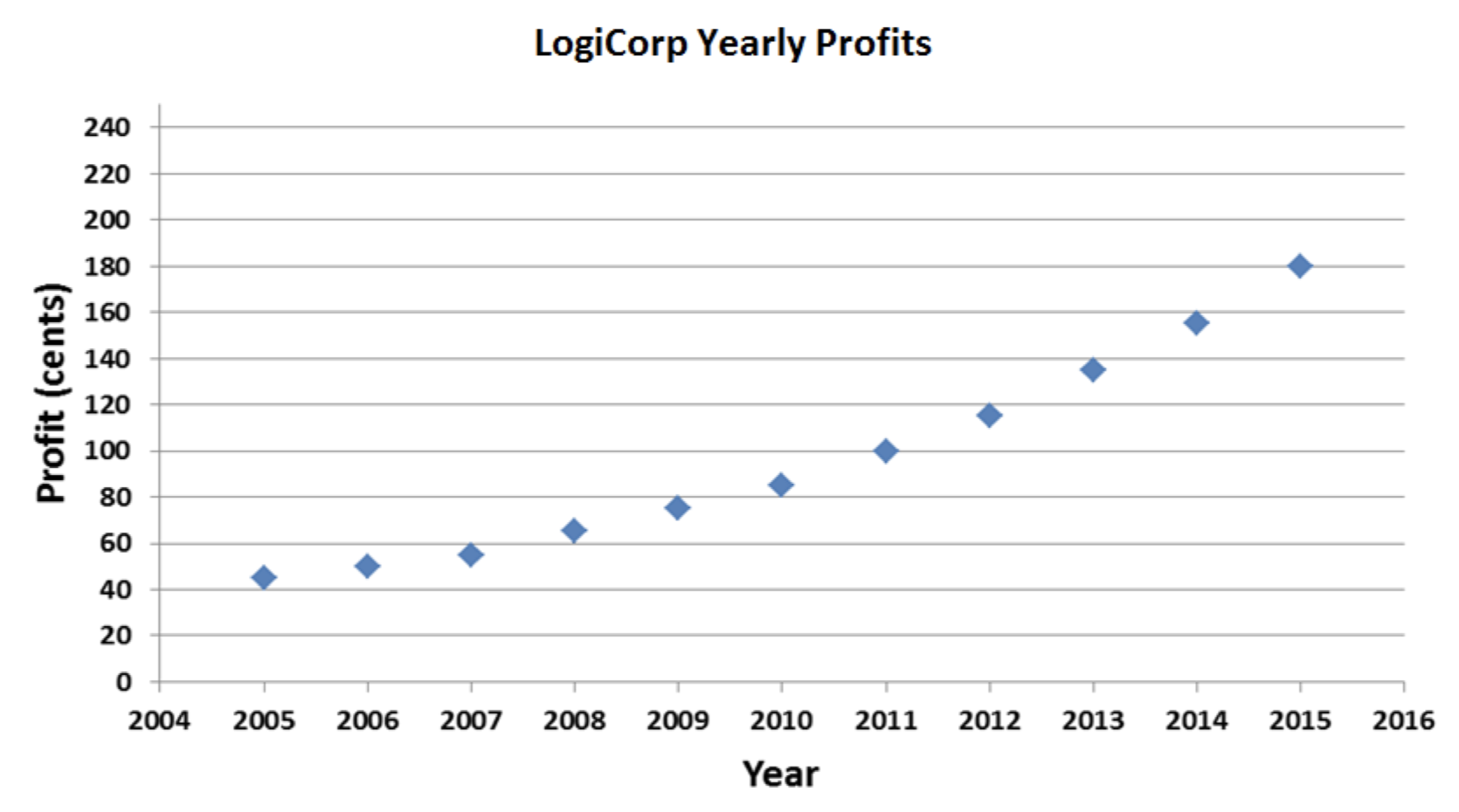
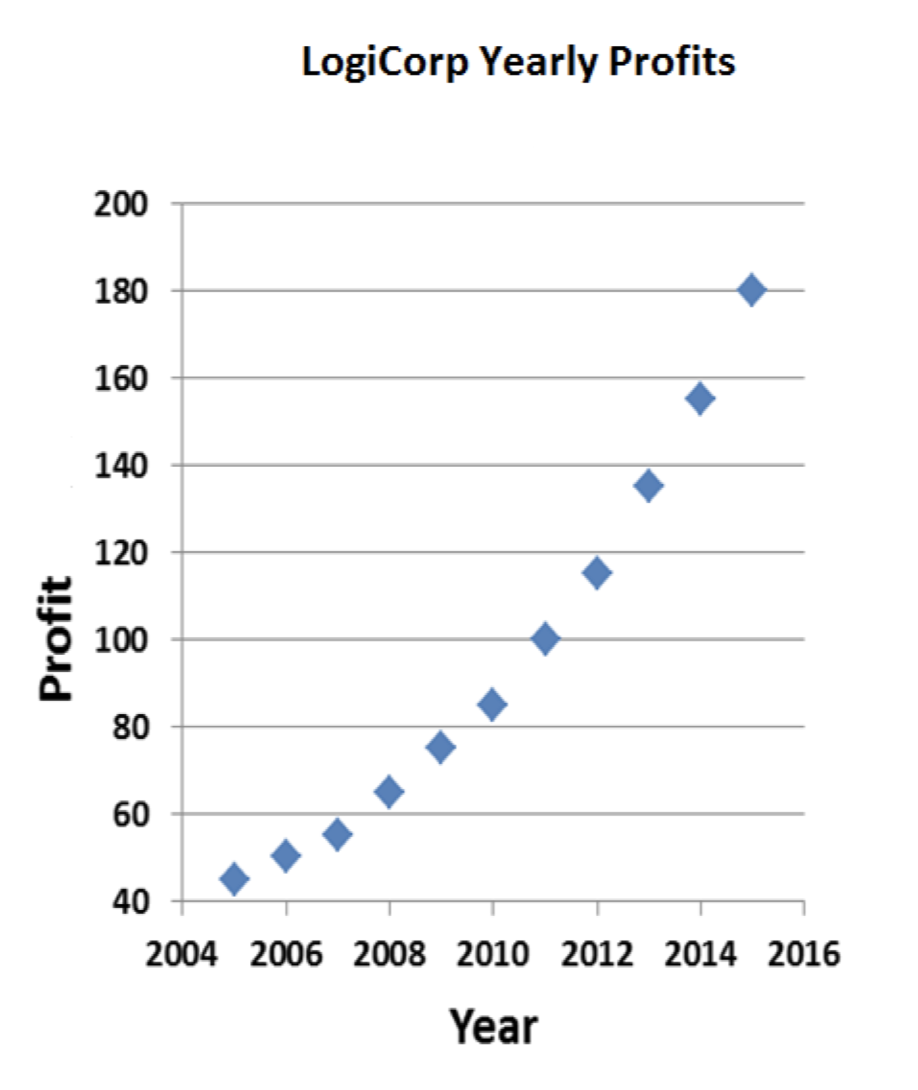
No está mal. Pero tampoco genial. La tendencia positiva en las ganancias es claramente visible, pero estaría bien si pudiera hacerla parecer un poco más dramática. Voy a retocar las cosas un poco:
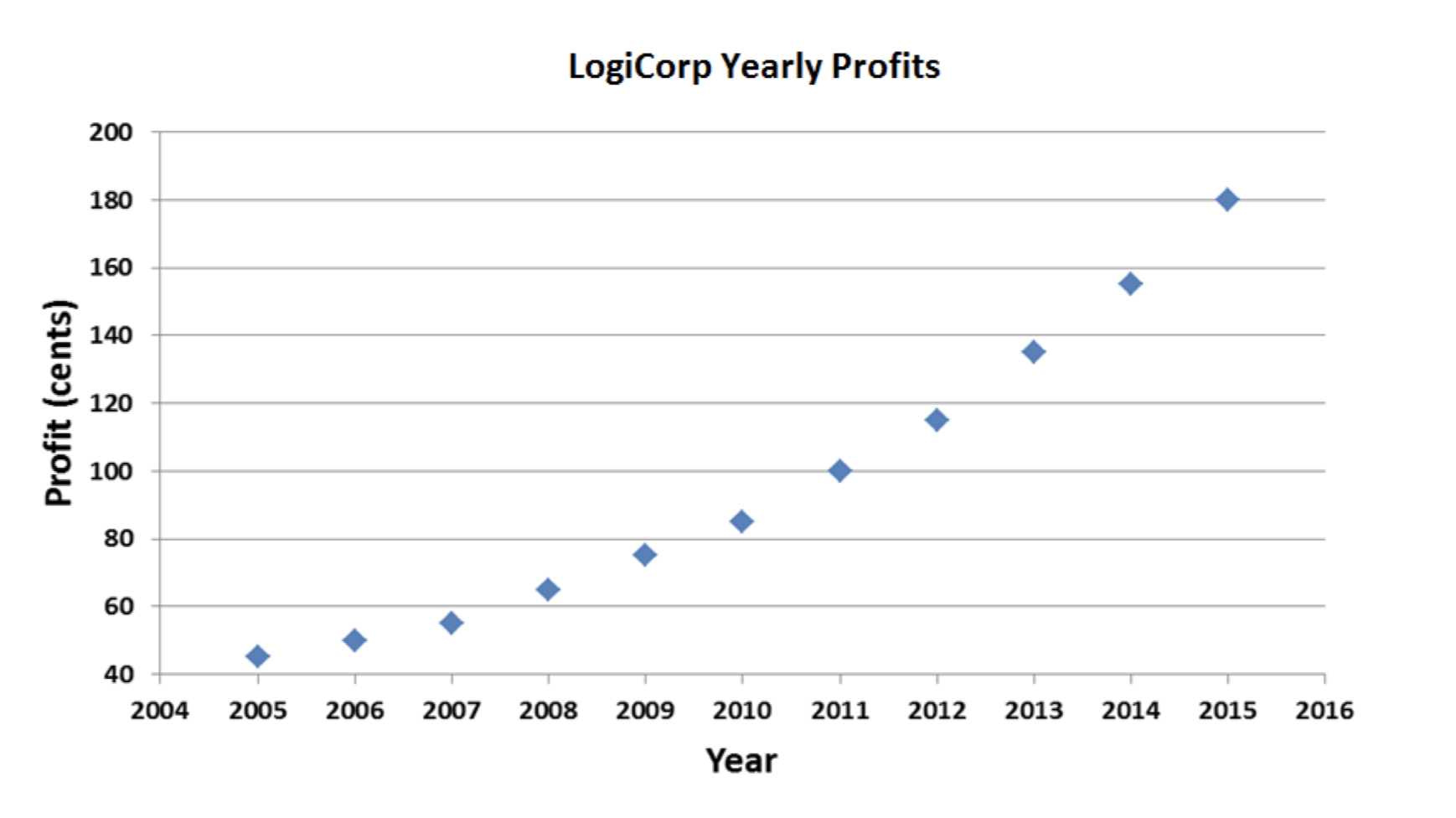
Mejor. Todo lo que hice fue ajustar el eje y. No hay razón por la que tiene que bajar hasta cero y hasta 240. Ahora se acentúa la pendiente ascendente; parece que LogiCorp está creciendo más rápidamente.
Pero creo que puedo hacerlo aún mejor. ¿Por qué el eje x tiene que ser tan largo? Si comprimiera la gráfica horizontalmente, mi curva se inclinaría aún más dramáticamente:
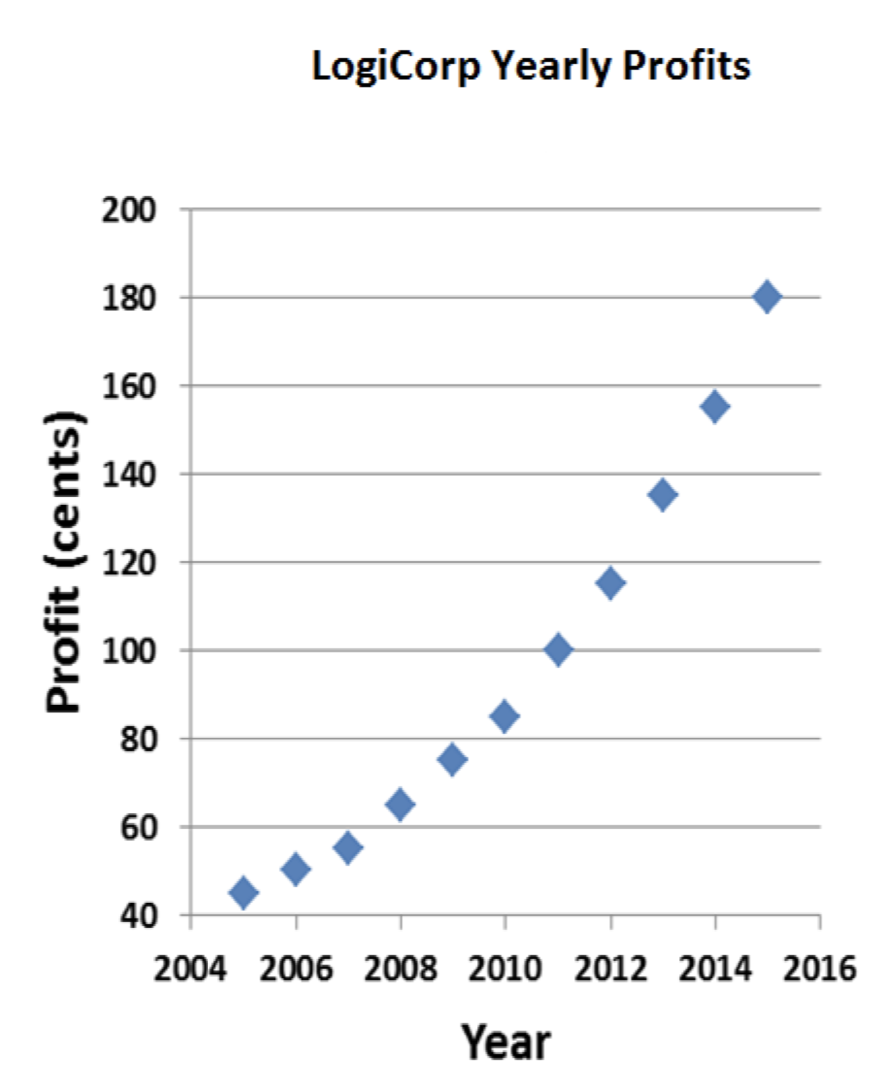
¡Ahora eso es crecimiento explosivo! A los tiburones les va a encantar esto. Bueno, es decir, siempre y cuando no miren demasiado de cerca el gráfico. Ganancias del orden de $1.80 anuales no van a impresionar a un multimillonario como Mark Cuban. Pero puedo arreglarlo:
Ahí. Para todos esos tiburones saben, las ganancias se miden en millones de dólares. Por supuesto, a pesar de todas mis manipulaciones, todavía pueden ver que las ganancias han aumentado 400% a lo largo de la década. Eso es bastante bueno, claro, pero tal vez pueda dejar un poco de espacio para que llenen mentalmente números más impresionantes:
