
15.2: Inferencias de muestras a poblaciones
- Page ID
- 93865

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Frecuentemente utilizamos estadísticas de muestra para hacer inferencias inductivas sobre parámetros poblacionales. Cuando un periódico realiza una encuesta para ver cuántas personas piensan que el presidente Trump debería ser destituido, revisan con una muestra, dicen 2 mil adultos en todo Estados Unidos y sacan una conclusión sobre lo que piensan los adultos estadounidenses en general. Sus resultados serían más precisos si verificaran con todos, pero cuando una población es grande, simplemente no es práctico examinar a todos sus integrantes. No tenemos más remedio que confiar en una muestra de la población y hacer una inferencia basada en ella. Cuando los científicos se involucran en tales inferencias, se dice que están utilizando estadísticas inferenciales. Pero todos sacamos inferencias de muestras a poblaciones muchas veces al día.
Muestreo en la vida cotidiana
Las inferencias basadas en muestras son comunes en la investigación médica, las ciencias sociales y las encuestas. En estos escenarios, los científicos utilizan lo que se llaman estadísticas inferenciales para pasar de afirmaciones sobre muestras a conclusiones sobre poblaciones.
Pero todos sacamos inferencias similares muchas veces al día. Estás conduciendo por Belleville, KS por primera vez y tratando de decidir dónde comer. Has tenido buenas experiencias en los restaurantes McDonalds en el pasado (el conjunto de restaurantes McDonald's donde has comido en el pasado constituye tu muestra). Entonces, podrías concluir que es probable que todos los restaurantes McDonald's (la población) sean buenos y decidan probar las delicias culinarias del de Belleville. O suponga que conoces a seis personas (esta es tu muestra) que han salido con Wilbur, y a todas ellas le han parecido aburrido. Bien puede concluir que casi todos (esta es la población) lo encontrarían aburrido.
Siempre que haces una generalización basada en varios (pero no todos) de los casos, usabas muestreo. Estás sacando una conclusión sobre algún grupo más grande basado en lo que has observado sobre uno de sus subgrupos.
Aprendiendo
La mayor parte del aprendizaje de la experiencia implica extraer inferencias sobre casos no observados (poblaciones) a partir de información sobre un número limitado de casos que hemos observado (nuestras muestras). Ya sabes qué estrategias funcionaron en los casos que has experimentado (tu muestra) para conseguir una cita, dejar de fumar, poner en marcha tu auto cuando la batería parece apagada, o bien en un examen. Y luego sacas conclusiones sobre las poblaciones relevantes a partir de este conocimiento.
Un examen es realmente un procedimiento de muestreo para determinar cuánto has aprendido. Cuando tu profesor de cálculo conforma un examen, esperan probar ítems de la población de cosas que has aprendido en el curso y usar tu calificación como indicador de cuánta información has adquirido.
Muestras e inferencia
A menudo inferimos una conclusión sobre una población a partir de una descripción de una muestra que se extrajo de ella. Cuando lo hacemos:
- Nuestras instalaciones son reclamos sobre la muestra.
- Nuestra conclusión es una afirmación sobre la población.
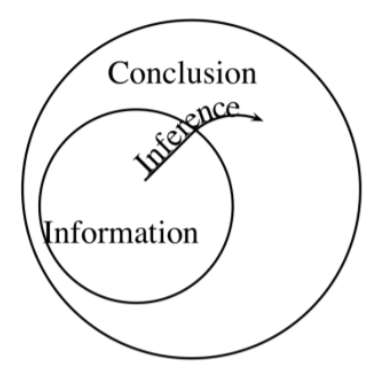.png)
Por ejemplo, podríamos sacar una conclusión sobre la tasa de divorcios de personas que viven en Florida a partir de locales que describan las tasas de divorcio entre 800 parejas que el Departamento de Relaciones Humanas de nuestra escuela tomó muestras.
En tal caso, nuestra inferencia no tiene validez deductiva. Implica un salto inductivo. La conclusión va más allá de la información en las premisas del argumento, porque contiene información sobre toda la población, mientras que las premisas sólo contienen información sobre la muestra. Pero si tenemos cuidado, nuestra inferencia puede seguir siendo inductivamente fuerte. Esto quiere decir que si comenzamos con verdaderas premisas (lo que en este caso significa una descripción correcta de la muestra), es probable que lleguemos a una conclusión verdadera (sobre toda la población).
