
14.2: Comprender la búsqueda
- Page ID
- 60944
Objetivos de aprendizaje
Después de estudiar esta sección deberías poder hacer lo siguiente:
- Comprender la mecánica de la búsqueda, incluyendo cómo Google indexa la Web y clasifica sus resultados de búsqueda orgánicos.
- Examine la infraestructura que impulsa a Google y cómo su escala y complejidad ofrecen ventajas competitivas clave.
Antes de sumergirse en cómo gana dinero la firma, primero entendamos cómo funciona el servicio principal de Google, la búsqueda.
Realiza una búsqueda (o consulta) en Google u otro buscador, y los resultados que verás son referidos por profesionales de la industria como búsqueda orgánica o natural. Los motores de búsqueda utilizan diferentes algoritmos para determinar el orden de los resultados de búsqueda orgánicos, pero en Google el método se llama PageRank (un poco de juego de palabras, clasifica las páginas Web, y fue desarrollado inicialmente por el cofundador de Google, Larry Page). Google no acepta dinero para la colocación de enlaces en los resultados de búsqueda orgánicos. En cambio, los resultados de PageRank son una especie de concurso de popularidad. Las páginas web que tienen más páginas enlazadas a ellas se clasifican más altas.
Figura 14.4
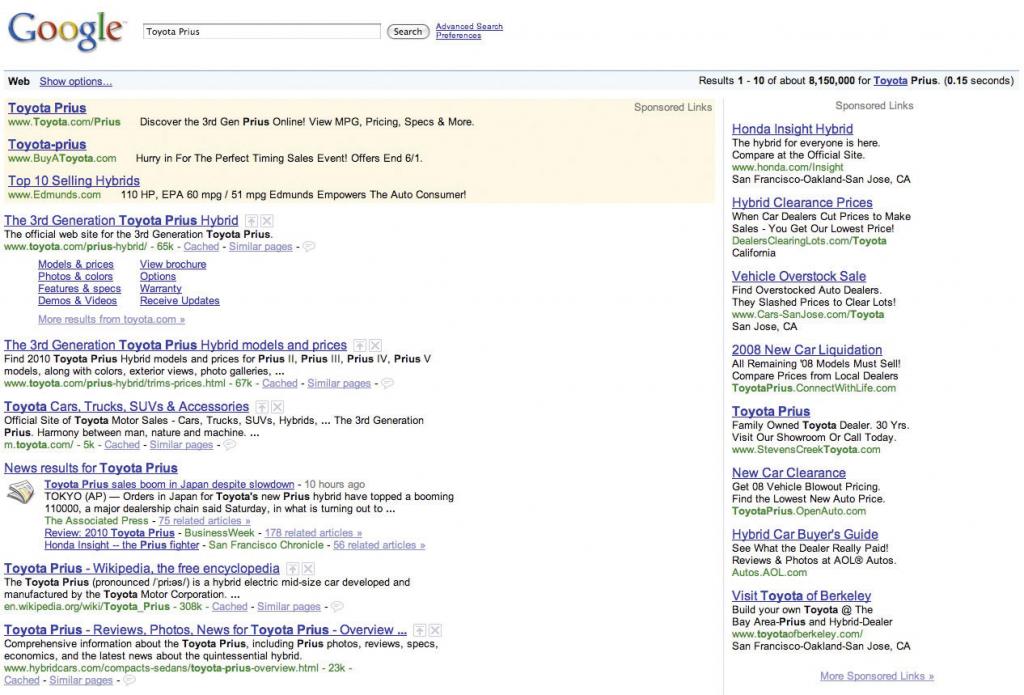
La consulta de “Toyota Prius” desencadena resultados de búsqueda orgánicos, flanqueados arriba y derecha por anuncios de enlaces patrocinados.
El proceso de mejorar los resultados de búsqueda orgánica de una página a menudo se conoce como optimización de motores de búsqueda (SEO). El SEO se ha convertido en una función crítica para muchas organizaciones de marketing, ya que si las páginas de una empresa no están cerca de la parte superior de los resultados de búsqueda, los clientes nunca descubren su sitio.
