
7.4: Apéndice - Métodos Modernos de Reserva de Pérdidas en Líneas de Cola Larga
- Page ID
- 65509
La estimación actuarial en la reserva de pérdidas se basa en datos de pagos de siniestros pasados. Estos datos se presentan típicamente en forma de triángulo, donde cada fila representa el período de accidente (o suscripción) y cada columna representa el período de desarrollo. El Cuadro 7.11 representa un triángulo hipotético de siniestros. Por ejemplo, los pagos para 2006 se presentan de la siguiente manera: 13 millones de dólares pagados en 2006 por el año de desarrollo 0, otros 60 millones pagados en el año de desarrollo 1 (es decir, 2007 = [2006+1]), y otros 64 millones pagados durante 2008 por el año de desarrollo 2. Tenga en cuenta que cada diagonal representa los pagos realizados durante un período calendario determinado. Por ejemplo, la última diagonal representa el pago realizado durante 2008.
| Año de Desarrollo | |||||||
|---|---|---|---|---|---|---|---|
| Año Accidente | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 2002 | 9,500 | 50,500 | 50,000 | 27,500 | 9,500 | 5,000 | 3,000 |
| 2003 | 13,000 | 44,000 | 53,000 | 33,500 | 11,500 | 5,000 | |
| 2004 | 14,000 | 47,000 | 56,000 | 29,500 | 15,000 | ||
| 2005 | 15,000 | 52,000 | 48,000 | 35,500 | |||
| 2006 | 13,000 | 60,000 | 64,000 | ||||
| 2007 | 16,000 | 47,000 | |||||
| 2008 | 17,000 | ? | |||||
El análisis actuarial tiene que proyectar cómo se desarrollarán las pérdidas hacia el futuro en función de su desarrollo pasado. La reserva de pérdidas es la estimación de todos los pagos que se realizarán en el futuro y aún se desconoce. Es decir, el papel del actuario es estimar todas las cifras que llenarán la parte inferior derecha en blanco de la tabla. El actuario tiene que “cuadrar el triángulo”. La tabla termina en el año de desarrollo 6, pero los pagos pueden continuar más allá de ese punto. Por lo tanto, el actuario también debe pronosticar más allá del horizonte conocido (más allá del año de desarrollo 6 en nuestra tabla), por lo que el papel es “rectanglizar el triángulo”.
El actuario puede utilizar una gran variedad de triángulos en la preparación del pronóstico: los datos podrían organizarse por meses, trimestres o años. Los datos podrían estar en cifras actuales o en cifras acumuladas. Los datos podrían representar números: el número de reclamaciones reportadas, el número de reclamaciones liquidadas, el número de reclamaciones aún pendientes, el número de reclamaciones cerradas, etc. Las cifras podrían representar pagos de reclamaciones como pagos corrientes, pagos por siniestros que se cerraron, reclamación incurrida cifras (es decir, los pagos reales más la estimación del caso), cifras indexadas, cifras promedio de siniestros, etc.
Todas las técnicas actuariales buscan identificar un patrón oculto en el triángulo, y utilizarlo para realizar el pronóstico. Algunas técnicas comunes son bastante intuitivas y se ocupan de identificar las relaciones entre los pagos realizados a lo largo de años de desarrollo consecutivos. Demostrémoslo en la Tabla 7.11 tratando de estimar los pagos esperados por accidente año 2008 durante 2009 (la celda con el signo de interrogación). Podemos intentar hacerlo encontrando una relación de los pagos en desarrollo año 1 a los pagos en desarrollo año 0. Contamos con información para accidentes años 2002 a 2007. La suma de los pagos realizados por estos años durante el año de desarrollo 1 es de $300,500 y la suma de pagos realizados durante el año de desarrollo 0 es de $80,500. La relación entre estas sumas es de 3.73. Multiplicamos esta relación por la cifra de $17,000 para el año 2008, lo que da una estimación de $63,410 en pagos que se realizarán por accidente año 2008 durante el año de desarrollo 1 (es decir, durante 2009). Tenga en cuenta que existen otras formas de calcular los ratios: en lugar de usar la relación entre sumas, podríamos haber calculado para cada año de accidente la relación entre el año de desarrollo 1 y el año de desarrollo 0, luego calculamos la relación promedio para todos los años. Esto daría un factor multiplicador diferente, resultando en un pronóstico diferente.
