
17.5: Análisis Cualitativo
- Page ID
- 115255
Muchas veces todo lo que sabemos de actores y eventos es simple copresencia. Es decir, o un actor estaba, o no estaba, presente, y nuestra matriz de incidencia es binaria. En casos como este, se pueden aplicar los métodos de escalado en la última sección, pero uno debe ser muy cauteloso sobre los resultados. Esto se debe a que los diversos métodos dimensionales operan sobre matrices de similaridad/distancia, y medidas como las correlaciones (como se usan en el análisis factorial de dos modos) pueden ser engañosas con datos binarios. Incluso el análisis de correspondencia, que es más amigable con los datos binarios, puede ser problemático cuando los datos son escasos.
Un enfoque alternativo es el modelado de bloques. El modelado de bloques funciona directamente sobre la matriz de incidencia binaria al tratar de permutar filas y columnas para encajar, lo más cerca posible, las imágenes idealizadas. Este enfoque no implica ninguno de los supuestos distribucionales que se hacen en el análisis de escalado.
En principio, se podría ajustar cualquier tipo de modelo de bloque a los datos de incidencia de actor por evento. Examinaremos dos modelos que hacen preguntas significativas (alternativas) sobre los patrones de vinculación entre actores y eventos. Ambos modelos se pueden calcular directamente en UCINET. Los modelos de bloques alternativos, por supuesto, podrían ajustarse a los datos de incidencia utilizando algoritmos de modelado de bloques más generales.
Análisis bimodal de núcleo-periferia
La estructura núcleo-periferia es un patrón típico ideal que divide tanto las filas como las columnas en dos clases. Uno de los bloques en la diagonal principal (el núcleo) es un bloque de alta densidad; el otro bloque en la diagonal principal (la periferia) es un bloque de baja densidad. El modelo núcleo-periferia es indiferente a la densidad de lazos en los bloques fuera de la diagonal.
Cuando aplicamos el modelo núcleo-periferia a datos de actor por actor (ver Network>Core/Periferia), el modelo busca identificar un conjunto de actores que tienen una alta densidad de vínculos entre ellos (el núcleo) compartiendo muchos eventos en común, y otro conjunto de actores que tienen muy baja densidad de lazos entre ellos (la periferia) al tener pocos eventos en común. Los actores en el núcleo son capaces de coordinar sus acciones, los de la periferia no lo son. Como consecuencia, los actores en el núcleo tienen una ventaja estructural en las relaciones de intercambio con actores de la periferia.
Cuando aplicamos el modelo núcleo-periferia a datos de actor por evento (Network>2-Mode>Núcleo Categórico/Periferia) estamos buscando la misma “imagen” idealizada de un bloque de alta y baja densidad a lo largo de la diagonal principal. Pero, ahora el significado es bastante diferente.
El “núcleo” consiste en una partición de actores que están estrechamente conectados con cada uno de los eventos en una partición de eventos; y simultáneamente una partición de eventos que están estrechamente conectados con los actores en la partición central. Entonces, el “núcleo” es un grupo de actores y eventos frecuentemente concurrentes. La “periferia” consiste en una partición de actores que no son co-incidentes a los mismos eventos; y una partición de eventos que son disjuntos porque no tienen actores en común.
Network>2-Mode>Núcleo Categórico/Periferia utiliza métodos numéricos para buscar la partición de actores y de eventos que se acerquen lo más posible a la imagen idealizada. La Figura 17.16 muestra una porción de los resultados de aplicar este método a la participación (no al partidismo) en los datos de donantes e iniciativas de California.
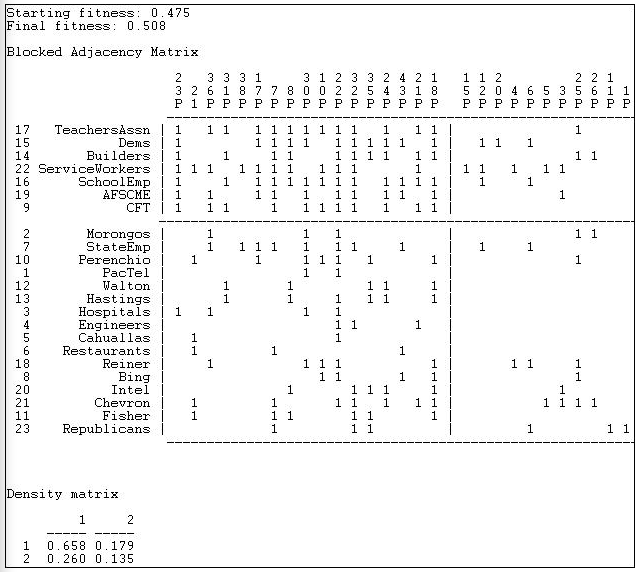
Figura 17.16: Modelo categórico de núcleo-periferia de donantes e iniciativas electorales de $1M de California (truncado)
El método de búsqueda numérica utilizado por Network>2-Mode>Núcleo Categorical/Periferia es un algoritmo genético, y la medida de bondad de ajuste se establece en términos de una puntuación de “aptitud” (0 significa mal ajuste, 1 significa ajuste excelente). También se puede juzgar la bondad del resultado examinando la matriz de densidad al final de la salida. Si el modelo de bloque fue completamente exitoso, el bloque 1,1 debería tener una densidad de uno, y el bloque 2,2 debería tener una densidad de cero. Si bien lejos de ser perfecto, el modelo aquí es lo suficientemente bueno como para ser tomado en serio.