Google es un poco vago sobre los detalles de precisamente cómo se ha refinado PageRank, en parte porque muchos han intentado jugar con el sistema. Además de los enlaces in-bound, los resultados de búsqueda orgánica de Google también consideran otras doscientas señales, y el equipo de calidad de búsqueda de la firma está analizando incesantemente el comportamiento de los usuarios en busca de pistas sobre cómo modificar el sistema para mejorar la precisión (Levy, 2010). Los menos escrupulosos han intentado crear una serie de sitios web falsos, todos enlazando de nuevo a las páginas que están tratando de promover (esto se llama fraude de enlaces, y Google trabaja activamente para descubrir y cerrar tales esfuerzos). Sabemos que los enlaces de algunos sitios Web tienen más peso que otros. Por ejemplo, los enlaces de sitios web que Google considera “influyentes”, y los enlaces de la mayoría de los sitios web “.edu”, tienen mayor peso en los cálculos de PageRank que los enlaces de sitios “.com” comunes.
Arañas y Bots y Crawlers — ¡Oh, Dios mío!
Al realizar una búsqueda a través de Google u otro motor de búsqueda, en realidad no estás buscando en la Web. Lo que realmente sucede es que los principales buscadores hacen lo que equivale a una copia de la Web, almacenando e indexando el texto de los documentos en línea en sus propias computadoras. El índice de Google considera más de un billón de URL (Wright, 2009). La esquina superior derecha de una consulta de Google te muestra lo rápido que puede tener lugar una búsqueda (en el ejemplo anterior, los rankings de más de ocho millones de resultados que contienen el término “Toyota Prius” se entregaron en menos de dos décimas de segundo).
Para crear estos índices masivos, las empresas de búsqueda utilizan software para rastrear la Web y descubrir tanta información como puedan encontrar. Este software es referido por varios nombres diferentes: robots de software, arañas, rastreadores web, pero todos funcionan prácticamente de la misma manera. Para que sus sitios web sean visibles, cada firma en línea proporciona una lista de todos los servidores públicos con nombre en su red, conocidos como listados de servicio de nombres de dominio (DNS). Por ejemplo, Yahoo! tiene diferentes servidores que se pueden encontrar en http://www.yahoo.com, sports.yahoo.com, weather.yahoo.com, finance.yahoo.com, y así sucesivamente. Las arañas comienzan en la primera página de cada servidor público y siguen todos los enlaces disponibles, atravesando un sitio web hasta que se descubren todas las páginas.
Google rastreará sitios que se actualizan con frecuencia, como los dirigidos por organizaciones de noticias, tantas veces por hora como varias veces por hora. Rara vez actualizados, es posible que los sitios menos populares solo se reindexen cada pocos días. El método utilizado para rastrear la Web también significa que si un sitio Web no es la primera página de un servidor público, o no está vinculado desde otra página pública, entonces nunca se encontrará 1. También tenga en cuenta que cada motor de búsqueda también ofrece una página donde puede enviar su sitio Web para su indexación.
Si bien los motores de búsqueda te muestran lo que han encontrado en su copia de los contenidos de la Web; al hacer clic en un resultado de búsqueda, te dirigirá al sitio web real, no a la copia. Pero a veces vas a hacer clic en un resultado sólo para encontrar que el sitio Web no coincide con lo que encontró el motor de búsqueda. Esto sucede si un sitio Web se actualizó antes de que su motor de búsqueda tuviera la oportunidad de reindexar los cambios. En la mayoría de los casos aún puedes sacar la copia de la página del motor de búsqueda. Simplemente haga clic en el enlace “Cached” debajo del resultado (el término caché se refiere a un espacio de almacenamiento temporal utilizado para acelerar las tareas de computación).
Pero, ¿y si quieres que el contenido de tu sitio web permanezca fuera de los límites de la indexación y el almacenamiento en caché en buscadores? Las organizaciones han creado un conjunto de estándares para detener el rastreo de arañas, y todos los motores de búsqueda comerciales han acordado respetar estos estándares. Una forma es poner una línea de código HTML incrustada de manera invisible en un sitio Web que indique a todos los robots de software que dejen de indexar una página, que dejen de seguir enlaces en la página o que dejen de ofrecer archivos de páginas antiguas en una caché. Los usuarios no ven este código, pero los rastreadores web comerciales sí. Para aquellos familiarizados con el código HTML (el lenguaje utilizado para describir un sitio web), el comando para evitar que los rastreadores web indicen una página, sigan enlaces y enumeren archivos de páginas en caché se ve así:
‣ META NOMBRE= “ROBOTS” CONTENIDO= “NOINDEX, NOFOLLOW, NOARCHIVE” ⟩
También hay otras técnicas para mantener alejadas a las arañas. Los administradores de sitios web pueden agregar un archivo especial (llamado robots.txt) que proporcione instrucciones similares sobre cómo el software de indexación debe tratar el sitio Web. Y mucho contenido se encuentra dentro de la “web oscura”, ya sea detrás de firewalls corporativos o inaccesibles para aquellos que no tienen una cuenta de usuario, piense en actualizaciones privadas de Facebook que nadie puede ver a menos que sean tus amigos, todo eso está fuera del alcance de Google.