De manera similar, podemos calcular factores para pasar de cualquier otro periodo de desarrollo al siguiente (un conjunto de factores a utilizar para pasar de cada columna a la siguiente). Usando estos factores, podemos llenar todas las demás celdas en blanco en la Tabla 7.11. Obsérvese que la cifra de $63,410 que insertamos como estimación para el año accidente 2008 durante el año de desarrollo 1 se incluye en la estimación de la siguiente cifra en la tabla. En otras palabras, creamos un modelo recursivo, donde se utiliza el resultado de un paso para estimar el resultado del siguiente paso. Hemos creado una especie de “escalera de cadena”, ya que a menudo se hace referencia a estos métodos de pronóstico.
En el ejemplo anterior, utilizamos ratios para pasar de una celda a la siguiente. Pero este método de pronóstico es solo uno de los muchos que podríamos haber utilizado. Por ejemplo, podríamos crear fácilmente un modelo aditivo en lugar de un modelo multiplicativo (basado en proporciones). Podemos calcular la diferencia promedio entre columnas y usarla para subir de una celda a la celda faltante a su derecha. Por ejemplo, la diferencia promedio entre los pagos por el año de desarrollo 1 y el año de desarrollo 0 es de 36.667 dólares (calculados únicamente para las cifras para las que tenemos datos de ambos años de desarrollo 0 y 1, o 2002 a 2007). Por lo tanto, nuestra estimación alternativa para la cifra faltante en el Cuadro 7.11 los pagos que se esperan por accidente año 2008 durante 2009, es de $53,667 ($17,000 más 36.667). ¡Una estimación bastante diferente a la que obtuvimos antes!
Podemos crear modelos más complicados, y la literatura actuarial tradicional está llena de ellos. La característica común de los ejemplos anteriores es que están estimando el conjunto de factores del periodo de desarrollo. Sin embargo, también podría haber un conjunto de “factores de período de accidente” para dar cuenta de la posibilidad de que la cartera no siempre se mantenga constante entre años. En un año, pudo haber habido muchas pólizas o accidentes, mientras que en el otro año, podría haber habido menos. Entonces, podría haber otro conjunto de factores a utilizar al moverse entre filas (periodos de accidentes) en el triángulo. Adicionalmente, también podría haber un conjunto de factores de año calendario para describir los cambios realizados al pasar de una diagonal a otra. Tales efectos pueden ser el resultado de una multitud de razones, por ejemplo, una sentencia legal que obliga a un cambio de política o una inflación que aumenta los pagos promedio. Un modelo de pronóstico a menudo incorpora una combinación de tales factores. En nuestro ejemplo simple con un triángulo que tiene siete filas, podemos calcular seis factores en cada dirección: seis para los períodos de desarrollo (efectos de columna), seis para los períodos de accidente (efectos de fila) y seis para las diagonales (efectos calendario o año de pago). El análisis de un triángulo tan simple puede incluir dieciocho factores (o parámetros). Un triángulo más grande (que es el caso común en la práctica) donde se utilizan muchos periodos (meses, trimestres y años) implica la estimación de demasiados parámetros, pero se pueden usar modelos más simples con un número mucho menor de factores (ver abajo).
Aunque los métodos anteriores son muy atractivos intuitivamente y todavía se utilizan comúnmente para la reserva de pérdidas, todos sufren de grandes inconvenientes y no son ideales para su uso. Resumimos algunas de las principales deficiencias:
- El uso de factores en las tres direcciones (año del accidente, año de desarrollo y año de pago) puede dar lugar a contradicciones. Tenemos la libertad de determinar dos direcciones cualesquiera, pero la tercera es determinada automáticamente por las dos primeras.