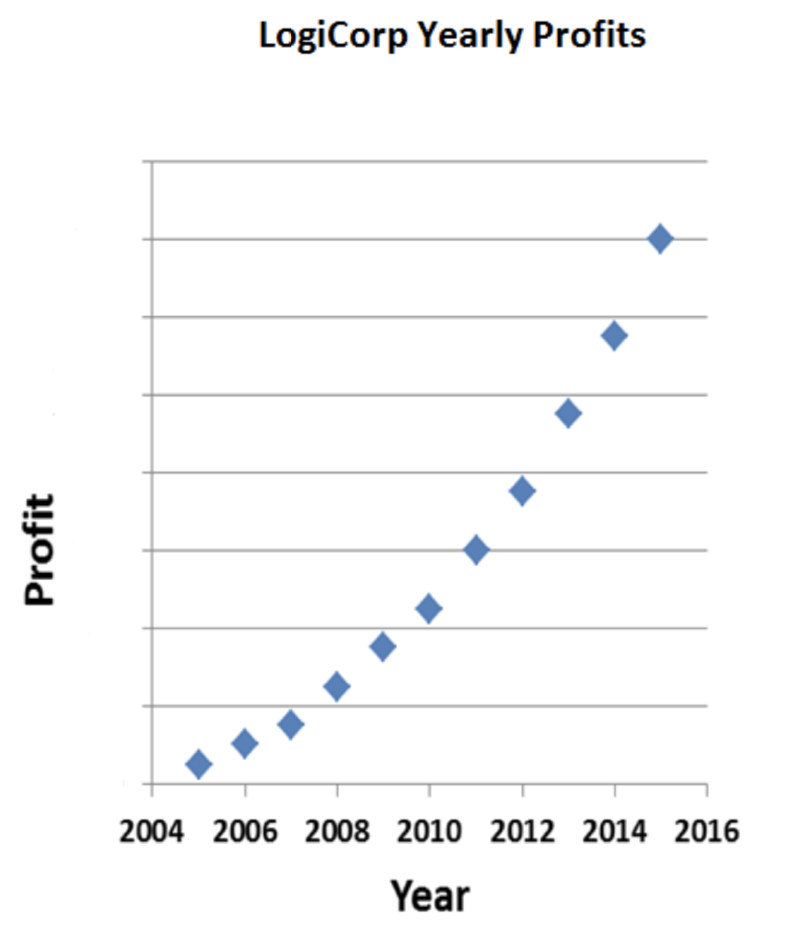
Ese es el indicado. Aumentaron las ganancias, y parece que empezaron cerca de cero y subieron a, bueno, realmente no podemos decir. A lo mejor esas líneas horizontales suben en incrementos de 100, o 1,000. Las ganancias de LogiCorp podrían ser inimaginablemente altas.
La gente manipula el eje y de las cartas para obtener un efecto retórico todo el tiempo. En su documento “Pledge to America” de 2010, el Partido Republicano se comprometió a perseguir diversas prioridades políticas si lograban lograr una mayoría en la Cámara de Representantes (lo cual hicieron). Incluyeron la siguiente tabla en ese diagrama para ilustrar que el gasto gubernamental estaba fuera de control:
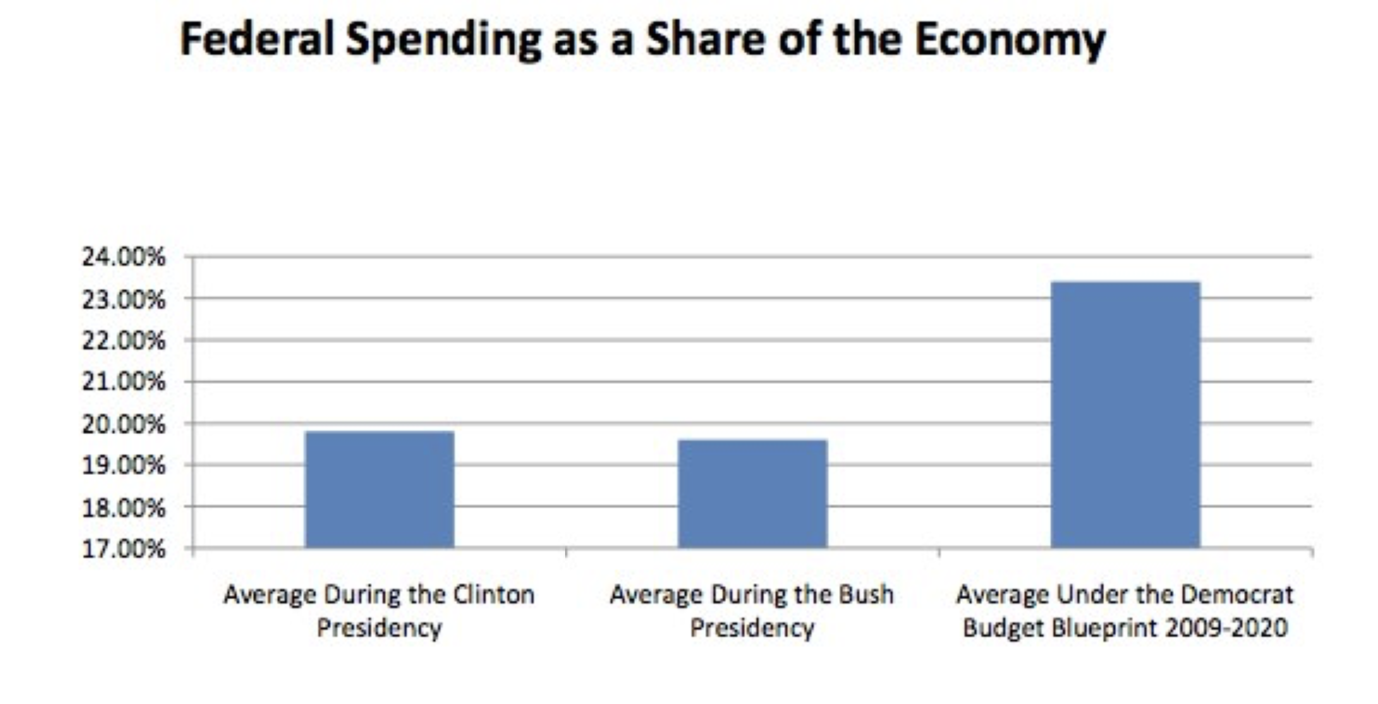
Al escribir para Nueva República, Alexander Hart señaló que la gráfica de los republicanos, al iniciar el eje y en 17% y sólo subir al 24%, exagera la magnitud del incremento. Ese listón de la derecha es más del doble de grande que los otros dos, pero el gasto federal no se había duplicado. Produjo la siguiente presentación alternativa de los datos (Alexander Hart, “Mentir con gráficos, estilo republicano (Ahora con 50% más gráficos)”, 22 de diciembre de 2010, Nueva República. https://newrepublic.com/article/7789...publican-style):
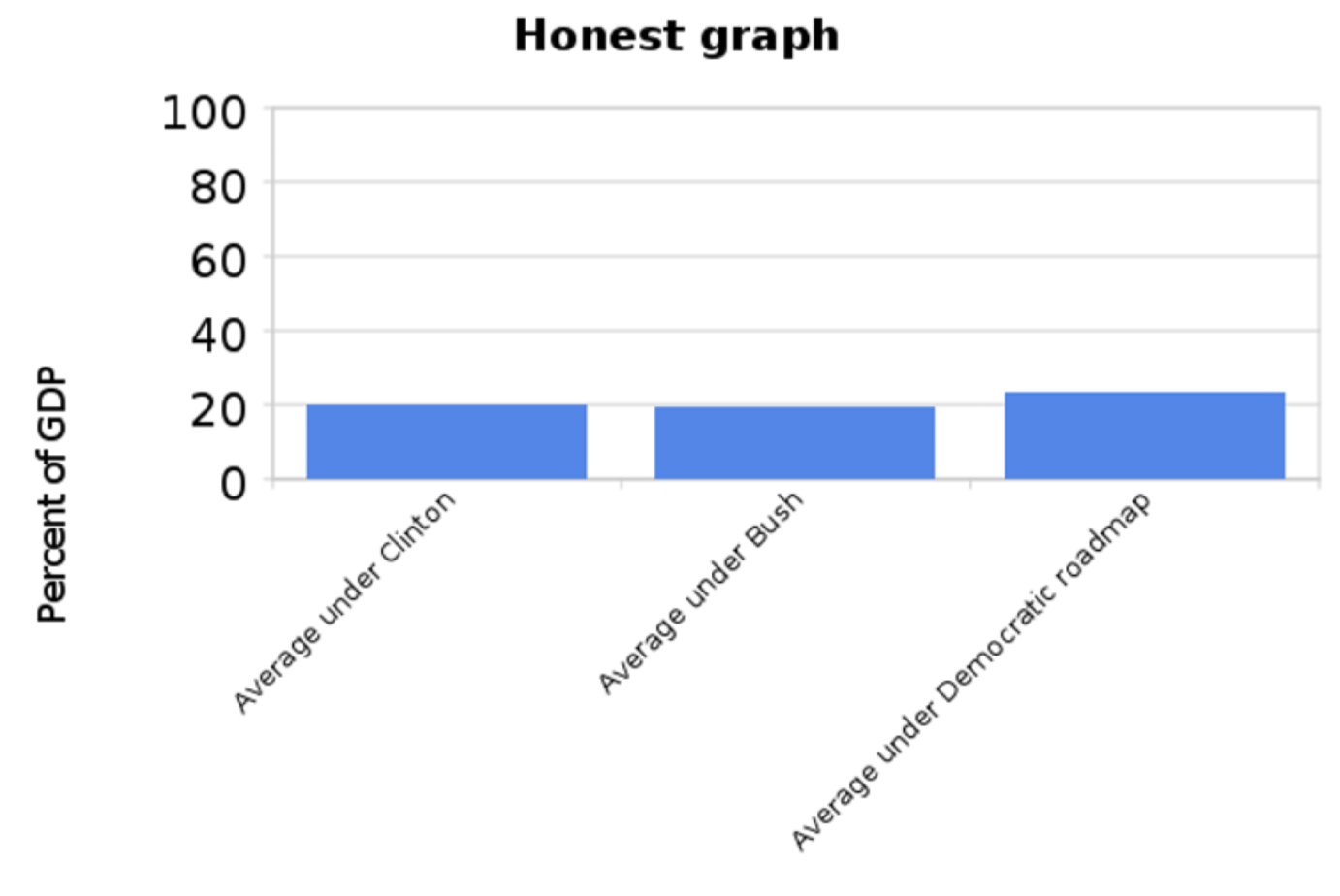
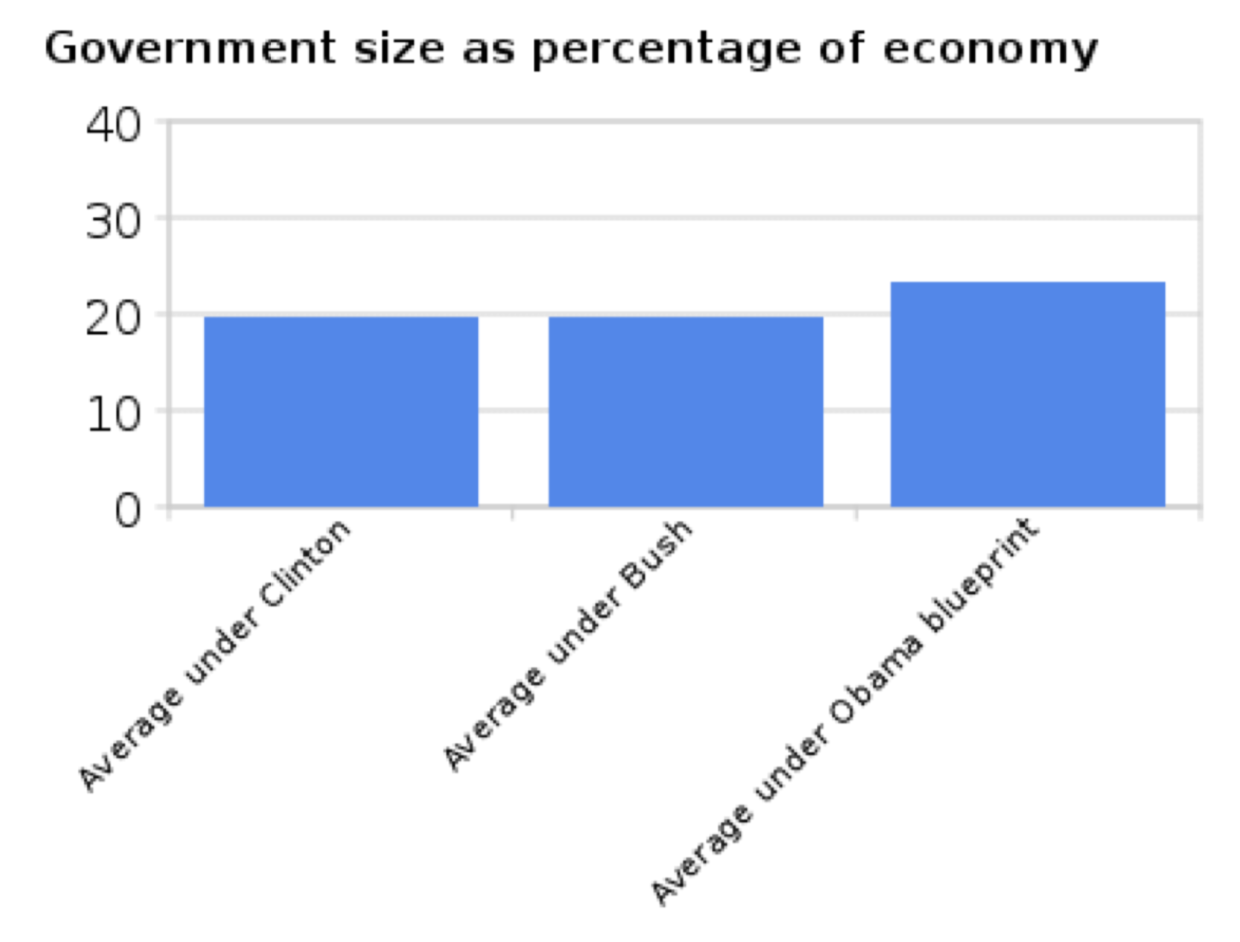