Buenas Muestras
Una buena inferencia inductiva de una muestra a una población requiere:
- Una muestra lo suficientemente grande.
- Muestra representativa (imparcial).
Tendríamos que profundizar más en la probabilidad para decir exactamente qué tan grande es lo suficientemente grande, pero aquí no nos preocuparemos por eso. El punto importante es que en la vida cotidiana muchas veces confiamos en muestras que claramente son demasiado pequeñas.
También necesitamos una muestra que sea lo más representativa posible de toda la población. Se dice que una muestra que no es representativa está sesgada. Una muestra imparcial es típica de la población. Por el contrario, en una muestra sesgada, algunas porciones de la población están sobrerrepresentadas y otras están subrepresentadas.
El problema con una muestra muy pequeña es que no es probable que sea representativa. Al igual que otras cosas, una muestra más grande será más representativa. Pero la recopilación de información tiene costos, un precio en tiempo, dólares y energía, por lo que rara vez es factible obtener muestras enormes.
Nunca podemos estar seguros de que una muestra es imparcial, pero podemos esforzarnos por evitar cualquier sesgo no trivial que podamos descubrir. Con un poco de pensamiento, los peores sesgos suelen ser obvios. Supongamos, por ejemplo, que queremos saber qué piensa el público adulto estadounidense (nuestra población) sobre el consumo de alcohol. Claramente obtendríamos una muestra sesgada si distribuyéramos cuestionarios solo en un salón de billar (tendríamos una sobrerrepresentación de bebedores y una subrepresentación de quienes favorecen la templanza), o solo en las reuniones locales del MADD (aquí, los sesgos se revertirían).
Un ejemplo clásico de una muestra sesgada ocurrió en 1936, cuando una revista, The Literary Digest, realizó una encuesta utilizando nombres en los directorios telefónicos y en las listas de registro de automóviles. La mayoría de las personas que muestrearon favorecieron a Alf Landon sobre Franklin Roosevelt en las elecciones presidenciales de ese año, pero cuando llegó el día de las elecciones, Roosevelt ganó en un deslizamiento de tierra. ¿Qué salió mal? Las organizaciones de noticias ahora utilizan las encuestas telefónicas de forma rutinaria, pero en 1936, un porcentaje relativamente pequeño de personas tenía teléfonos y automóviles, y la mayoría de ellos eran ricos. Estas fueron las personas con más probabilidades de votar por el candidato republicano, Landon, por lo que la muestra no fue representativa de todos los votantes.
Hay otros casos en los que es probable que el sesgo sea, aunque no sea así de flagrante. Por ejemplo, cada vez que los miembros de la muestra sean voluntarios, por ejemplo, al devolver un cuestionario por correo, es probable que tengamos una muestra sesgada. Es probable que las personas dispuestas a devolver un cuestionario difieran de varias maneras de las personas que no lo son. O, para tomar un ejemplo más cerca de casa, es probable que las pruebas que se enfoquen solo en parte del material cubierto en clase provoquen una muestra sesgada y poco representativa de lo que has aprendido. No son una muestra justa de lo que sabes. Desafortunadamente, en algunos casos los sesgos pueden ser difíciles de detectar, y puede requerir una gran cantidad de experiencia para encontrarlo en absoluto.
Muestreo Aleatorio
La mejor manera de obtener una muestra imparcial es usar muestreo aleatorio. Una muestra aleatoria es un método de muestreo en el que cada miembro de la población tiene una probabilidad igualmente buena de ser elegido para la muestra. El muestreo aleatorio no garantiza una muestra representativa —nada menos que verificar a toda la población puede garantizarlo— pero sí la hace más probable. El muestreo aleatorio evita los sesgos involucrados con muchos otros métodos de muestreo.
Rara vez podemos obtener una muestra verdaderamente aleatoria, pero bajo algunas condiciones, típicamente en estudios y encuestas cuidadosamente realizados, podemos acercarnos razonablemente. Pero incluso en la vida diaria podemos usar muestras que son mucho menos sesgadas que aquellas en las que a menudo confiamos.