- A menudo existe la necesidad de pronosticar “más allá del horizonte”, es decir, estimar lo que se pagará en los años de desarrollo posteriores al sexto año en nuestro ejemplo. Los diversos modelos de escalera de cadena no pueden hacer esto.
- Siempre podemos encontrar una fórmula matemática que describa todos los puntos de datos, pero le faltará un buen poder predictivo. En el siguiente periodo, obtenemos nuevos datos y un triángulo más grande. Los nuevos datos adicionales a menudo nos harán usar un conjunto completamente diferente de factores, incluidos los relacionados con períodos anteriores. La necesidad de cambiar todos los factores es problemática, ya que indica inestabilidad del modelo y falta de poder predictivo. Esto sucede debido a la sobreparametrización (un punto muy crucial que merece una explicación más detallada, como se proporciona a continuación).
- No existen pruebas estadísticas de validez de los factores. Por lo tanto, es imposible entender qué parámetros (factores) son estadísticamente significativos. Para ilustrar, es claro que un factor (parámetro) basado en una relación entre solo dos puntos de datos (por ejemplo, un factor de desarrollo para el sexto año, que se basará en las dos cifras en la esquina extrema derecha del triángulo de la Tabla 7.11) es naturalmente menos confiable, aunque puede drásticamente afectar a todo el pronóstico.
- El uso de relaciones simples para crear los factores puede ser injustificado porque las relaciones entre dos celdas podrían ser más complicadas. Por ejemplo, podría ser que una celda vecina se obtenga examinando la primera celda, agregando una constante y luego multiplicando por una relación. Los estudios han demostrado que la mayoría de las reservas de pérdidas calculadas con modelos de escalera de cadena están sufriendo este problema.
- Los métodos de escalera de cadena crean una cifra determinista para las reservas de pérdidas. No tenemos idea de lo confiable que es. Es claro que hay cero probabilidad de que el pronóstico prevea exactamente la cifra exacta futura. Pero la gerencia agradecería tener una idea sobre el rango de posibles desviaciones entre las cifras reales y el pronóstico.
- Las técnicas más comunes se basan en triángulos con cifras acumulativas. La ventaja de las cifras acumulativas es que suprimen la variabilidad del patrón de reclamos y crean una ilusión de estabilidad. Sin embargo, al tomar cifras acumulativas en lugar de no acumuladas, a menudo perdemos mucha información y podemos pasar por alto importantes puntos de inflexión. Es similar a lo que puede hacer un minero de oro tirando, en lugar de guardar, las pequeñas pepitas de oro que se pueden encontrar en enormes montones de rocas inútiles.
- Muchos actuarios siguen utilizando triángulos de cifras de siniestros incurridos. Las cifras incurridas son la suma de los números efectivamente pagados más las estimaciones de pagos futuros suministrados por el personal del departamento de siniestros. Los factores actuariales resultantes de dichos triángulos están fuertemente influenciados por los cambios realizados por el departamento de siniestros de un periodo a otro. Dichos cambios no deben incluirse en la previsión de tendencias futuras.
Existen modernas técnicas actuariales basadas en sofisticadas herramientas estadísticas que podrían utilizarse para dar mejores pronósticos a la vez que se utilizan los mismos triángulos de pérdida.El lector interesado debe buscar publicaciones del profesor B. Zehnwirth, pionero del enfoque descrito, en actuarial literatura. Uno de los autores (Y. Kahane) ha colaborado con él, y se ha realizado mucho trabajo actuarial con estas herramientas. El enfoque ahora es bien aceptado en todo el mundo. La gráfica se derivó utilizando recursos desarrollados por Insurware Pty. (www.insureware.com). Veamos cómo funciona esto sin involucrarse en una complicada discusión estadística. El propósito de la discusión es incrementar la comprensión de los principios, pero no esperamos que el alumno típico pueda realizar inmediatamente el análisis. Dejaremos en gran medida el análisis a actuarios que estén mejor equipados con las herramientas matemáticas y estadísticas necesarias.