Escribiendo para The Washington Post, el bloguero liberal Ezra Klein pasó a lo largo de la gráfica original y la más “honesta”. Muchos de sus comentaristas (incluido su humilde autor) señalaron que la nueva gráfica era una sobrecorrección de la primera: minimiza el cambio en el gasto al tomar el eje y hasta 100. Produjo una gráfica final que probablemente sea la mejor manera de presentar los datos de gastos (Ezra Klein, “Mentiras, malditas mentiras, y el eje 'Y'”, 23 de septiembre de 2010, The Washington Post. http://voices.washingtonpost.com/ezr...he_y_axis.html):
También se puede hacer travesuras en el eje x. En un editorial de abril de 2011 titulado “Donde está el dinero fiscal”, The Wall Street Journal argumentó que la propuesta del presidente Obama de aumentar los impuestos a los ricos era una mala idea. (Ver aquí: http://www.wsj.com/articles/SB100014...67113524583554) Si realmente se tomaba en serio la recaudación de ingresos, tendría que subir los impuestos a la clase media, ya que ahí es donde está la mayor parte del dinero. Para respaldar esa afirmación, produjeron esta gráfica:
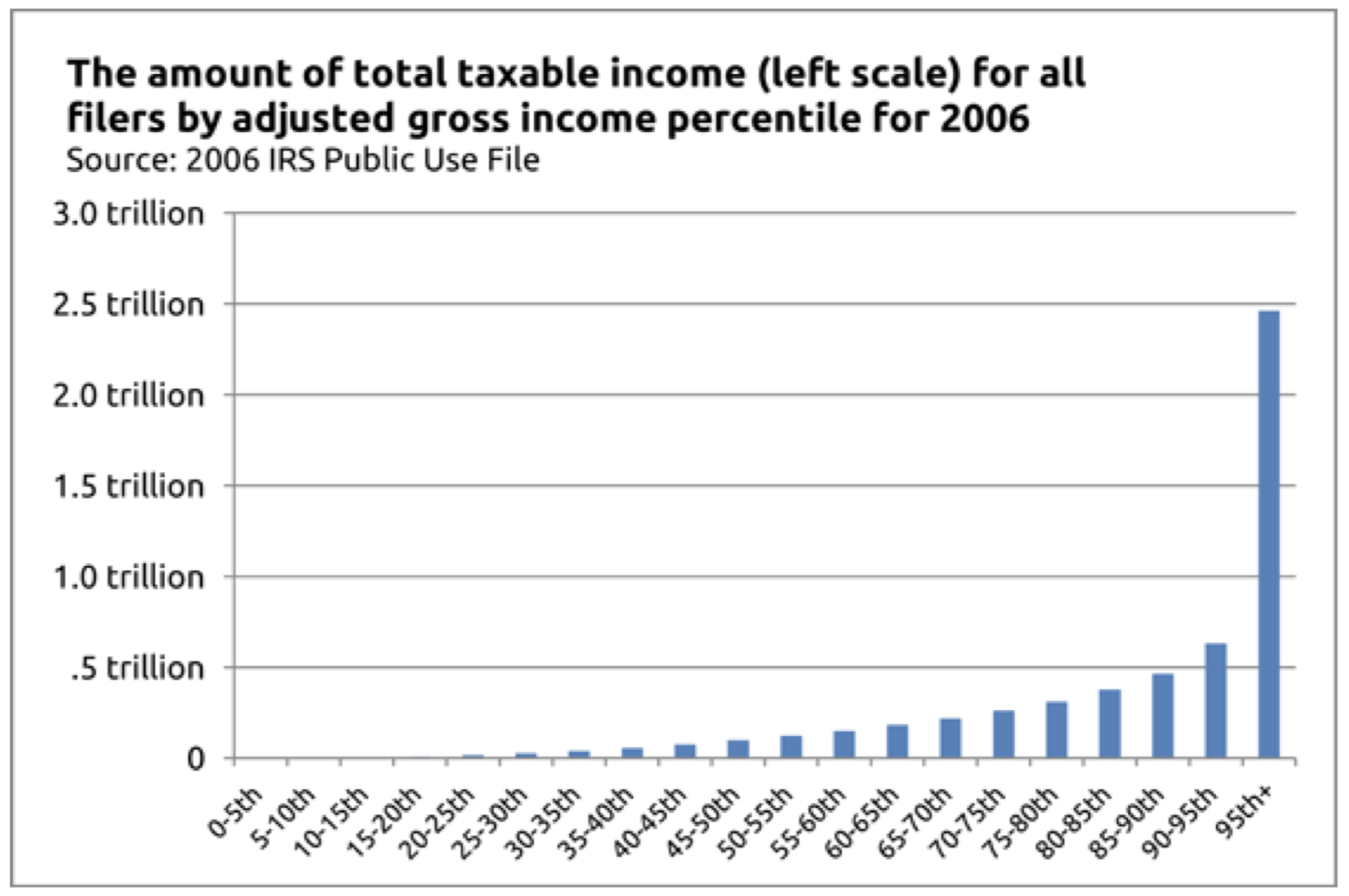
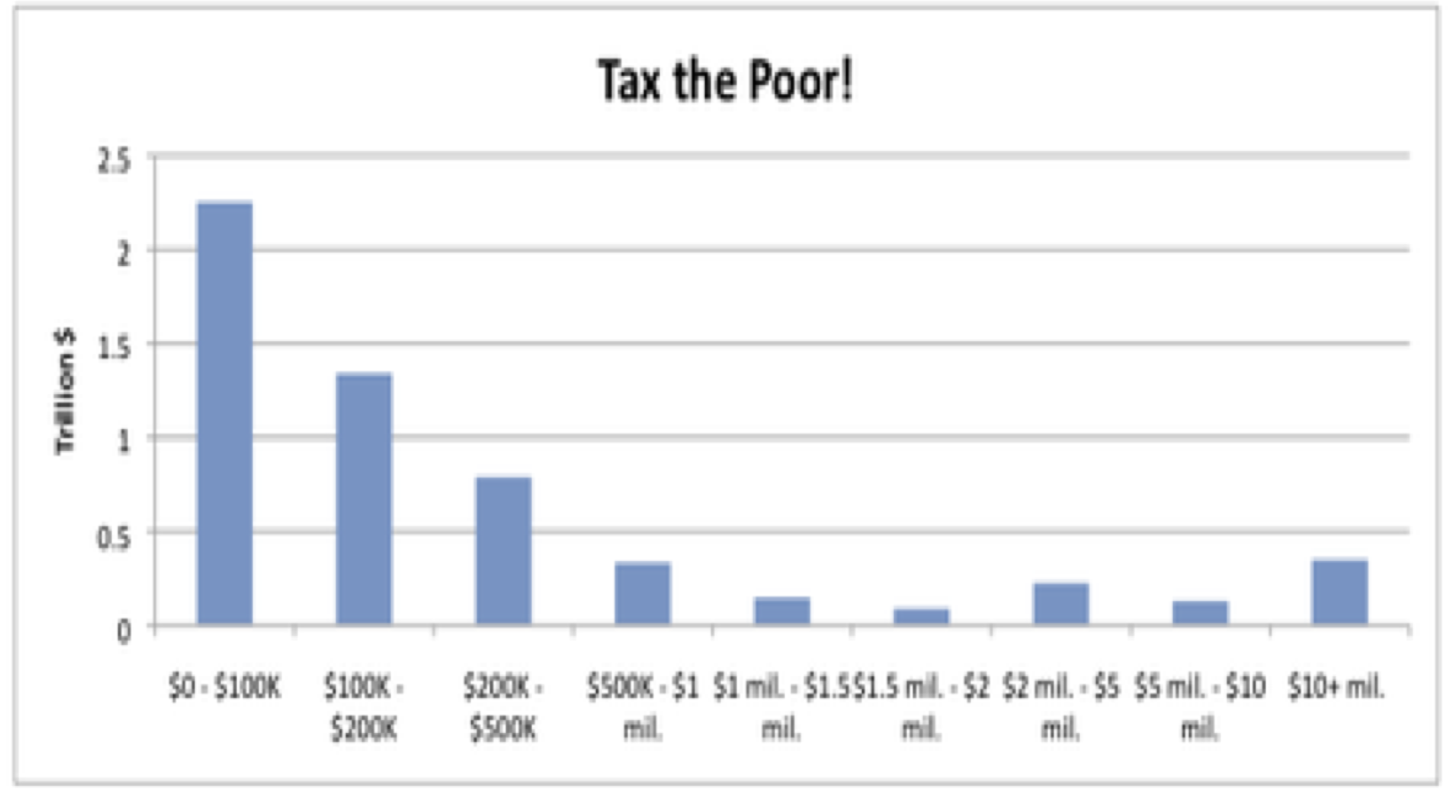
Usando el método de generación de histogramas de The Wall Street Journal, donde cada barra puede representar cualquier número de hogares diferentes, puede “probar” lo que quiera. No es a los ricos ni a la clase media a la que deberíamos perseguir si realmente queremos recaudar ingresos; son los pobres. Ahí es donde está el dinero:
Hay otras formas además de tablas y gráficas para presentar visualmente información cuantitativa: los pictogramas. Existe un método sofisticado y basado en reglas para representar información estadística usando tales imágenes. Fue pionera en la década de 1920 por el filósofo austriaco Otto Neurath, y originalmente se llamó el Método de Viena de Estadística Pictórica (Wiener Methode der Bildstatistik); finalmente llegó a ser conocido como Isotipo (Sistema Internacional de Educación de Imagen Tipográfica). (Ver aquí: https://en.Wikipedia.org/wiki/Isotyp...ture_language)) Los principios del sistema de Neurath fueron tales que impidieron la tergiversación de datos con pictogramas. Quizás la regla más importante es que mayores cantidades deben ser representadas no por imágenes más grandes, sino por un mayor número de imágenes del mismo tamaño. Entonces, por ejemplo, si quisiera representar el hecho de que la producción nacional de petróleo en Estados Unidos se ha duplicado en los últimos años, podría usar la siguiente descripción (llevo años usando este ejemplo en clase, y algo me dice que lo obtuve del libro de otra persona, pero he mirado a través de todos los libros en mis estantes y no lo encuentro. Entonces tal vez lo hice yo mismo. Pero si no lo hice, esta nota al pie reconoce a quien lo hizo. (Si eres esa persona, ¡avísame!)) :

