3.7: Una visión heurística de la función de densidad de probabilidad
- Page ID
- 73959

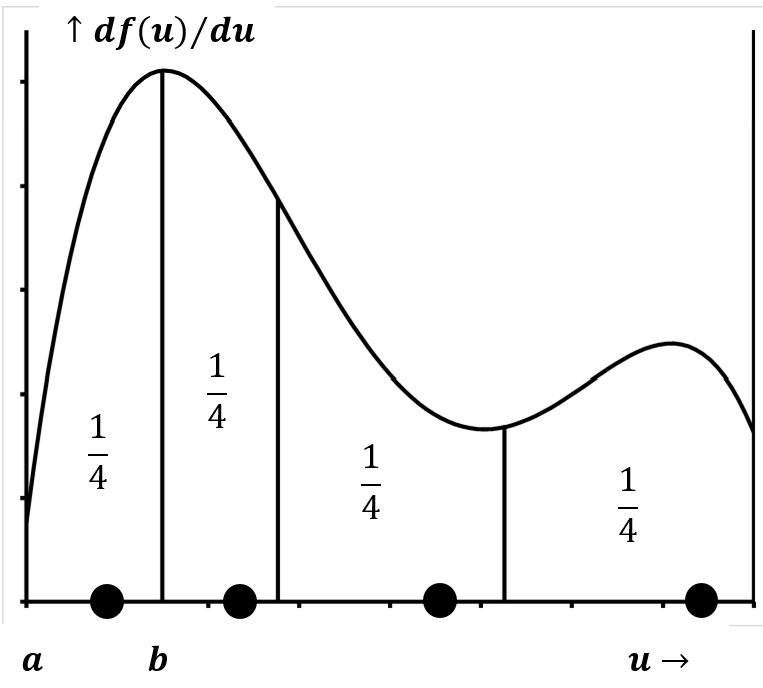
Supongamos que tenemos una función de densidad de probabilidad como la esbozada en la Figura 8 y que el área bajo la curva en el intervalo\(a<u<b\) es 0.25. Si dibujamos un gran número de muestras de la distribución, nuestras definiciones de probabilidad y la función de densidad de probabilidad significan que alrededor del 25% de los valores que dibujamos estarán en el intervalo\(a<u<b\). Esperamos que el porcentaje se acerque cada vez más al 25% ya que el número total de muestras extraídas se vuelve muy grande. Lo mismo sería cierto para cualquier otro intervalo,\(c<u<d\), donde el área bajo la curva en el intervalo\(c<u<d\) es 0.25.
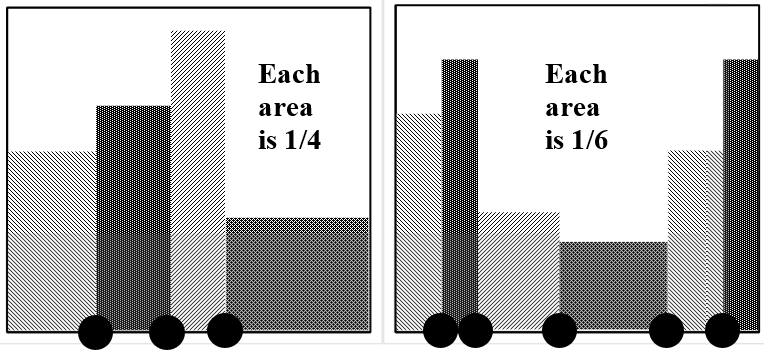
Si dibujamos exactamente cuatro muestras de esta distribución, los valores pueden estar en cualquier parte del dominio de\(u\). No obstante, si nos preguntamos qué disposición de cuatro valores se aproxima mejor al resultado de dibujar un gran número de muestras, es claro que esta disposición debe tener un valor en cada una de las cuatro zonas de probabilidad del 25%, mutuamente excluyentes. Podemos extender esta conclusión a cualquier número de puntos representativos. Si nos preguntamos qué disposición de N puntos representaría mejor la disposición de un gran número de puntos extraídos de la distribución, la respuesta es claramente que uno de los puntos\(N\) representativos debe estar dentro de cada uno de los segmentos\(N\), mutuamente exclusivos, de igual área que abarcan el dominio de\(u\).)