La matriz bloqueada muestra un “núcleo” compuesto por el Partido Demócrata, varios sindicatos importantes y la asociación de la industria de la construcción que son muy propensos a participar en un número considerable de iniciativas (proposición 23 a propuesta 18). El resto de los actores se agrupan en la periferia ya que ambos participan con menor frecuencia y tienen pocos temas en común. Un número considerable de temas también se agrupan como “periféricos” en el sentido de que atraen pocos donantes, y estos donantes tienen poco en común. También vemos (arriba a la derecha) que los actores centrales sí participan hasta cierto punto (0.179) en temas periféricos. En la parte inferior izquierda, vemos que los actores periféricos participan algo más fuertemente (0.260) en temas centrales.
Análisis de facciones de dos modos
Un modelo de bloques alternativo es el de las “facciones”. Las facciones son agrupaciones que tienen alta densidad dentro del grupo, y baja densidad de lazos entre grupos. Red>Subgrupos>Facciones ajusta este modelo de bloques a datos de modo único (para cualquier número de facciones especificado por el usuario). Network>2-Mode>2-Mode Factions ajusta el mismo tipo de modelo a datos de dos modos (pero solo para dos facciones).
Cuando aplicamos el modelo de facciones a datos de actores unimodales, estamos tratando de identificar dos grupos de actores que están estrechamente vinculados entre sí asistiendo a todos los mismos eventos, pero muy vagamente conectados con miembros de otras facciones y los eventos que los unen. Si tuviéramos que aplicar la idea de facciones a los eventos en un análisis monomodo, estaríamos buscando identificar eventos que estuvieran estrechamente vinculados al tener exactamente los mismos participantes.
Network>2-Mode>2-Mode Factions aplica el mismo enfoque a la matriz rectangular actor por evento. Al hacer esto, estamos tratando de ubicar agrupaciones conjuntas de actores y eventos que sean lo más mutuamente excluyentes posible. En principio, podría haber más de dos de esas facciones. La Figura 17.17 muestra los resultados del modelo de bloques de facciones bimodales a la participación de los principales donantes en iniciativas políticas.
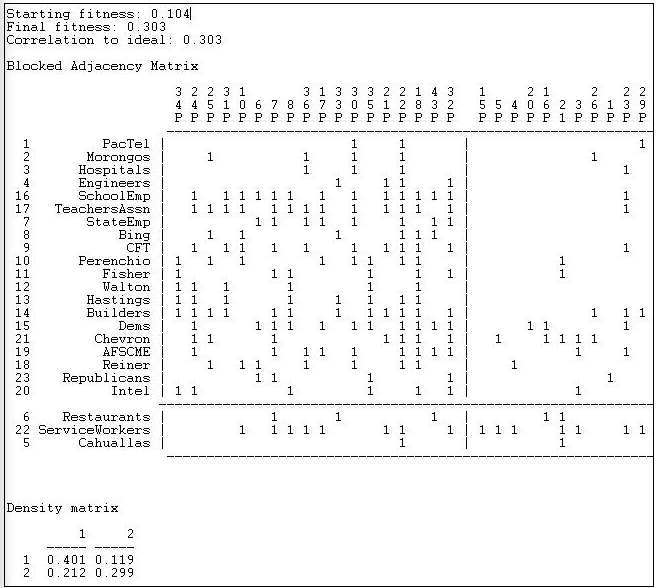
Figura 17.17: Modelo de facciones bimodales de donantes e iniciativas de boleta de California $1M (truncado)
Dos medidas de bondad de ajuste están disponibles. Primero tenemos nuestro puntaje de “aptitud”, que es la correlación entre las puntuaciones observadas (0 o 1) y las puntuaciones que “deberían” estar presentes en cada bloque. Las densidades en los bloques también nos informan sobre la bondad de ajuste. Para un análisis de facciones, un patrón ideal sería denso de 1 bloques a lo largo de la diagonal (muchos lazos dentro de grupos) y cero bloques fuera de la diagonal (lazos entre grupos).
El ajuste del modelo de las dos facciones no es tan impresionante como el ajuste del modelo núcleo-periferia. Esto sugiere que una “imagen” de la política de California como uno de los dos espacios separados y en gran parte disjuntos de actores de temas no es tan útil como una imagen de un núcleo de actores y temas de alta intensidad junto con un conjunto de temas y participantes de otro modo disjuntos.
El bloqueo en sí mismo tampoco es muy atractivo, colocando a la mayoría de los actores en una facción (con modesta densidad de 0.401). La segunda facción es pequeña, y tiene una densidad (0.299) que no es muy diferente de los bloques fuera de la diagonal. Como antes, el bloqueo de actores por eventos está agrupando conjuntos de actores y eventos que se definen entre sí.