Sería engañoso burlar los principios de Neurath y en su lugar representar el aumento con un barril más grande:

Todo lo que hice fue duplicar el tamaño de la imagen. Pero lo dupliqué en ambas dimensiones: es tanto el doble de ancho como el doble de alto. Además, dado que los barriles de petróleo son objetos tridimensionales, también he representado un barril a la derecha que es el doble de profundo. Lo importante de los barriles de petróleo es la cantidad de petróleo que pueden sostener, su volumen. Al duplicar el cañón en las tres dimensiones, he representado un barril a la derecha que puede contener 8 veces más petróleo que el de la izquierda. Lo que estoy mostrando no es una duplicación de la producción de petróleo; es un aumento de ocho veces.
Por desgracia, la gente rompe las reglas de Neurath todo el tiempo, y termina (intencionalmente o no) exagerando los fenómenos que están tratando de representar. Matthew Yglesias, escribiendo en la revista Architecture, señaló que la “burbuja” habitacional que alcanzó la inflación total en 2006 (cuando se construyeron muchas viviendas) no era tan inusual. Si nos fijamos en la historia reciente, se ven ciclos similares de auge y busto, con periodos de mucha construcción seguidos de periodos de relativamente poco. La revista produjo un gráfico para presentar los datos sobre la construcción de viviendas, e Yglesias hizo un punto para publicarlo en su blog en Slate.com porque pensó que era ilustrativo. (Ver aquí: http://www.slate.com/blogs/moneybox/... _shortage.html) Aquí está el gráfico:

Es una figura llamativa, pero exagera los columpios que intenta representar. Los picogramas se escalan a los números en las casitas (que representan el número de viviendas construidas en los meses dados), pero en ambas dimensiones. Y por supuesto que las casas son objetos tridimensionales, de modo que aunque la imagen no represente la dimensión tridimensional, nuestra mente inconsciente sabe que estos pequeños domisciles tienen volumen. Por lo que la casa de enero de 2006 (2,273) es más de cinco veces más ancha y superior a la casa de abril de 2009 (478). Pero cinco veces en tres dimensiones: 5 x 5 x 5 = 125. La casa de enero de 2006 es más de 125 veces más grande que la casa de abril de 2009; por eso parece que tenemos una mansión al lado de un cobertizo. Hubo oscilaciones en la construcción de viviendas a lo largo de los años, pero no fueron tan grandes como este gráfico los hace parecer.
