
17.5: Distribución de Grados
- Page ID
- 115767
Otra propiedad topológica local que se puede medir localmente es, como ya comentamos, el grado de un nodo. Pero si los recogemos todos para toda la red y los representamos como una distribución, nos dará otra información importante sobre cómo está estructurada la red:
Una distribución de grados de una red es una distribución de probabilidad
\[P(k) =\frac{| \begin{Bmatrix} i | deg(i) =k \end{Bmatrix}| }{ n}. \label{(17.28)} \]
es decir, la probabilidad de que un nodo tenga grado\(k\).
La distribución de grados de una red se puede obtener y visualizar de la siguiente manera:


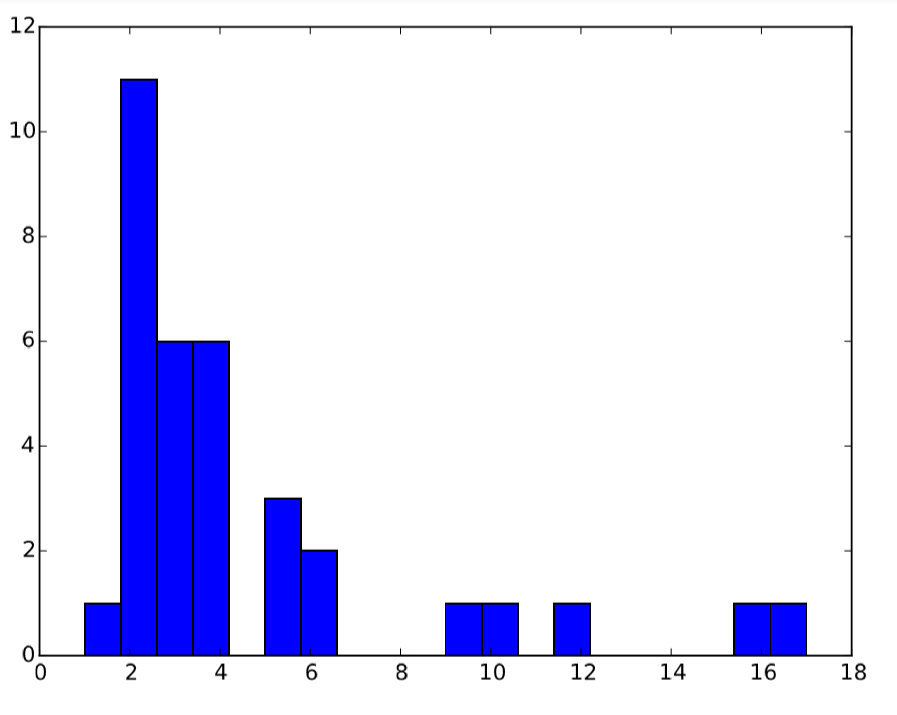
El resultado se muestra en la Fig. 17.5.1.
También se puede obtener la distribución real de grado P (k) de la siguiente manera:

Esta lista contiene el valor de (no normalizado)\(P(k) for k = 0,1,...,k_{max}\), en este orden. Para redes más grandes, a menudo es más útil trazar una lista de histogramas de grados normalizados en una escala log-log:



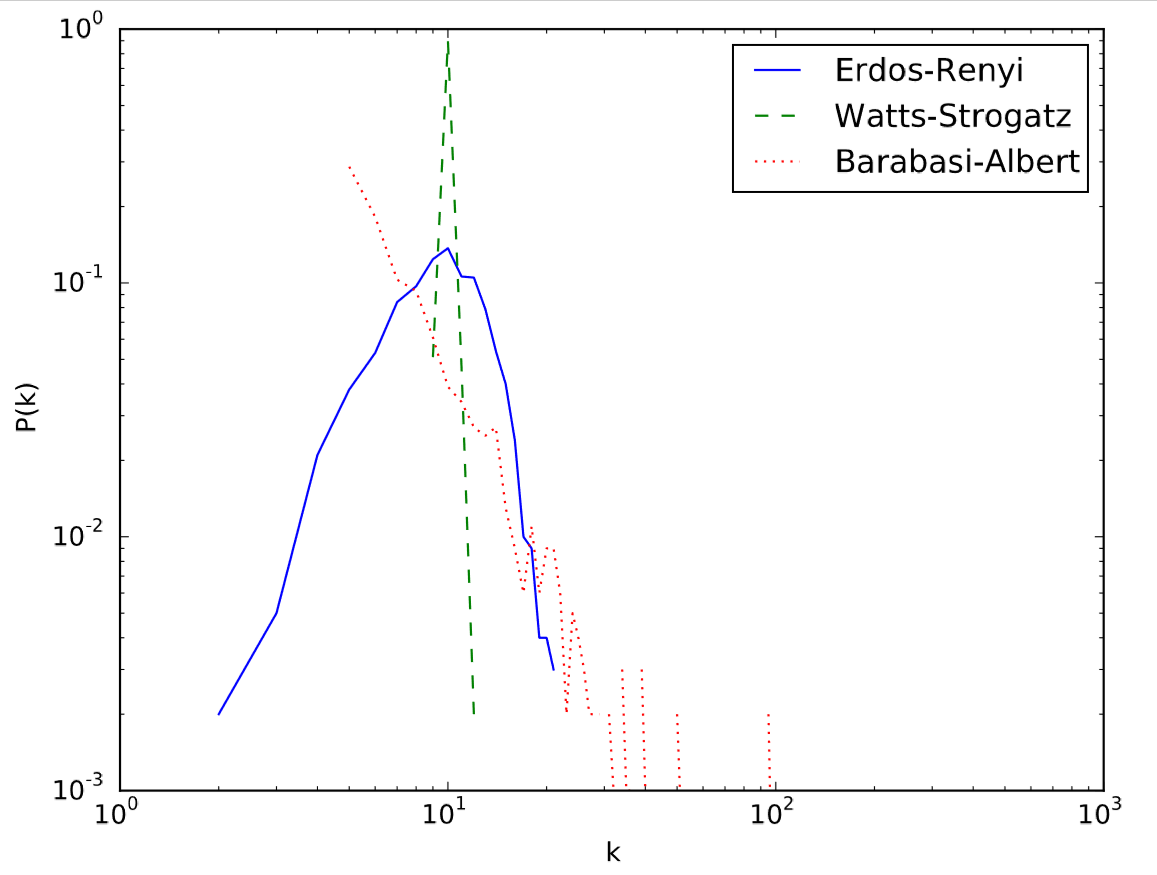
