
16.6: Ácidos Nucleicos- Partes, Estructura y Función
- Page ID
- 72577
- Describir los dos tipos de ácidos nucleicos y la función de cada tipo.
- Describir la estructura secundaria del ADN y la importancia del apareamiento de bases complementarias.
- Describir cómo se sintetiza una nueva copia de ADN.
Las unidades repetitivas, o monómeras, que se unen entre sí para formar ácidos nucleicos se conocen como nucleótidos. El ácido desoxirribonucleico (ADN) de una célula típica de mamífero contiene aproximadamente 3 × 10 9 nucleótidos. Los nucleótidos se pueden descomponer adicionalmente en ácido fosfórico (H 3 PO 4), un azúcar pentosa (un azúcar con cinco átomos de carbono) y una base nitrogenada (una base que contiene átomos de nitrógeno).
\[\mathrm{nucleic\: acids \underset{down\: into}{\xrightarrow{can\: be\: broken}} nucleotides \underset{down\: into}{\xrightarrow{can\: be\: broken}} H_3PO_4 + nitrogen\: base + pentose\: sugar} \nonumber \]
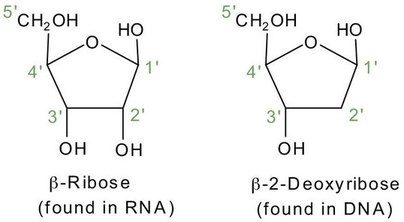
Si el azúcar pentosa es ribosa, el nucleótido se conoce más específicamente como ribonucleótido, y el ácido nucleico resultante es ácido ribonucleico (ARN). Si el azúcar es 2-desoxirribosa, el nucleótido es un desoxirribonucleótido, y el ácido nucleico es ADN.
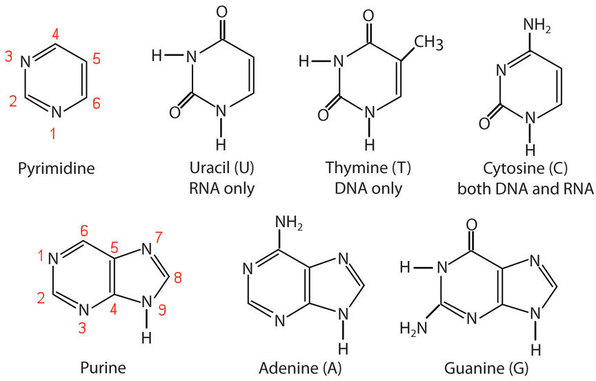
Las bases nitrogenadas que se encuentran en los nucleótidos se clasifican como pirimidinas o purinas. Las pirimidinas son aminas heterocíclicas con dos átomos de nitrógeno en un anillo de seis miembros e incluyen uracilo, timina y citosina. Las purinas son aminas heterocíclicas consistentes en un anillo de pirimidina fusionado a un anillo de cinco miembros con dos átomos de nitrógeno. La adenina y la guanina son las principales purinas que se encuentran en los ácidos nucleicos (Figura\(\PageIndex{1}\)).