¿Qué se necesita para ejecutar esta cosa?
Sergey Brin y Larry Page iniciaron Google con solo cuatro computadoras depuradas (Liedtke, 2008). Pero en una década, la infraestructura utilizada para alimentar al soberano de búsqueda se ha disparado hasta el punto en que ahora es la más grande de su tipo en el mundo (Carr, 2006). Google no revela la cantidad de servidores que utiliza, pero según algunas estimaciones, ejecuta más de 1.4 millones de servidores en más de una docena de las llamadas granjas de servidores en todo el mundo (Katz, 2009). En 2008, la firma gastó 2.180 millones de dólares en gastos de capital, con centros de datos, servidores y equipos de redes consumiendo la mayor parte de este costo 2. Construir granjas de servidores masivas para indexar la web en constante crecimiento es ahora el costo de admisión para cualquier empresa que quiera competir en el mercado de búsqueda. Esto claramente ya no es un juego para dos estudiantes de posgrado que trabajan en una cochera.
Centro de datos de contenedores de Google
Haz un recorrido virtual por uno de los centros de datos de Google.
El tamaño de esta inversión no solo crea una barrera de entrada, sino que influye en la rentabilidad de la industria, ya que Google, líder del mercado, disfruta de enormes economías de escala. Las empresas pueden gastar la misma cantidad para construir granjas de servidores, pero si Google tiene casi el 70 por ciento de este mercado (y creciendo) mientras que la búsqueda de Microsoft atrae menos de una séptima parte del tráfico, ¿cuál crees que disfruta del mejor retorno de la inversión?
Los componentes de hardware que alimentan a Google no son particularmente especiales. En la mayoría de los casos, la firma usa el tipo de procesadores Intel o AMD, discos duros de gama baja y chips RAM que encontrarías en una PC de escritorio. Estos componentes están alojados en servidores montados en rack de aproximadamente 3.5 pulgadas de grosor, cada servidor contiene dos procesadores, ocho ranuras de memoria y dos discos duros.
En algunos casos, Google monta racks de estos servidores dentro de contenedores de envío de tamaño estándar, cada uno con hasta 1,160 servidores por caja (Shankland, 2009). Un centro de datos determinado puede tener docenas de estos contenedores llenos de servidor, todos vinculados entre sí. Redundancia es el nombre del juego. Google asume que los componentes individuales fallarán regularmente, pero ninguna falla única debería interrumpir las operaciones de la empresa (haciendo que la configuración lo que los geeks llaman tolerante a fallas). Si algo se rompe, un técnico puede cambiarlo fácilmente por un reemplazo.
Cada diseño de granja de servidores también ha sido cuidadosamente diseñado con énfasis en reducir el consumo de energía y los requisitos de refrigeración. Y el software personalizado de la empresa (gran parte de él basado en productos de código abierto) permite que todos estos equipos funcionen como la computadora de red más grande del mundo.
La búsqueda web es una tarea particularmente adecuada para la arquitectura masivamente paralela utilizada por Google y sus rivales. Para una analogía de cómo funciona esto, imagina que trabajando solo, necesitas tratar de encontrar una frase en particular en un documento de cien páginas (eso es un esfuerzo de un servidor). A continuación, imagina que puedes distribuir la tarea entre cinco mil personas, dándole a cada una de ellas una oración separada para escanear (esa es la cuadrícula multiservidor). Esta diferencia le da una idea de cómo las empresas de búsqueda utilizan un gran número de servidores y el enfoque de dividir y conquistar de la computación en red para encontrar rápidamente las agujas que está buscando dentro del pajar de la Web. (Para obtener más información sobre la computación en red, consulte el Capítulo 5 “La ley de Moore: computación rápida, barata y lo que significa para el gerente”, y para obtener más información sobre granjas de servidores, consulte el Capítulo 10 “Software en flujo: parcialmente nublado y a veces gratis”.)
Figura 14.5

Google Search Appliance es un producto de hardware que las empresas pueden adquirir para ejecutar la tecnología de búsqueda de Google dentro de la privacidad y seguridad del firewall de una organización.