El resultado se muestra en la Fig. 17.5.2, que ilustra claramente las diferencias entre los tres modelos de red utilizados en este ejemplo. El modelo de red aleatoria Erd"os-R'enyi tiene una distribución de grados curvada en forma de campana, que aparece como una montaña sesgada en la escala log-log (línea continua azul). El modelo Watts-Strogatz es casi regular, y por lo tanto tiene un pico muy agudo en el grado promedio (línea discontinua verde;\ (k = 10\ 0 en este caso). El modelo Barab'asi-Albert tiene una distribución de grados de poder-ley, que parece una línea recta con una pendiente negativa en la escala log-log (línea punteada roja).
Además, a menudo es visualmente más significativo trazar no la distribución de grados en sí sino su función de distribución acumulativa complementaria (CCDF), definida de la siguiente manera:
\[F(k) =\sum_{k'=k} ^{\infty} P(k') \label{(17.29)} \]
Esta es una probabilidad de que un nodo tenga un grado\(k\) o superior. Por definición,\(F(0) = 1\) y\(F(k_{max} + 1) = 0\), y la función disminuye monótonamente a lo largo\(k\). Podemos revisar el Código 17.15 para dibujar CCDF:




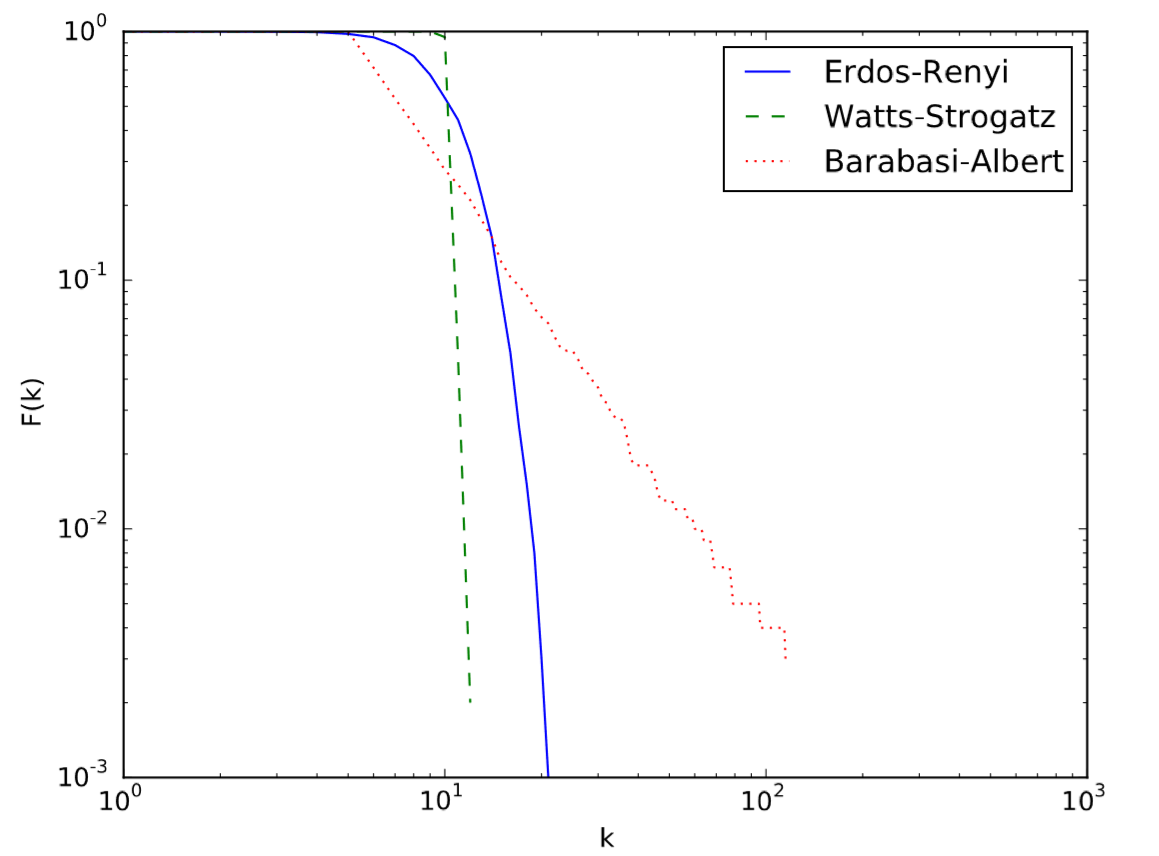
En este código, generamos ccdf's a partir de Pk calculando la suma de Pk después de dejar caer sus primeras k entradas. El resultado se muestra en la Fig. 17.5.2.