Marcación aleatoria de dígitos (RDD)
La tecnología moderna ahora permite a las organizaciones nacionales de sondeo con grandes recursos acercarse al ideal del muestreo aleatorio. Encuestas como la encuesta New York Times/CBS News utilizan lo que se llama Random Digit Dialing (RDD). El objetivo aquí es darle a cada número de teléfono residencial la misma oportunidad de ser llamado para una entrevista. Hoy en día, casi todas las encuestas principales utilizan alguna forma de RDD. Por ejemplo, la encuesta New York Times/CBS News utiliza el sistema GENESYS, que emplea una base de datos de más de 42 mil números telefónicos residenciales en todo Estados Unidos que se actualiza cada pocos meses. El sistema también emplea software que extrae una muestra aleatoria de números de teléfono de esta base de datos y luego compone aleatoriamente los últimos cuatro dígitos del número a llamar. Por supuesto, algunos tipos de personas son más difíciles de alcanzar por teléfono que otros, y algunos tipos están más dispuestos a ofrecer información voluntaria por teléfono (los adultos mayores tienden a estar más disponibles, más dispuestos a compartir y más probabilidades de responder a un número desconocido, por ejemplo). Pero RDD constituye un paso impresionante en la dirección de la aleatorización.
Muestreo aleatorio estratificado
Los científicos a veces van un paso más allá y utilizan una muestra aleatoria estratificada. Aquí, el objetivo es asegurar que en nuestra muestra haya un cierto porcentaje de miembros de diversas subpoblaciones (por ejemplo, un número igual de hombres y de mujeres). Separan a la población en categorías o “estratos” relevantes antes del muestreo (por ejemplo, en las categorías o subpoblaciones de hombres y de mujeres). Después muestrean aleatoriamente dentro de cada categoría. El pensamiento aquí es que los resultados serán más precisos que el mero muestreo aleatorio porque el muestreo aleatorio podría sobrepesar accidentalmente a algún grupo (porque fueron muestreados a una tasa mayor a través de la varianza). Entonces, en lugar de hacer una encuesta estatal aleatoria sobre quién es el favorito en las elecciones para gobernador, una encuesta que utilice encuestas aleatorias estratificadas se aseguraría de sondear todos los condados en proporción a las expectativas de participación (también podrían estratificarse más en función del género, la raza, la educación, etc.).
Encuestas
Un problema práctico creciente en los últimos años ha sido la disminución de la participación pública en las encuestas. Los encuestadores están recibiendo cada vez más “no respuestas”. Algunos de estos resultan de la dificultad de contactar a las personas por teléfono (la gente está en el trabajo, falta de voluntad para responder números desconocidos, etc.). Pero los contactados también están menos dispuestos a participar de lo que estaban en el pasado. Las razones de esto no están del todo claras, pero la creciente desilusión con la política y la falta de paciencia para las llamadas no solicitadas resultantes del aumento del telemarketing pueden ser parte de la razón.
El uso de encuestas push también lleva a una cautela sobre las encuestas. El sondeo push no es realmente sondeo en absoluto. En cambio, una organización, por ejemplo, la organización de campaña de un candidato que se postula para el Senado, llama a miles de hogares. El que llama dice que están realizando una encuesta, pero de hecho no se recogen resultados y en cambio se implanta una afirmación dañina —y a menudo falsa— sobre el otro lado en lo que se presenta como una pregunta neutral. Por ejemplo, la persona que llama podría preguntar: “¿Está de acuerdo con el objetivo del Candidato X de recortar los pagos de la seguridad social en los próximos seis años?” Tales usos engañosos de las encuestas probablemente harán que el público sea más cínico sobre las encuestas.
Variabilidad de muestreo
Es poco probable que cualquier muestra que sea sustancialmente menor que la población parental sea perfectamente representativa de la población. Supongamos que sacamos muchas muestras del mismo tamaño de la misma población. Por ejemplo, si sacamos muchas muestras de 1,000 cada una de toda la población de votantes de Oklahoma. El conjunto de todas estas muestras se denomina distribución de muestreo.
Las muestras en nuestra distribución de muestreo variarán de una a otra. Esto solo significa que si sacamos muchas muestras de la misma población, es probable que obtengamos resultados algo diferentes cada vez. Por ejemplo, si examinamos veinte muestras, cada una con 1,000 votantes de Oklahoma, es probable que encontremos diferentes porcentajes de republicanos en cada una de nuestras muestras.