Podemos darle la vuelta a esta idea. A falta de información en contrario, la mejor suposición que podemos hacer sobre un conjunto de\(N\) valores de una variable aleatoria es que cada uno representa un resultado igualmente probable. Si todo nuestro almacén de información sobre una distribución consta de cuatro puntos de datos extraídos de la distribución, la mejor descripción que podemos dar de la función de densidad de probabilidad es que un cuarto del área bajo la curva se encuentra por encima de un segmento del dominio que está asociado a cada punto. Si tenemos\(N\) puntos, la mejor estimación que podemos hacer de la distribución de la que se extraen los\(N\) puntos es la\({\left({1}/{N}\right)}^{th}\) del área que se encuentra por encima de cada uno de ellos.
Esta vista nos dice asociar una probabilidad de\({1}/{N}\) con un intervalo alrededor de cada punto de datos, pero no nos dice por dónde comenzar o terminar el intervalo. Si pudiéramos decidir dónde comenzó y terminó el intervalo sobre cada punto de datos, podríamos estimar la forma de la función de densidad de probabilidad. Por un pequeño número de puntos, no podíamos esperar que esta estimación fuera muy precisa, pero sería la mejor estimación posible con base en los datos dados.
Ahora, en lugar de tratar de encontrar el mejor intervalo para asociar con cada punto de datos, pensemos en los intervalos en los que los puntos de datos dividen el dominio. Este pequeño cambio de perspectiva nos lleva a una forma lógica de dividir el dominio de\(u\) en intervalos específicos de igual probabilidad. Si ponemos\(N\) puntos en alguna línea, estos puntos dividen la línea en\(N+1\) segmentos. Hay un segmento a la izquierda de cada punto; hay\(N\) tales segmentos. Hay un segmento final a la derecha del punto más a la derecha, y así hay\(N+1\) segmentos en todos.
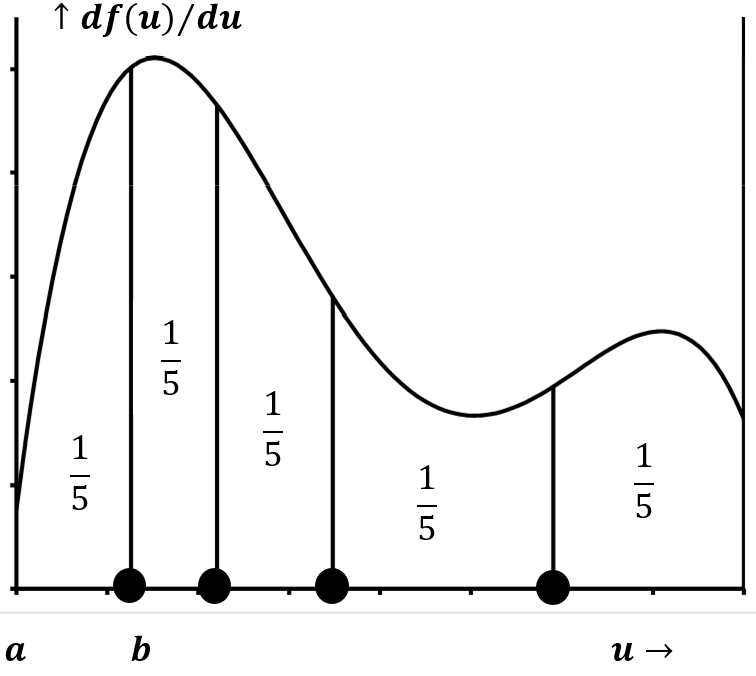
A falta de información en contrario, la mejor suposición que podemos hacer es que\(N\) los puntos de datos dividen su dominio en\(N+1\) segmentos, cada uno de los cuales está asociado con igual probabilidad. La fracción del área por encima de cada uno de estos segmentos es\({1}/{\left(N+1\right)}\); además, la probabilidad asociada a cada segmento es\({1}/{\left(N+1\right)}\). Si, como en el ejemplo anterior, hay cuatro puntos de datos, la mejor suposición que podemos hacer sobre la función de densidad de probabilidad es que el 20% de su área se encuentra entre el límite izquierdo y el punto de datos más a la izquierda, y el 20% se encuentra entre el punto de datos más a la derecha y el límite derecho. Los tres intervalos entre los cuatro puntos de datos representan cada uno un 20% adicional del área. La Figura 9 indica los puntos de\(N\) datos que mejor se aproximan a la distribución esbozada en la Figura 8.
Los bocetos de la Figura 10 describen las funciones de densidad de probabilidad implícitas en los conjuntos de puntos de datos indicados.