Como se puede ver en la figura, la distribución del grado de derecho de poder se mantiene como una línea recta en la trama de CCDF también, porque\(F(k)\) seguirá siendo una función de poder de\( k\), como se muestra a continuación:
\[F(k ) \begin{align} \sum_{k'=k} ^{\infty} {P(k')} = \sum_{k'=k} ^{infty}{ak' ^{-\gamma}} \label{(17.30)} \\ \approx \int_{k}^{infty} ak^{-\gamma}dk' = {\begin{bmatrix} \frac{ak^{J-\gamma+1}}{-\gamma + 1}\end{bmatrix}}^{\infty}_{k} = \frac{0-ak^{-\gamma+1}}{-\gamma +1} \label{(17.31)} \\ = \frac{a}{-\gamma -1}k ^{-(\gamma -1)} \label{(17.32)} \end{align} \]
Este resultado muestra que el exponente de escalado de\(F(k)\) para una distribución de grado de ley de potencia es menor que el de la distribución original por 1, lo que se puede ver visualmente comparando sus pendientes entre las Figs. 17.5.2 y 17.5.3.
Importe un gran conjunto de datos de red de su elección desde el sitio web de Network Data de Mark Newman: http://www-personal.umich.edu/~mejn/netdata/
Trazar la distribución de grados de la red, así como su CCDF. Determine si la red es más similar a un modelo de red aleatorio, de mundo pequeño o sin escala.