Esta variación entre las muestras se denomina variabilidad de muestreo o error de muestreo (aunque en realidad no es un error o error). Supongamos que solo tomamos una muestra de mil votantes de Oklahoma y descubramos que el 60% de ellos prefiere al candidato republicano a gobernador. Debido a la variabilidad del muestreo, sabemos que si hubiéramos dibujado una muestra diferente del mismo tamaño, probablemente habríamos obtenido un porcentaje algo diferente de personas favoreciendo al republicano. Entonces, no podremos concluir que exactamente el 60% de todos los votantes de Oklahoma favorecen al republicano por el hecho de que el 60% de los votantes de nuestra muestra única lo hacen.
A medida que nuestras muestras se hacen más grandes, es menos probable que la media de la muestra sea la misma que la media de la población parental. Pero es más probable que la media de la muestra sea cercana a la media de la población. Así, si el 60% de los votantes en una muestra de 10 favorecen al candidato republicano, no podemos tener mucha confianza en predecir que cerca del 60% de los votantes en general sí. Si 60% de una muestra de 100 lo hacen, podemos tener más confianza, y si 60% de una muestra de 1,000 lo hacen, podemos tener más confianza aún.
Los estadísticos superan el problema de la variabilidad del muestreo calculando un margen de error. Este es un número que nos dice lo cerca que suele estar el resultado de una encuesta al parámetro poblacional en cuestión. Por ejemplo, nuestra afirmación podría ser que el 60% de la población, más o menos el tres por ciento, votará republicano este próximo año. Cuanto menor sea la muestra, mayor será el margen de error.
Pero a menudo hay grandes costos en la obtención de una muestra grande, por lo que debemos comprometer entre lo que es factible y el margen de error. Aquí sí obtienes lo que pagas. Es sorprendente, pero el tamaño de la muestra no necesita ser un gran porcentaje de la población para que una encuesta o encuesta sea buena. Lo importante es que la muestra no esté sesgada, y que sea lo suficientemente grande; una vez que esto se logra, es el número absoluto de cosas en la muestra (más que la proporción de la población que compone la muestra) lo que resulta relevante para realizar una encuesta confiable. En nuestra vida diaria, no podemos esperar muestras aleatorias, pero con un poco de cuidado podemos evitar sesgos flagrantes en nuestras muestras, y esto puede mejorar nuestro razonamiento dramáticamente.
Mal muestreo y mal razonamiento
Muchos de los errores de razonamiento que estudiaremos en capítulos posteriores son el resultado del uso de muestras pequeñas o sesgadas. El sacar conclusiones sobre una población general a partir de una muestra de la misma se suele llamar generalización. Y sacar tal conclusión de una muestra demasiado pequeña a veces se llama falacia de generalización apresurada o, en el lenguaje cotidiano, saltar a una conclusión.
Nuestras muestras también suelen estar sesgadas. Por ejemplo, a una persona en una entrevista de trabajo le puede ir inusualmente bien (se esfuerza por crear una buena primera impresión) o inusualmente mal (puede estar muy nerviosa). Si es así, sus acciones constituyen una muestra sesgada, y no serán un predictor exacto del desempeño laboral futuro del candidato. En próximos capítulos, encontraremos muchos ejemplos de malos razonamientos que resultan del uso de muestras que son demasiado pequeñas, altamente sesgadas, o ambas.
Ejemplo: Los dos hospitales
Hay dos hospitales en Smudsville. Alrededor de 50 bebés nacen todos los días en el más grande, y alrededor de 14 bebés nacen todos los días en el más pequeño de la calle. En promedio, 50% de los nacimientos en ambos hospitales son niñas y 50% son niños, pero el número rebota alrededor de algunos de un día para otro en ambos hospitales.
- ¿Por qué el porcentaje de niños variaría de un día a otro?
- ¿Qué hospital, si alguno, es más probable que tenga más días al año cuando más del 65% de los bebés que nacen son niños?
