
7.2: Optimización continua de una sola dimensión
- Page ID
- 84134

Considere el caso de un solo parámetro, y una función de costo. Cuando la función es conocida y es continua -como en muchas aplicaciones de ingeniería- un primer método muy razonable a tratar es poner a cero la derivada. En particular,
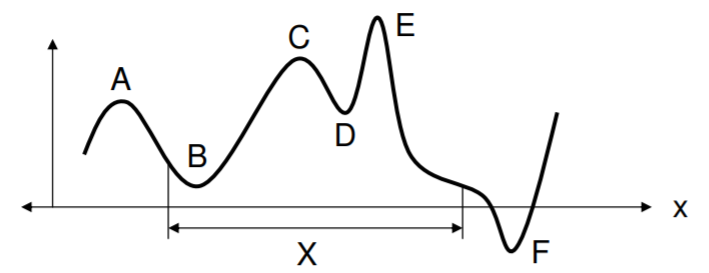
\[ \left[ \dfrac{df(x)}{dx} \right]_{x = x*} = 0. \]El usuario tiene que ser consciente incluso en este primer problema de que pueden existir múltiples puntos con una derivada de cero. Estos son todos los lugares en\(X\) donde\(f(x)\) es plano, y de hecho estos podrían estar en los mínimos locales y en los máximos locales y globales. Otro punto importante a tener en cuenta es que si\(X\) es un dominio finito, entonces puede que no haya ubicación donde la función sea plana. En este caso, la solución podría estar a lo largo del límite de\(X\), o tomar el mínimo dentro\(X\). En la siguiente figura, los puntos\(A\) y\(C\) son máximos locales,\(E\) son los máximos globales,\(B\) y\(D\) son mínimos locales, y\(F\) es el mínimo global mostrado. No obstante, el dominio de la solución\(X\) no admite\(F\), por lo que la mejor solución sería\(B\). En todos los casos mostrados, sin embargo, tenemos en los máximos y mínimos\(f'(x) = 0\). Además, al máximo\(f''(x) < 0\) y al mínimo\(f''(x) > 0\).
.png)
Decimos que una función\(f(x)\) es convexa si y sólo si tiene en todas partes una segunda derivada no negativa, como\(f(x) = x^2\). Para una función convexa, debe ser evidente que cualquier mínimo es de hecho un mínimo global. (Una función es cóncava si\(-f(x)\) es convexa). Otro dato importante de las funciones convexas es que la gráfica siempre se encuentra por encima de cualquier punto en una línea tangente, definida por la pendiente en el punto de interés:
\[ f(x + \delta x) \geq f(x) + f'(x)\delta . \]
Cuando\(\delta\) está cerca de cero, los dos lados son aproximadamente iguales.
Supongamos que el valor derivado de puesta a cero\(x^*\) no se puede deducir directamente de la derivada. Necesitamos otra forma de avanzar hacia el mínimo. Aquí hay un enfoque: moverse en la dirección cuesta abajo en una pequeña cantidad que escala con la inversa de la derivada. Dejar\(\delta = - \gamma / f'(x)\) hace la ecuación anterior:
\[ f(x + \delta) \approx f(x) - \gamma . \]
La idea es dar pequeños pasos cuesta abajo, por ejemplo,\(x_{k+1} = x_k + \delta\) donde\(k\) indica la\(k\) 'ésima suposición, y este algoritmo generalmente se llama un “método de gradiente” o algo similarmente anodino! Si bien es robusto, una dificultad con este algoritmo es cómo detenerse, porque trata de mover un decremento constante\(f\) en cada paso. No podrá hacerlo cerca de un mínimo plano, aunque por supuesto se puede modificar\(\gamma\) sobre la marcha para mejorar la convergencia.
Como otro método, proponer un nuevo problema en el que\(g(x) = f'(x)\), y ahora tenemos que resolver\(g(x^*)=0\). Encontrar el cero de una función es un problema importante por sí solo. Ahora la desigualdad de convexidad anterior se asemeja a la expansión de la serie Taylor, que se reescribe aquí en forma completa:
\[ g(x + \delta) \, = \, g(x) + g'(x)\delta + \dfrac{1}{2!} g''(x) \delta^2 + \dfrac{1}{2!} g'''(x) \delta^3 + . \, . \, . \]La expansión es teóricamente cierta para cualquiera\(x\) y cualquiera\(\delta\) (si la función es continua), y así claramente\(g(x+\delta)\) puede ser al menos aproximada por los dos primeros términos en el lado derecho. Si se desea establecer\(g(x+\delta) = 0\), entonces tendremos la estimación
\[ \delta = -g(x) / g'(x). \]
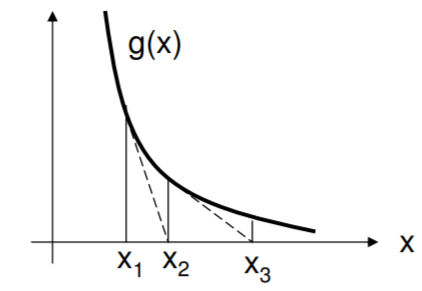
Este es el método de primer orden de Newton para encontrar el cero de una función. La idea es derribar la línea tangente a su propio cruce por cero, y tomar el nuevo punto como la siguiente conjetura. Como se muestra en la figura, las conjeturas podrían desviarse salvajemente si la función es demasiado plana cerca del cruce por cero.
.png)
Veamos esto de otra manera. Volviendo a la función\(f\) y a la aproximación de la serie Taylor
\[ f(x + \delta) \, \approx \, f(x) + f'(x)\delta + \dfrac{1}{2!}f''(x) \delta^2, \]
podemos establecer a cero la derivada del lado izquierdo con respecto a\(\delta\), para obtener
\ begin {align} 0\, &\ approx\, 0 + f' (x) + f "(x)\ delta\ largoderrow\\ [4pt]\ delta\, &=\, -f' (x)/f" (x). \ end {align}
Esto es lo mismo que el método de Newton anterior desde entonces\(f'(x) = g(x)\). Claramente emplea tanto la primera como la segunda información derivada, y alcanzará el mínimo en un solo disparo (!) si la función es verdaderamente cuadrática y las derivadas\(f'(x) and f''(x)\) son precisas. En la siguiente sección, que trata de múltiples dimensiones, desarrollaremos una forma análoga y poderosa de este método. También en la siguiente sección, nos referimos a una búsqueda lineal, que es meramente una minimización unidimensional a lo largo de una dirección particular, utilizando un método unidimensional (no especificado), como el método de Newton aplicado a la derivada.