
13.3: Visualización de similitud y distancia
- Page ID
- 115147
En la sección anterior, hemos visto cómo se puede medir e indexar el grado de similitud o distancia entre dos actores, patrones de vínculos con otros actores. Una vez hecho esto, ¿entonces qué?
A menudo es útil examinar las similitudes o distancias para tratar de localizar agrupaciones de actores (es decir, más grandes que una pareja) que son similares. Al estudiar los patrones más grandes de qué grupos de actores son similares a los que otros, también podemos obtener una idea de “qué pasa con” las posiciones del actor son más críticas para hacerlas más similares o más distantes.
Dos herramientas que se utilizan comúnmente para visualizar patrones de relaciones entre variables también son muy útiles para explorar datos de redes sociales. Cuando hemos creado una matriz de similitud o distancia describiendo todas las parejas de actores, podemos estudiar la similitud de las diferencias entre las relaciones de “casos” de la misma manera que estudiaríamos las similitudes entre atributos.
En las dos secciones siguientes mostraremos ejemplos muy breves de cómo se puede utilizar el escalado multidimensional y el análisis jerárquico de conglomerados para identificar patrones en matrices de similaridad/distancia actor por actor. Ambas herramientas son ampliamente utilizadas en el análisis no de redes; existen grandes y excelentes literaturas sobre las muchas complejidades importantes del uso de estos métodos. Nuestro objetivo aquí es solo proporcionar una introducción muy básica.
Herramientas de agrupamiento
Agrupación jerárquica aglomerativa de nodos sobre la base de la similitud de sus perfiles de vínculos con otros casos proporciona un “árbol de unión” o “dendograma” que visualiza el grado de similitud entre los casos - y puede ser utilizado para encontrar clases de equivalencia aproximada.
Herramientas>Cluster>Jerárquico procede colocando inicialmente cada caso en su propio clúster. Los dos casos más similares (aquellos con el índice de similitud medido más alto) se combinan luego en una clase. La similitud de esta nueva clase con todas las demás se calcula entonces sobre la base de uno de tres métodos. Sobre la base de la matriz de similitud recién calculada, el proceso de unión/recálculo se repite hasta que todos los casos se “aglomeran” en un solo conglomerado. La parte “jerárquica” del nombre del método se refiere al hecho de que una vez que un caso se ha unido a un clúster, nunca se vuelve a clasificar. Esto da como resultado conglomerados de tamaño creciente que siempre encierran racimos más pequeños.
El método “Promedio” calcula la similitud de las puntuaciones promedio en el clúster recién formado con todos los demás clústeres; el método “Single-Link” (también conocido como “vecino más cercano”) calcula las similitudes sobre la base de la similitud del miembro del nuevo clúster que es más similar entre sí, no en el racimo. El método “Completo-Link” (también conocido como “vecino más lejano”) calcula similitudes entre el miembro del nuevo clúster que es menos similar entre sí, no en el clúster. El método predeterminado es usar el promedio del clúster; los métodos de enlace único tenderán a dar diagramas de unión largos y fibrosos; los métodos de enlace completo tenderán a dar diagramas de unión altamente separados.
La distancia Hamming en el envío de información en la red Knoke se computó como se muestra en la sección anterior, y los resultados se almacenaron como un archivo. Este archivo se ingresó luego a Herramientas>Cluster>Jerárquico. Especificamos que se iba a utilizar el método “promedio”, y que los datos eran “disimilitudes”. Los resultados se muestran como Figura 13.9.
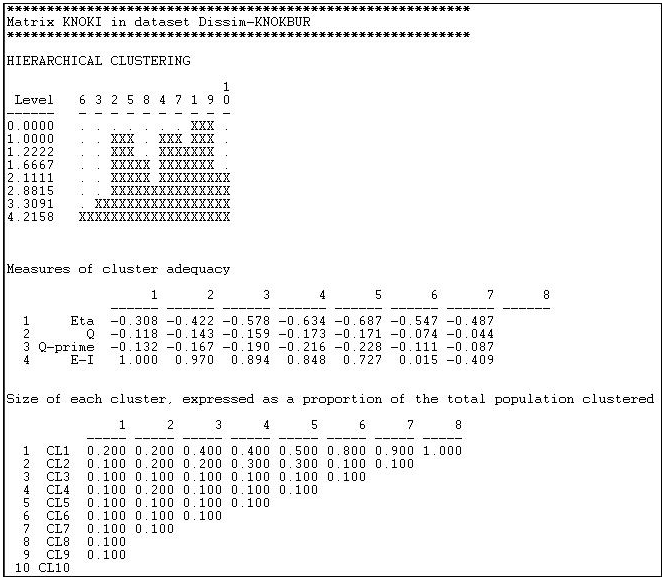
Figura 13.9: Agrupación de distancias de Hamming de envío de información en la red Knoke
El primer gráfico muestra que los nodos 1 y 9 fueron los más similares, y se unieron primero. El gráfico, por cierto, se puede renderizar como un dendograma más pulido usando Herramientas>Dendograma>Dibujar sobre los datos guardados de la herramienta cluster. En el siguiente paso, hay tres clusters (casos 2 y 5, 4 y 7, y 1 y 9). La unión continúa hasta que (en el\(^\text{th}\) paso 8) todos los casos se aglomeran en un solo racimo. Esto da una imagen clara de la similitud de los casos, y las agrupaciones o clases de casos. Pero realmente hay ocho fotos aquí (una por cada paso de la unión). ¿Cuál es la solución “correcta”?