Google incluso te venderá un poco de su tecnología para que puedas ejecutar tu propio pequeño Google internamente sin compartir documentos con el resto del mundo. La línea de dispositivos de búsqueda de Google son servidores montados en rack que pueden indexar documentos dentro del sitio web de una corporación, incluso especificando contraseña y acceso de seguridad por documento. Vender hardware no es un negocio grande para Google, y otros proveedores ofrecen soluciones similares, pero los dispositivos de búsqueda pueden ser herramientas vitales para bufetes de abogados, bancos de inversión y otras organizaciones ricas en documentos.
Trendspotting con Google
Google no solo te da resultados de búsqueda, sino que te permite ver tendencias agregadas en lo que buscan sus usuarios, y esto puede generar información poderosa. Por ejemplo, al rastrear las tendencias de búsqueda de síntomas de gripe, el sitio web de Google Flu Trends puede identificar brotes de una a dos semanas más rápido que los Centros para el Control y la Prevención de Enfermedades (Bruce, 2009). ¿Quieres ir más allá de la gripe? Los servicios Trends e Insights for Search de Google permiten a cualquiera explorar las tendencias de búsqueda, desglosando el análisis por región, categoría (imagen, noticias, producto), fecha y otros criterios. Los gerentes inteligentes pueden aprovechar estas y otras herramientas similares para el análisis competitivo, comparando una empresa, sus marcas y sus rivales.
Figura 14.6
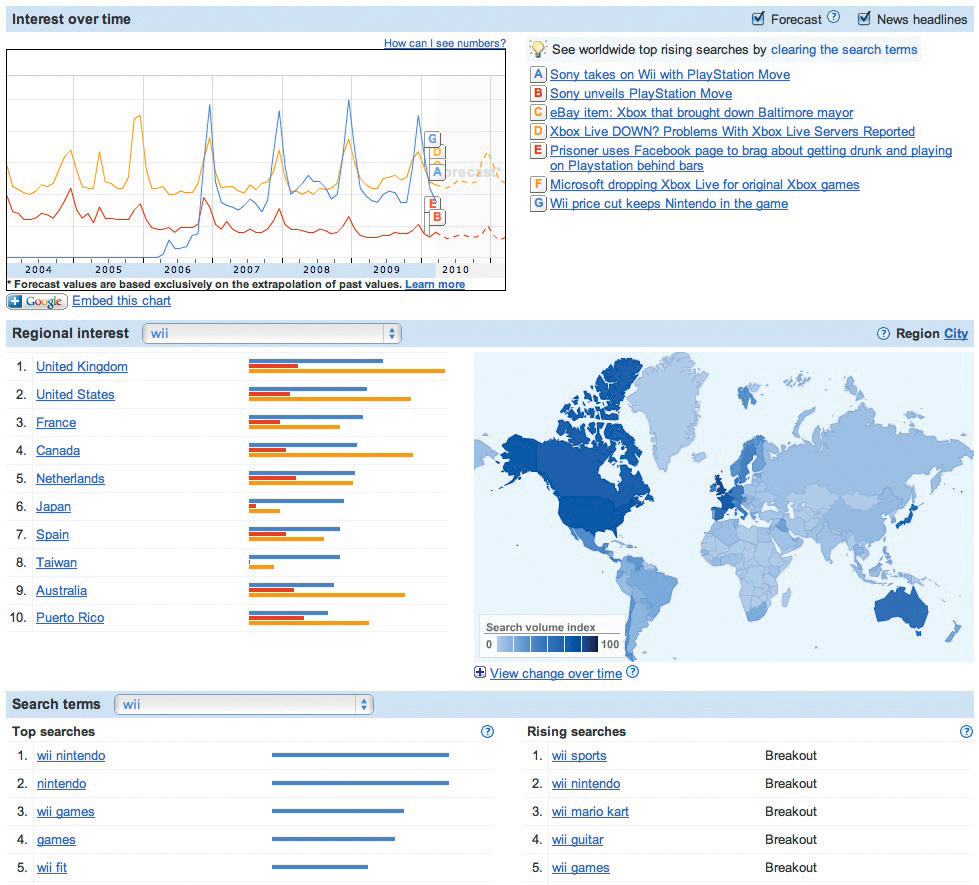
Google Insights for Search puede ser una herramienta útil para el análisis competitivo y el descubrimiento de tendencias. El gráfico anterior muestra una comparación (durante un periodo de doce meses, y geográficamente) del interés de búsqueda en los términos Wii, Playstation y Xbox.