Un buen modelo es evaluado por su sencillez y generalidad. Tener un modelo complejo con muchos parámetros lo hace complicado y menos general. Los modelos de escalera de cadena que se discutieron anteriormente sufren de este problema de sobreparametrización, y los modelos alternativos que se explican a continuación superan esta dificultad.
Comencemos simplemente mostrando los datos de la Tabla 7.11 en forma gráfica en la Figura\(\PageIndex{1}\). Los puntos verdes describen los puntos de datos originales (las reclamaciones pagadas en el eje vertical y los años de desarrollo en el eje horizontal). Para mostrar el patrón general, se agregó una línea que representa los promedios de cada año de desarrollo. Vemos que los pagos de reclamo en esta línea de negocio tienden a aumentar, alcanzar un pico después de algunos años, luego disminuir lentamente con el tiempo y tener una estrecha “cola” (es decir, se van a pagar pequeñas cantidades en el futuro lejano).
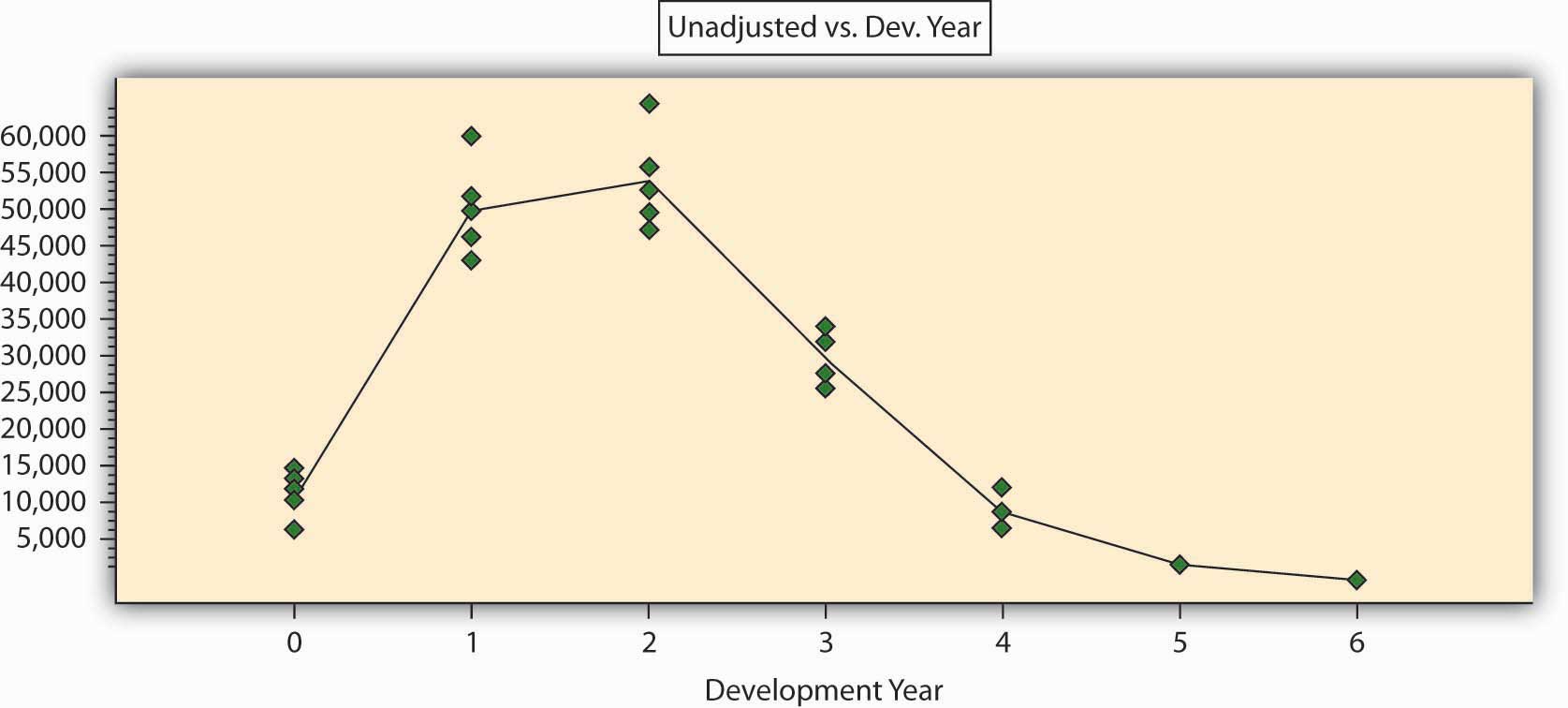 Figura
\(\PageIndex{1}\): Reclamaciones pagadas (en miles de dólares) por año de
desarrollo
Figura
\(\PageIndex{1}\): Reclamaciones pagadas (en miles de dólares) por año de
desarrolloDe inmediato podemos ver que todo el triángulo de siniestros puede analizarse de una manera completamente diferente: ajustando una curva a través de los puntos. Una de estas herramientas para posibilitar esto podría ser el análisis de regresión. Tal herramienta puede darnos una mejor comprensión del patrón oculto que el método de la escalera de cadena. Vemos que la curva particular en nuestro caso es no lineal, lo que significa que necesitamos más de dos parámetros para describirla matemáticamente. Cuatro parámetros probablemente bastarán para dar una función matemática que describa el patrón de la Figura\(\PageIndex{1}\). El uso de tales métodos puede alcanzar un nivel de sofisticación que va más allá del alcance de este libro. Es suficiente decir que podemos obtener una excelente descripción matemática del patrón con el uso de sólo cuatro a seis parámetros (factores). Esto se puede medir mediante una variedad de indicadores estadísticos. El coeficiente de correlación para dicha fórmula matemática es superior al 95 por ciento, y los parámetros son estadísticamente significativos.