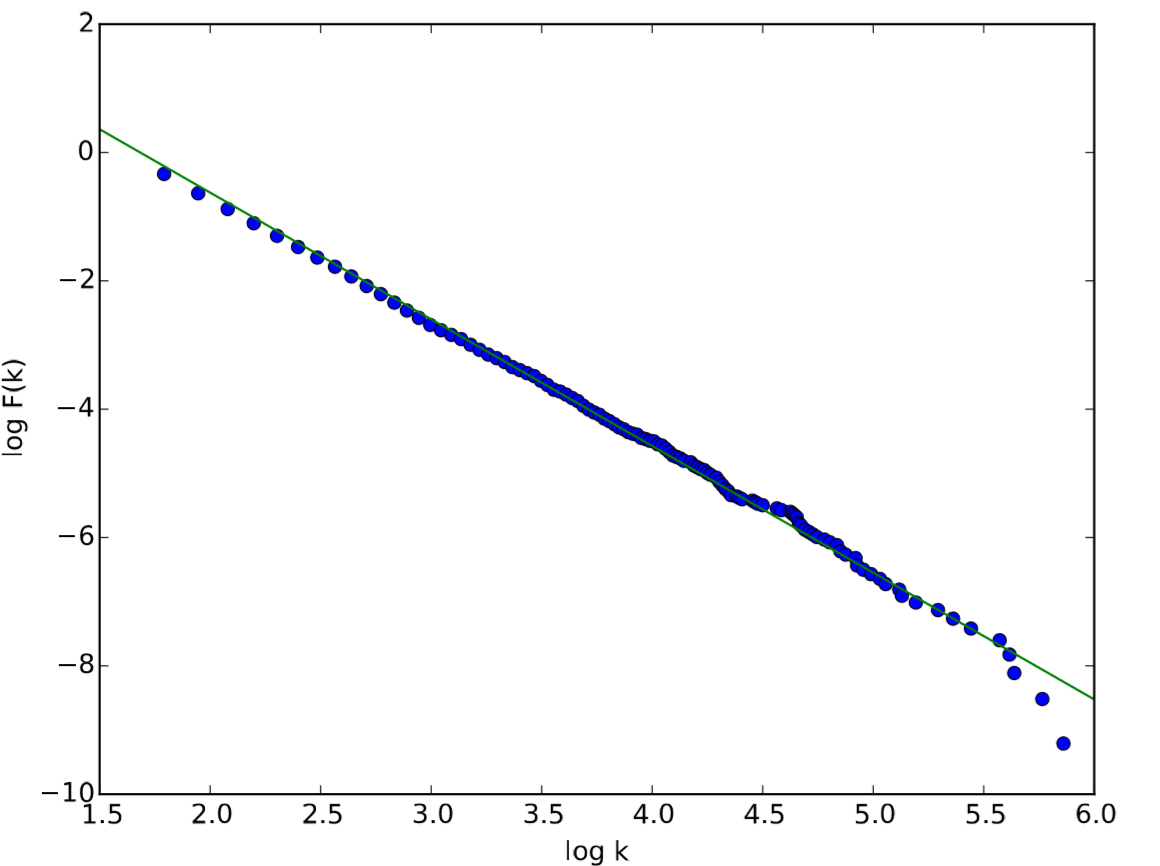
Si la distribución de grados de la red muestra un comportamiento de ley de poder, puede estimar su exponente de escalado a partir de la distribución mediante regresión lineal simple. Debe usar un CCDF de la distribución de grados para este propósito, porque los CCDF son menos ruidosos que las distribuciones de grado originales. Aquí hay un ejemplo de estimación de exponente de escala aplicada a una red Barab'asi-Albert, donde la función linregress en el módulo stats de SCiPy se usa para regresión lineal:



En el segundo bloque de código, el dominio y ccdf se convirtieron a escalas logarítmicas para el ajuste lineal. También, tenga en cuenta que el ccdf original contenía valores para todos los k' s, incluso para aquellos para los cuales\(P(k) = 0\). Esto causaría sesgos innecesarios en la regresión lineal hacia el extremo k superior donde las muestras reales eran muy escasas. Para evitar esto, solo se recogen los puntos de datos donde el valor de\(F\) cambiado (es decir, donde hubo nodos reales con grado k) en las listas logkdata y logfData.
El resultado se muestra en la Fig. 17.5.4, y también la siguiente salida sale al terminal, lo que indica que este fue un ajuste bastante bueno:

Obtener un gran conjunto de datos de red cuya distribución de grados parece seguir una ley de poder, de cualquier fuente (hay toneladas disponibles en línea, incluido el de Mark Newman que se introdujo antes). Luego estime su exponente de escalado usando regresión lineal.