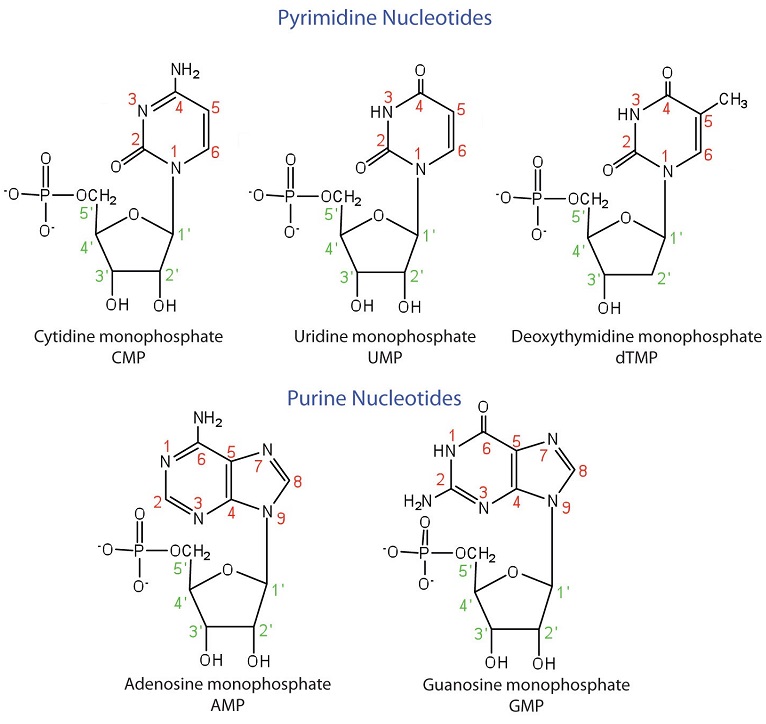
La formación de un enlace entre C1′ del azúcar pentosa y N1 de la base pirimidina o N9 de la base purina une el azúcar pentosa a la base nitrogenada. En la formación de este enlace, se elimina una molécula de agua. La tabla\(\PageIndex{1}\) resume las similitudes y diferencias en la composición de nucleótidos en ADN y ARN.
La convención de numeración es que los números cebados designan los átomos del anillo de pentosa, y los números no cebados designan los átomos del anillo de purina o pirimidina.
| Composición | ADN | RNA |
|---|---|---|
| bases de purina | adenina y guanina | adenina y guanina |
| bases de pirimidina | citosina y timina | citosina y uracilo |
| azúcar pentosa | 2-desoxirribosa | ribosa |
| ácido inorgánico | ácido fosfórico (H 3 PO 4) | H 3 PO 4 |
Los nombres y estructuras de los ribonucleótidos principales y uno de los desoxirribonucleótidos se dan en la Figura\(\PageIndex{2}\).
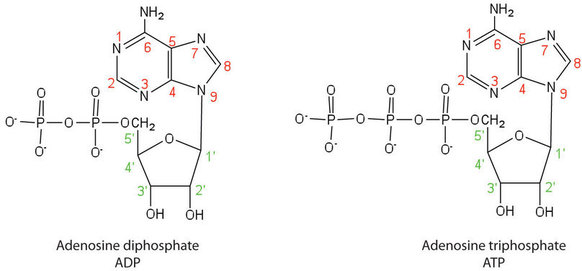
Además de ser las unidades monómeras de ADN y ARN, los nucleótidos y algunos de sus derivados también tienen otras funciones. El difosfato de adenosina (ADP) y el trifosfato de adenosina (ATP), mostrados en la Figura\(\PageIndex{3}\), tienen un papel en el metabolismo celular. Además, varias coenzimas, incluyendo flavina adenina dinucleótido (FAD), nicotinamida adenina dinucleótido (NAD +) y coenzima A, contienen nucleótidos adenina como componentes estructurales.
Los ácidos nucleicos son polímeros grandes formados por la unión de nucleótidos entre sí y se encuentran en todas las células. El ácido desoxirribonucleico (ADN) es el ácido nucleico que almacena información genética. Si todo el ADN de una célula típica de mamífero se extendiera de extremo a extremo, se extendería más de 2 m. El ácido ribonucleico (ARN) es el ácido nucleico responsable de utilizar la información genética codificada en el ADN para producir las miles de proteínas que se encuentran en los organismos vivos.
Estructura primaria de los ácidos nucleicos
Los nucleótidos se unen entre sí a través del grupo fosfato de un nucleótido que conecta en un enlace éster con el grupo OH en el tercer átomo de carbono de la unidad de azúcar de un segundo nucleótido. Esta unidad se une a un tercer nucleótido, y el proceso se repite para producir una cadena larga de ácido nucleico (Figura\(\PageIndex{4}\)). El esqueleto de la cadena consiste en alternar unidades de fosfato y azúcar (2-desoxirribosa en ADN y ribosa en ARN). Las bases de purina y pirimidina se ramifican de este esqueleto.