Tal enfoque es más simple y más general que cualquier modelo de escalera de cadena. Se puede utilizar para pronosticar más allá del horizonte, puede ser estadísticamente probado y validado, y puede dar una buena idea sobre el nivel de error que se puede esperar. Cuando un modelo se basa solo en unos pocos parámetros, se vuelve más “tolerante” a las desviaciones: es evidente que el pago del siguiente periodo diferirá del pronóstico, pero no nos obligará a cambiar el modelo. Desde el punto de vista del actuario, los pagos de siniestros son variables estocásticas y nunca deben considerarse como un proceso determinista, entonces, ¿por qué utilizar un análisis determinista de escalera de cadenas?
Es muy recomendable, y en realidad esencial, basar el análisis en un triángulo de siniestros no acumulativos. El análisis estadístico no ofrece buenas herramientas para cifras acumulativas; desconocemos sus procesos estadísticos subyacentes y, por lo tanto, no podemos ofrecer buenas pruebas de significación estadística. El análisis estadístico que se basa en las cifras actuales de siniestros no acumulativos es muy sensible y puede detectar fácilmente puntos de inflexión y patrones cambiantes.
Debe mencionarse un último punto. La clave del análisis de regresión es el análisis de los residuales, es decir, las diferencias entre las afirmaciones observadas y las cifras que son estimadas por el modelo. Los residuos deben distribuirse aleatoriamente alrededor de las cifras pronosticadas, modeladas. Si no se distribuyen aleatoriamente, se puede mejorar el modelo. Es decir, los residuos son la brújula que guía al actuario en la búsqueda del mejor modelo. Los análisis actuariales tradicionales basados en modelos de escalera de cadena consideran la variabilidad como un elemento corrupto y se esfuerzan por deshacerse de las desviaciones para llegar a un pronóstico determinista. Al hacerlo, los actuarios tiran la única información real en los datos y basan el análisis solo en la parte no informativa. A veces las fluctuaciones son muy grandes, y la compañía de seguros está trabajando en un entorno de reclamos muy incierto, casi caótico. Si el actuario encuentra que este es el caso, será información importante para los directivos y no debe ocultarse ni sustituirse por un pronóstico determinista, sino sin sentido.