Todos sabemos que las muestras más grandes probablemente sean más representativas de sus poblaciones parentales. Pero a menudo no nos damos cuenta de que estamos ante un problema que involucra este principio; no lo “codificamos” como un problema que involucra el tamaño de la muestra. Dado que aproximadamente la mitad de todos los nacimientos son niños y aproximadamente la mitad son niñas, los verdaderos porcentajes en la población general son aproximadamente la mitad y la mitad. Dado que una muestra más pequeña tendrá menos probabilidades de reflejar estas verdaderas proporciones, el hospital más pequeño tiene más probabilidades de tener más días al año cuando más del 65% de los nacimientos son niños. Los partos en el hospital más pequeño constituyen una muestra menor.
Esto te parecerá más intuitivo si piensas en el siguiente ejemplo. Si volteaste una moneda justa cuatro veces, no te sorprendería tanto si tuvieras cuatro cabezas. La muestra (cuatro vueltas) es pequeña, por lo que esto no sería demasiado sorprendente; la probabilidad es 116. Pero si volteaste la misma moneda cien veces, te sorprendería mucho conseguir todas las cabezas. Una muestra tan grande es muy poco probable que se desvíe tanto de la población de todos los posibles giros de la moneda.
Ejercicios
- ¿Cuál es la probabilidad de obtener todas las cabezas cuando lanzas una moneda justa (a) cuatro veces, (b) diez veces, (c) veinte veces, (d) cien veces?
En 2—7 decir (a) cuál es la población relevante, (b) cuál es la muestra (es decir, qué hay en la muestra), (c) si la muestra parece estar sesgada; luego (d) evaluar la inferencia.
- No podemos permitirnos revisar cuidadosamente todos los chips de computadora que salen de la línea de montaje en nuestra fábrica. Pero comprobamos uno de cada 300, usando un dispositivo de aleatorización para elegir los que examinamos. Si encontramos un par de malos, echamos un vistazo a todo el grupo.
- No podemos permitirnos revisar cuidadosamente todos los chips de computadora que salen de la línea de montaje. Pero comprobamos los primeros desde el inicio de la carrera de cada día. Si encontramos un par de malos, echamos un vistazo a todo el grupo.
- Actualmente hay más de un centenar de centrales nucleares operando en Estados Unidos y Europa Occidental. Cada uno de ellos ha operado desde hace años sin matar a nadie. Entonces, las centrales nucleares no parecen representar un gran peligro para la vida humana.
- Unirse al programa Weight Away es una buena manera de perder peso. Tu amiga Millie y el tío Wilbur ambos perdieron todo el peso que querían perder, y se han mantenido si están apagados desde hace seis meses.
- Unirse al programa Weight Away es una buena manera de perder peso. Consumer Reports realizó un estudio bastante exhaustivo, encuestando a cientos de personas, y descubrió que funcionaba mejor que cualquier método alternativo para perder peso. [Este es un ejemplo ficticio; desconozco las tasas de éxito de varios programas de reducción de peso.]
- Alfred tiene una buena trayectoria como fuente de información sobre la vida social de las personas que conoces, por lo que llegas a la conclusión de que es una fuente confiable de chismes en general.
- Los encuestadores están recibiendo cada vez más “no respuestas”. Algunos de estos resultan de la dificultad de contactar a las personas por teléfono (la gente está en el trabajo, tamizando números desconocidos, etc.). Pero los contactados también están menos dispuestos a participar de lo que estaban en el pasado. ¿Significa esto automáticamente que las encuestas recientes tienen más probabilidades de ser sesgadas? ¿Cómo podríamos determinar si los hay? ¿De qué manera podrían estar sesgados (defender tu respuesta)?
- Comenzamos el capítulo con la historia de gatos que se habían caído de las ventanas. ¿Qué podría explicar estos hallazgos?
- Varios grupos de estudios han demostrado que las tasas de supervivencia de los pacientes después de la cirugía en realidad son menores en los mejores hospitales que en los hospitales que no son tan buenos. Más personas mueren en los mejores hospitales. ¿Qué podría explicar esto?