Cada grupo fosfato tiene un átomo de hidrógeno ácido que se ioniza a pH fisiológico. Es por ello que a estos compuestos se les conoce como ácidos nucleicos.
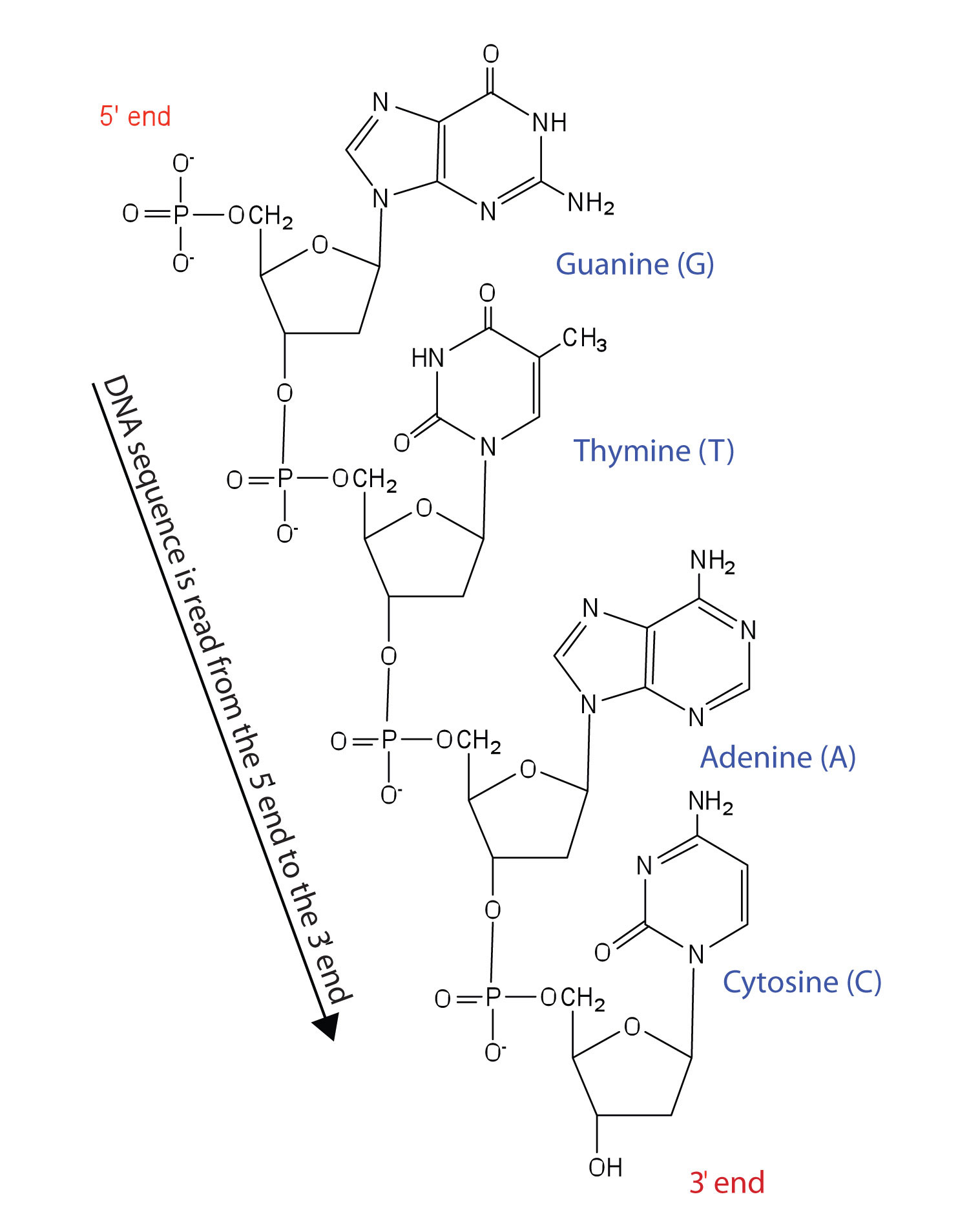
Al igual que las proteínas, los ácidos nucleicos tienen una estructura primaria que se define como la secuencia de sus nucleótidos. A diferencia de las proteínas, que tienen 20 tipos diferentes de aminoácidos, solo hay 4 tipos diferentes de nucleótidos en los ácidos nucleicos. Para las secuencias de aminoácidos en proteínas, la convención es escribir los aminoácidos en orden comenzando con el aminoácido N-terminal. Al escribir secuencias de nucleótidos para ácidos nucleicos, la convención es escribir los nucleótidos (generalmente usando las abreviaturas de una letra para las bases, que se muestran en la Figura\(\PageIndex{4}\)) comenzando con el nucleótido que tiene un grupo fosfato libre, que se conoce como el extremo 5', e indicar los nucleótidos en orden. Para el ADN, a menudo se escribe una d minúscula frente a la secuencia para indicar que los monómeros son desoxirribonucleótidos. El nucleótido final tiene un grupo OH libre en el átomo de carbono 3' y se denomina extremo 3'. La secuencia de nucleótidos en el segmento de ADN que se muestra en la Figura\(\PageIndex{4}\) estaría escrita 5′-DG-DT-DA-DC-3', que a menudo se abrevia además como DGTAC o solo GTAC.
Estructura secundaria del ADN