Una imagen ubicua que es fácil de malinterpretar, no porque alguien rompiera las reglas de Neurath, sino simplemente por cómo pasan las cosas en el mundo, es el mapa de Estados Unidos. Lo que lo hace complicado es que los tamaños de los estados individuales no son proporcionales a sus poblaciones. Esto tiene el efecto de exagerar ciertos fenómenos. Consideremos los resultados finales de la elección presidencial de 2016, en la foto, como suelen ser, con estados que fueron por el candidato republicano en rojo y los que fueron por el demócrata en azul. Esto es lo que obtienes (Fuente de la imagen: https://en.Wikipedia.org/wiki/Electo...United_States)):
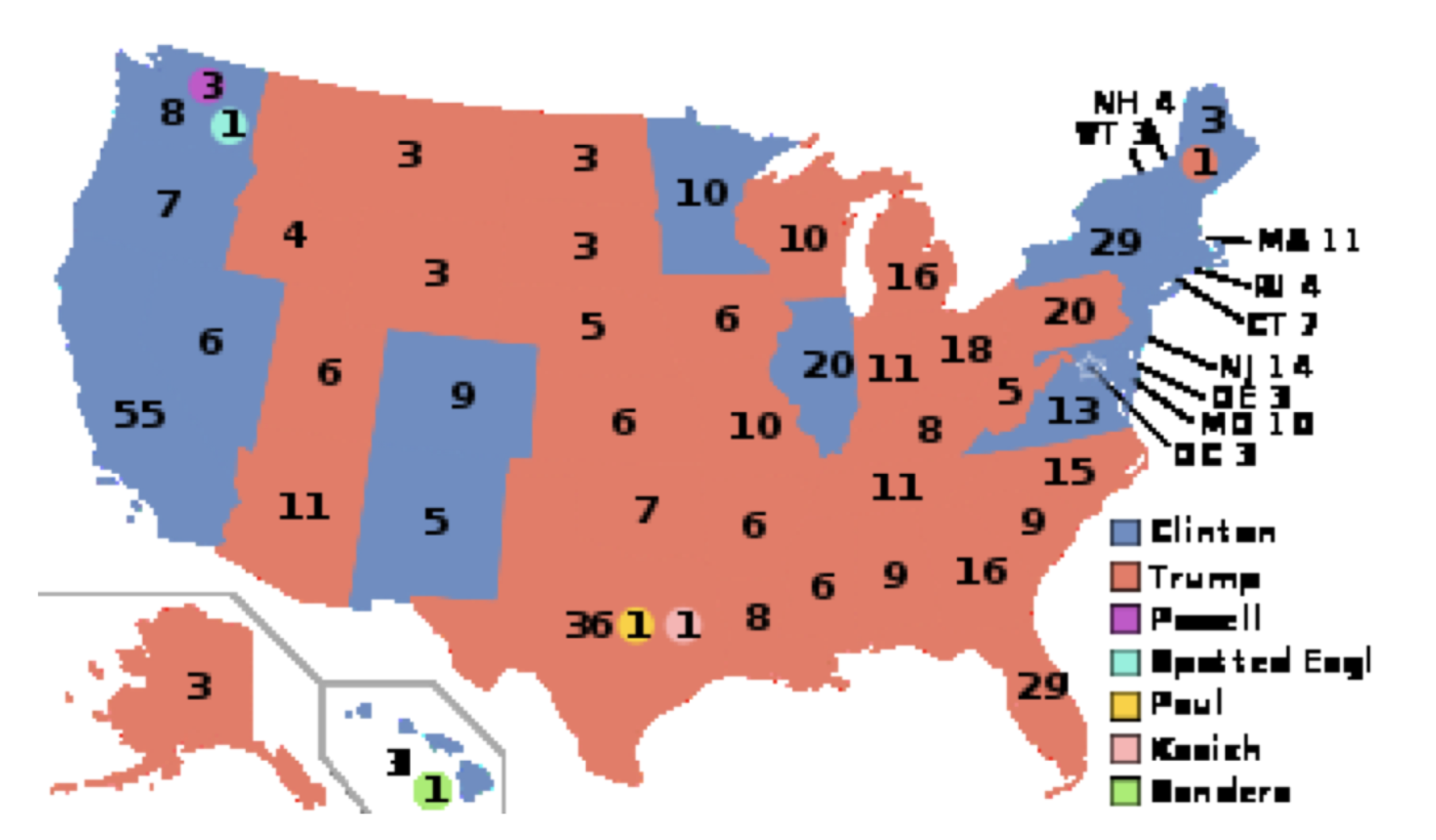
¡Mira todo ese rojo! Clinton al parecer quedó derrotada. Excepto que no lo hizo: ganó el voto popular por más de tres millones. Parece que hay muchos más votos de Trump porque ganó muchos estados que son muy grandes pero que contienen muy pocos votantes. Esos estados de las Grandes Llanuras son enormes, pero casi nadie vive ahí arriba. Si tuvieras que ajustar el mapa, haciendo que los tamaños de los estados sean proporcionales a sus poblaciones, terminarías con algo como esto (Ibid):
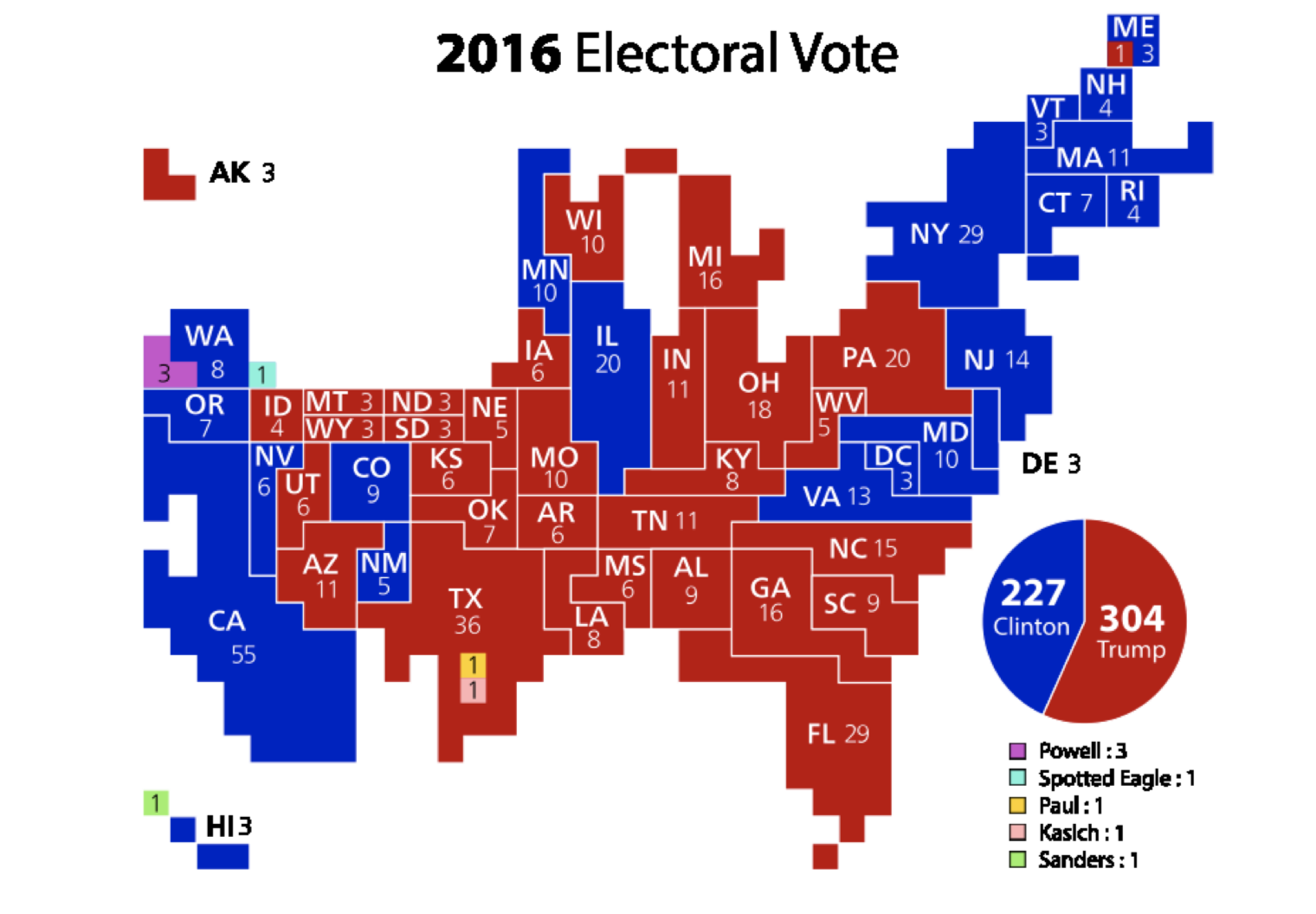
Y esto es sólo una corrección parcial: esto dimensiona los estados por electores en el Colegio Electoral; eso aún exagera los tamaños de algunos de esos estados menos poblados. Un verdadero ajuste tendría que mostrar más azul que rojo, ya que Clinton obtuvo más votos en general.