- El psicólogo Robyn Dawes relata una historia sobre su implicación con un comité que intentaba establecer pautas para los psicólogos profesionales. Estaban tratando de decidir cuáles deberían ser las reglas para denunciar a un cliente (y así violar la confidencialidad) que admitió haber abusado sexualmente de niños, cuando el abuso ocurrió en el pasado lejano. Varias personas en el comité dijeron que se les debe exigir que lo denuncien, incluso cuando ocurrió en el pasado lejano, porque lo único seguro de los abusadores de niños es que nunca se detienen solos sin ayuda profesional. Dawes preguntó a los demás cómo sabían esto. Ellos respondieron, con toda sinceridad, que como consejeros tenían un amplio contacto con los abusadores de menores. ¿Esto nos da una buena razón para pensar que los abusadores de niños rara vez se detienen solos? ¿Qué problemas, si los hay, están involucrados en el razonamiento del grupo?
- Una encuesta con un margen de error del 4% encuentra que 47% de los votantes encuestados planean votar por Smith para Sheriff y 51% planea votar por su oponente, Jones. ¿Qué información te gustaría conocer al evaluar estos resultados? Suponiendo que se utilizaron procedimientos sonoros de sondeo, ¿qué podemos concluir sobre quién ganará la elección?
- Supongamos que a una organización encuestadora le preocupaba que una encuesta telefónica resultara en una muestra sesgada. Entonces, en cambio, escogen direcciones al azar y visitan las residencias en persona. Tienen recursos limitados, sin embargo, y por lo que sólo pueden hacer una visita a cada residencia, y si no hay nadie en casa simplemente pasan al siguiente lugar de su lista. ¿Qué tan representativa es probable que sea esta muestra? ¿Cuáles son sus defectos? ¿Podrían corregirse? ¿A qué costo?
- Supongamos que eres un excelente jugador de ajedrez y que Wilbur es bueno, pero no tan bueno como tú. ¿Sería más probable que le ganaras en una serie al mejor de tres o en una serie al mejor de siete (o la cantidad de juegos marcaría alguna diferencia)? Defiende tu respuesta.
- Un estudio realizado por los Centros para el Control y la Prevención de Enfermedades fue reportado en el Journal of the American Medical Association (JAMA). El estudio se basó en una encuesta a 9,215 pacientes adultos que eran miembros de la organización de mantenimiento de la salud Kaiser Permanente (una HMO). El estudio se centró en ocho traumas infantiles, entre ellos el abuso psicológico, físico y sexual, tener una madre que fue abusada, padres separados o divorciados, y convivir con ellos eran abusadores de sustancias, enfermos mentales, o que habían sido encarcelados. Se encontró que más casos de trauma parecían aumentar la probabilidad de fumar. Por ejemplo, las personas que experimentaron cinco o más casos de trauma tenían 5.4 veces más probabilidades de comenzar a fumar a la edad de 14 años que las personas que no reportaron ningún trauma infantil. Analizar este estudio. ¿Cuál fue la muestra y la población? ¿Cuáles son los posibles puntos fuertes y débiles?
En 16 y 17 explican qué (si acaso) está mal en cada uno de los siguientes ejemplos. Cuando el razonamiento sale mal, a menudo sale muy mal, por lo que es muy posible que incluso un argumento corto sea defectuoso en más de una forma.
- Supongamos que la NRA (Asociación Nacional del Rifle) realizó recientemente una encuesta a sus miembros y encontró que se oponían abrumadoramente a cualquier otra medida de control de armas.
- Supongamos que una muestra aleatoria de 500 alumnos de nuestra universidad demostró que una abrumadora mayoría no piensa que la escuela necesita presupuestar más dinero para hacer el campus más accesible a las personas con discapacidad.
- Una psicóloga de televisión señaló recientemente que el matrimonio promedio dura 7 años, hecho que buscó explicar señalando evidencias de que la vida va en ciclos de 7 años (por lo que no fue de extrañar que los matrimonios duraran 7 años). ¿Cómo pudo haber entendido mal el hecho de que estaba explicando?
- Respuestas a ejercicios seleccionados
-
10. La causa real, aunque solo podrías plantearla en base a la información de este problema, resulta ser que los pacientes de alto riesgo, aquellos que necesitan los tipos de cirugía más peligrosos, suelen ir a mejores hospitales (que tienen más probabilidades de proporcionar dicha cirugía, o al menos más probabilidades de proporcionarla a un nivel más bajo riesgo).
14. Pista: piensa en el ejemplo del hospital anterior.