La estructura tridimensional del ADN fue objeto de un intenso esfuerzo de investigación a finales de la década de 1940 a principios de la década de 1950. El trabajo inicial reveló que el polímero tenía una estructura repetitiva regular. En 1950, Erwin Chargaff de la Universidad de Columbia demostró que la cantidad molar de adenina (A) en el ADN siempre fue igual a la de la timina (T). De igual manera, demostró que la cantidad molar de guanina (G) era la misma que la de citosina (C). Chargaff no sacó conclusiones de su trabajo, pero otros pronto lo hicieron.
En la Universidad de Cambridge en 1953, James D. Watson y Francis Crick anunciaron que tenían un modelo para la estructura secundaria del ADN. Usando la información de los experimentos de Chargaff (así como otros experimentos) y los datos de los estudios de rayos X de Rosalind Franklin (que involucraron química sofisticada, física y matemáticas), Watson y Crick trabajaron con modelos que no eran diferentes al conjunto de construcción de un niño y finalmente concluyeron que El ADN está compuesto por dos cadenas de ácido nucleico que corren antiparalelas entre sí, es decir, lado a lado con el extremo 5' de una cadena junto al extremo 3' de la otra. Además, como mostró su modelo, las dos cadenas están retorcidas para formar una doble hélice, una estructura que puede compararse con una escalera de caracol, con los grupos fosfato y azúcar (la columna vertebral del polímero de ácido nucleico) representando los bordes exteriores de la escalera. Las bases de purina y pirimidina se enfrentan al interior de la hélice, con guanina siempre opuesta a citosina y adenina siempre opuesta a timina. Estos pares de bases específicos, denominados bases complementarias, son los escalones, o peldaños, en nuestra analogía de escalera (Figura\(\PageIndex{5}\)).