Terminaré con un ejemplo robado directamente de la inspiración para esta sección: How to Lie with Statistics, de Darrell Huff. (p. 103) Es un mapa de Estados Unidos hecho para dar la alarma sobre la cantidad de gasto que realiza el gobierno federal (se produjo hace más de medio siglo; algunas cosas nunca cambian). Aquí está:
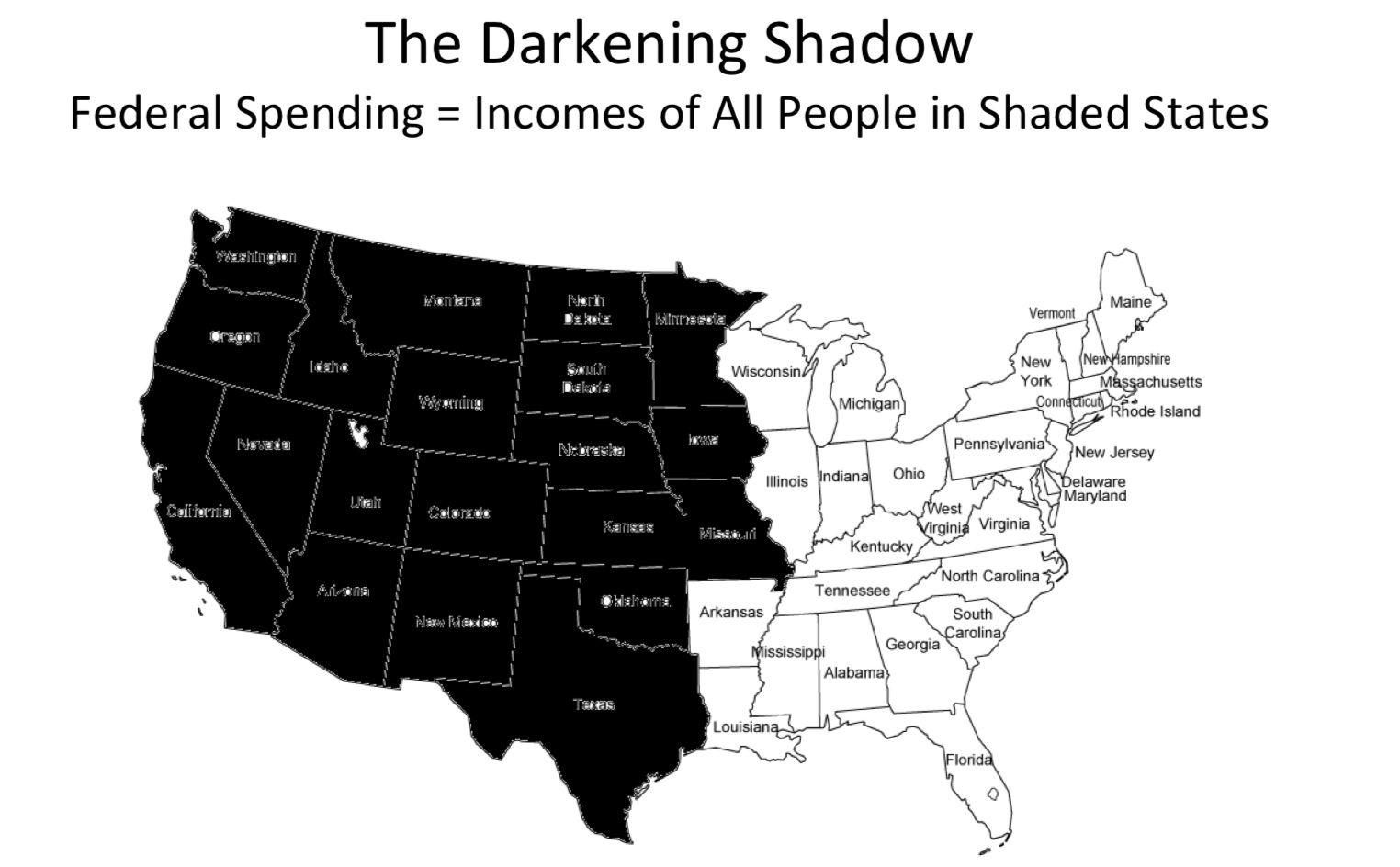
produjo su propio mapa (“estilo oriental”), sombreando diferentes estados, misma población total:
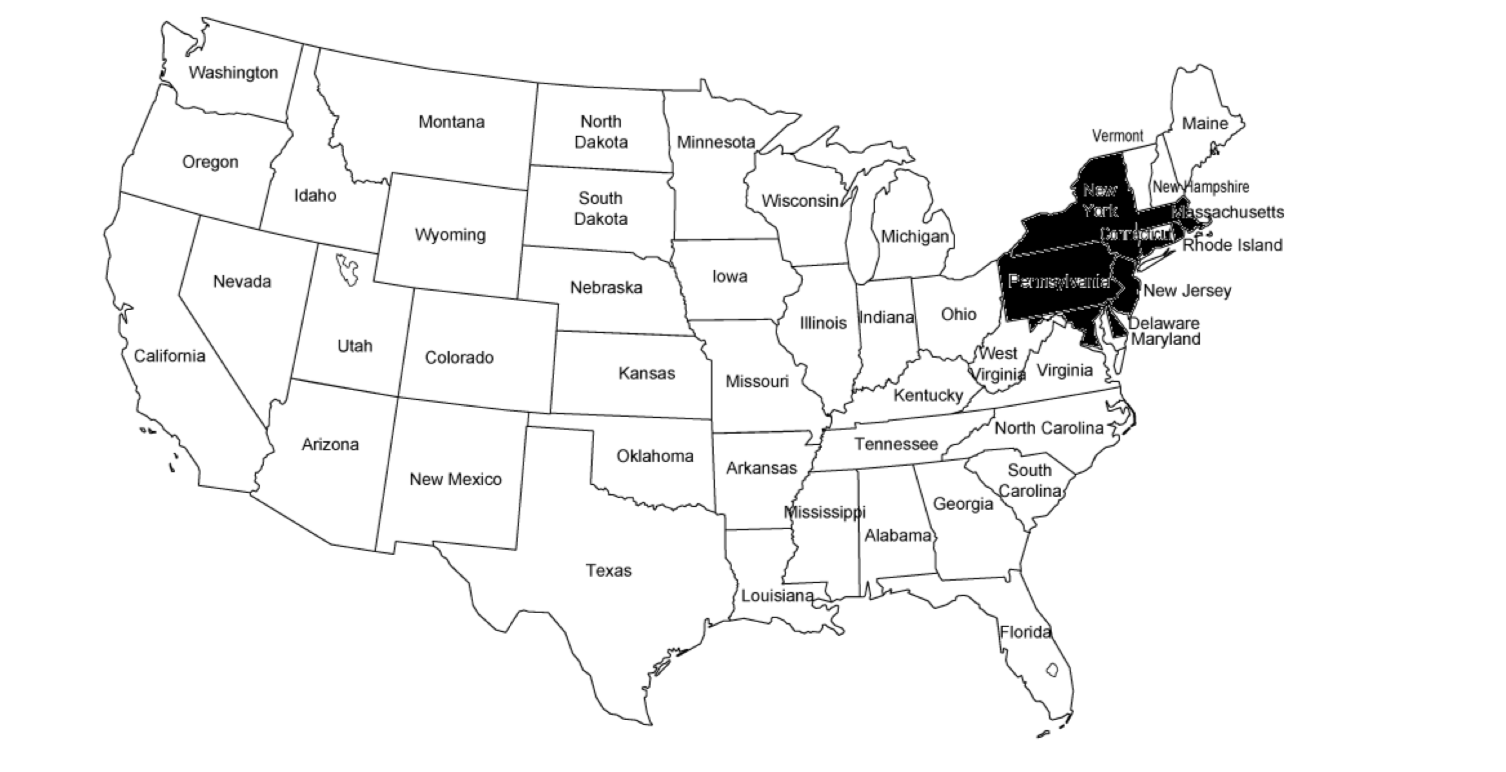
No casi tan alarmante.
La gente trata de engañarte de tantas maneras diferentes. La única defensa es un poco de lógica, y mucho escepticismo. ¡Estad atentos!