Nuevamente, no hay una respuesta única. La teoría y un conocimiento sustantivo de los procesos que dan origen a los datos son la mejor guía. El segundo panel “Medidas de adecuación de clústeres” puede ser de alguna ayuda. Aquí hay una serie de índices, y la mayoría (por lo general) dará respuestas similares. A medida que avanzamos de la derecha (escalones más altos o cantidades de aglomeración) a la izquierda (más conglomerados, menos aglomeración) mejora el ajuste. El índice E-I suele ser de mayor utilidad, ya que mide la relación entre el número de vínculos dentro de los clusters y los vínculos entre clústeres. Generalmente, el objetivo es lograr clases que sean muy similares dentro, y bastante distintas sin ellas. Aquí, uno podría ser más tentado por la solución del\(^\text{th}\) paso 5 del proceso (clústeres de 2+5, 4+7, 1+9, y los otros son clústeres de un solo elemento).
Para ser significativos, los conglomerados también deben contener un porcentaje razonable de los casos. El último panel muestra información sobre los tamaños relativos de los clústeres en cada etapa. Con sólo 10 casos por agrupar en nuestro ejemplo, esto no es terriblemente esclarecedor aquí.
UCINET proporciona dos herramientas adicionales de análisis de clústeres que no discutiremos en ningún detalle aquí, pero que tal vez desee explorar. Herramientas>Cluster>Optimización permite al usuario seleccionar, a priori, una serie de clases, y luego usa el método de análisis de clúster elegido para ajustar casos de manera óptima a las clases. Esto es muy similar a la técnica de optimización estructural que discutiremos a continuación. Herramientas>Cluster>Clúster Adecuación toma una clasificación suministrada por el usuario (una partición o archivo de atributos), ajusta los datos a ella e informa sobre la bondad de ajuste.
Herramientas de escalado multidimensional
Por lo general, nuestro objetivo en el análisis de equivalencia es identificar y visualizar “clases” o grupos de casos. Al usar el análisis de conglomerados, estamos asumiendo implícitamente que la similitud o distancia entre los casos se refleja como una sola dimensión subyacente. Sin embargo, es posible que existan múltiples “aspectos” o “dimensiones” subyacentes a las similitudes observadas de los casos. El análisis factorial o componente podría aplicarse a las correlaciones o covarianzas entre casos. Alternativamente, se podría usar escalado multidimensional (no métrico para datos que son inherentemente nominales u ordinales; métrica para valores).
MDS representa los patrones de similitud o disimilitud en los perfiles de empate entre los actores (cuando se aplica a adyacencia o distancias) como un “mapa” en el espacio multidimensional. Este mapa nos permite ver qué tan “cercanos” están los actores, si se “agrupan” en el espacio multidimensional, y cuánta variación hay a lo largo de cada dimensión.
Las figuras 13.10 y 13.11 muestran los resultados de aplicar Herramientas>MDS>MDS no métrico a la matriz de adyacencia bruta de la red de información Knoke, y seleccionar una solución bidimensional.
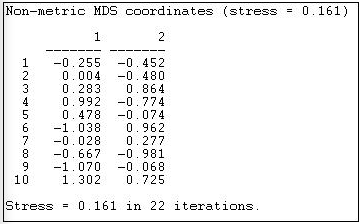
Figura 13.10: Coordenadas bidimensionales MDS no métricas de adyacencia de información de Knoke
El “estrés” es una medida de maldad de ajuste. Al usar MDS, es una buena idea mirar una gama de soluciones con más dimensiones, para que pueda evaluar hasta qué punto las distancias son unidimensionales. Las coordenadas muestran la ubicación de cada caso (1 a 10) en cada una de las dimensiones. El caso uno, por ejemplo, está en el cuadrante inferior izquierdo, teniendo puntuaciones negativas tanto en la dimensión 1 como en la dimensión 2.
El “significado” de las dimensiones a veces se puede evaluar comparando casos que se encuentran en los polos extremos de cada dimensión. ¿Son las organizaciones en un polo “públicas” y las del otro “privadas”? Al analizar datos de redes sociales, no es raro que la primera dimensión sea simplemente la cantidad de conexión o el grado de los nodos.
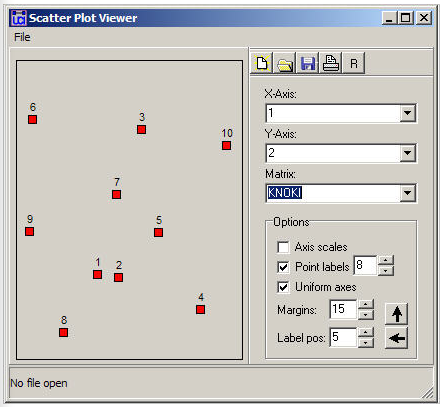
Figura 13.11: Mapa bidimensional de MDS no métrico de adyacencia de información Knoke
La Figura 13.11 grafica los nodos según sus coordenadas. En este mapa, estamos buscando conglomerados de puntos estrechos significativos para identificar casos que sean muy similares en ambas dimensiones. En nuestro ejemplo, hay muy poca similitud de este tipo (guardar, quizás, los nodos 1 y 2).
Las herramientas de agrupamiento y escalado pueden ser útiles en muchos tipos de análisis de redes. Cualquier medida de las relaciones entre los nodos se puede visualizar usando estos métodos: la adyacencia, la fuerza, la correlación y la distancia se examinan con mayor frecuencia.
Estas herramientas también son bastante útiles para examinar la equivalencia. La mayoría de los métodos para evaluar la equivalencia generan medidas actor por actor de cercanía o similitud en los perfiles de empate (usando diferentes reglas, dependiendo del tipo de equivalencia que estemos tratando de medir). Cluster y MDS suelen ser muy útiles para dar sentido a los resultados.