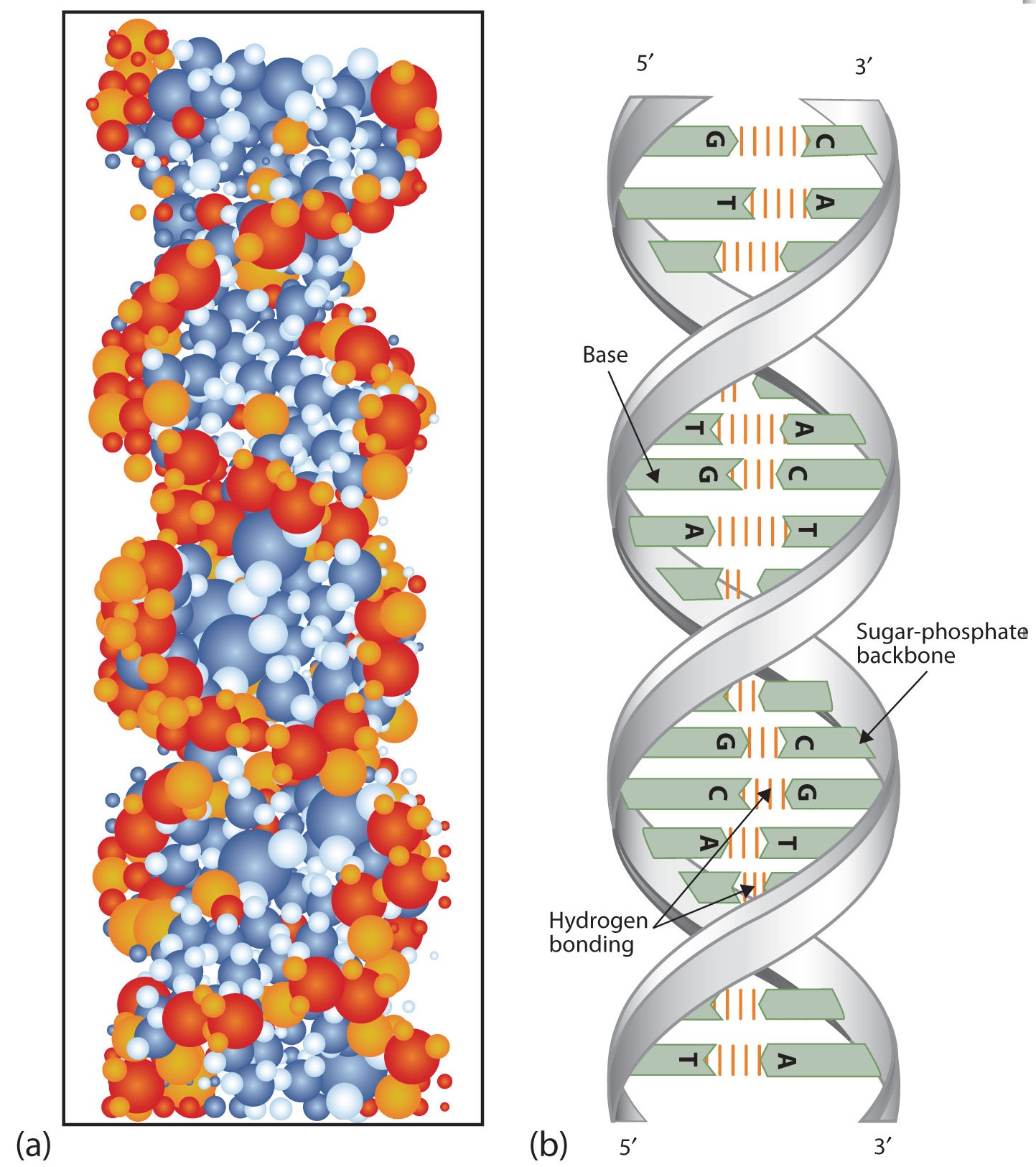
La estructura propuesta por Watson y Crick proporcionó pistas sobre los mecanismos por los cuales las células son capaces de dividirse en dos células hijas idénticas que funcionan; cómo se pasan los datos genéticos a las nuevas generaciones; e incluso cómo se construyen las proteínas según las especificaciones requeridas. Todas estas habilidades dependen del emparejamiento de bases complementarias. La figura\(\PageIndex{6}\) muestra los dos conjuntos de pares de bases e ilustra dos cosas. Primero, una pirimidina se empareja con una purina en cada caso, de manera que las dimensiones largas de ambos pares son idénticas (1.08 nm).
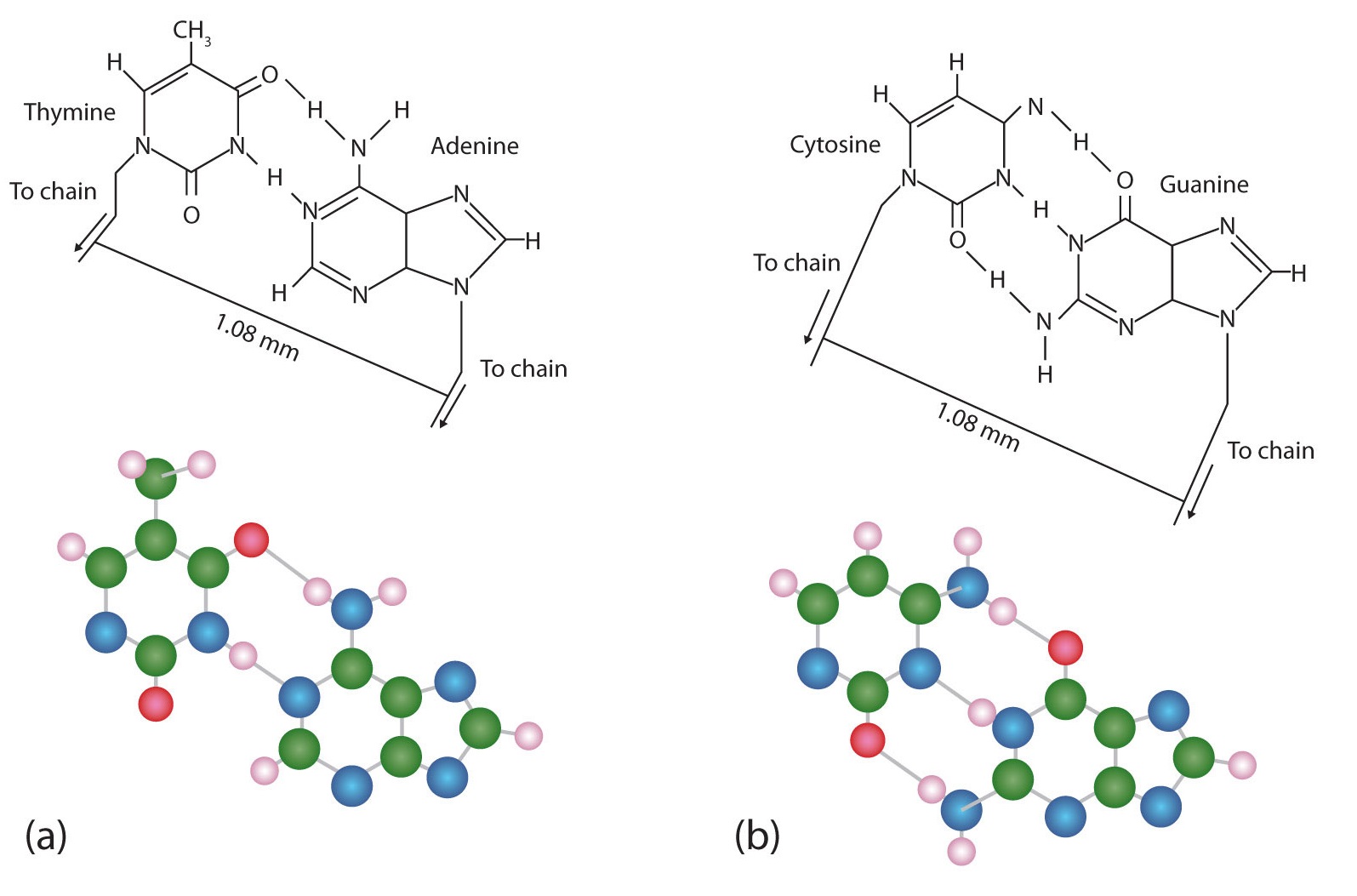
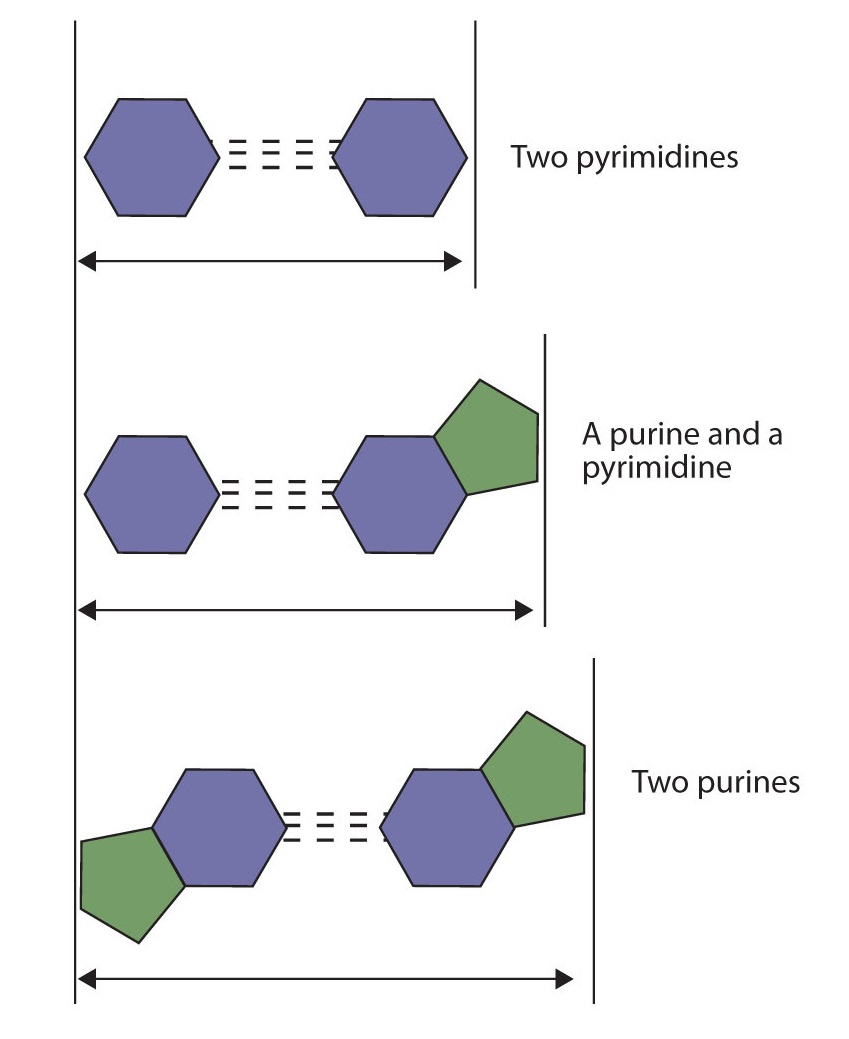
Si se aparearan dos pirimidinas o se aparearan dos purinas, las dos pirimidinas ocuparían menos espacio que una purina y una pirimidina, y las dos purinas ocuparían más espacio, como se ilustra en la Figura\(\PageIndex{7}\). Si alguna vez ocurrieran estos emparejamientos, la estructura del ADN sería como una escalera hecha con escaleras de diferentes anchuras. Para que las dos hebras de la doble hélice encajen perfectamente, una pirimidina siempre debe emparejarse con una purina. Lo segundo que debes notar en Figura\(\PageIndex{6}\) es que el emparejamiento correcto permite la formación de tres instancias de enlaces de hidrógeno entre guanina y citosina y dos entre adenina y timina. La contribución aditiva de este enlace de hidrógeno imparte una gran estabilidad a la doble hélice del ADN.
Anteriormente afirmamos que el ácido desoxirribonucleico (ADN) almacena información genética, mientras que el ácido ribonucleico (ARN) se encarga de transmitir o expresar información genética al dirigir la síntesis de miles de proteínas que se encuentran en los organismos vivos. Pero, ¿cómo realizan estas funciones los ácidos nucleicos? Se requieren tres procesos: (1) replicación, en la que se realizan nuevas copias de ADN; (2) transcripción, en la que se utiliza un segmento de ADN para producir ARN; y (3) traducción, en la que la información en ARN se traduce en una secuencia proteica.
ADN: Auto-replicación
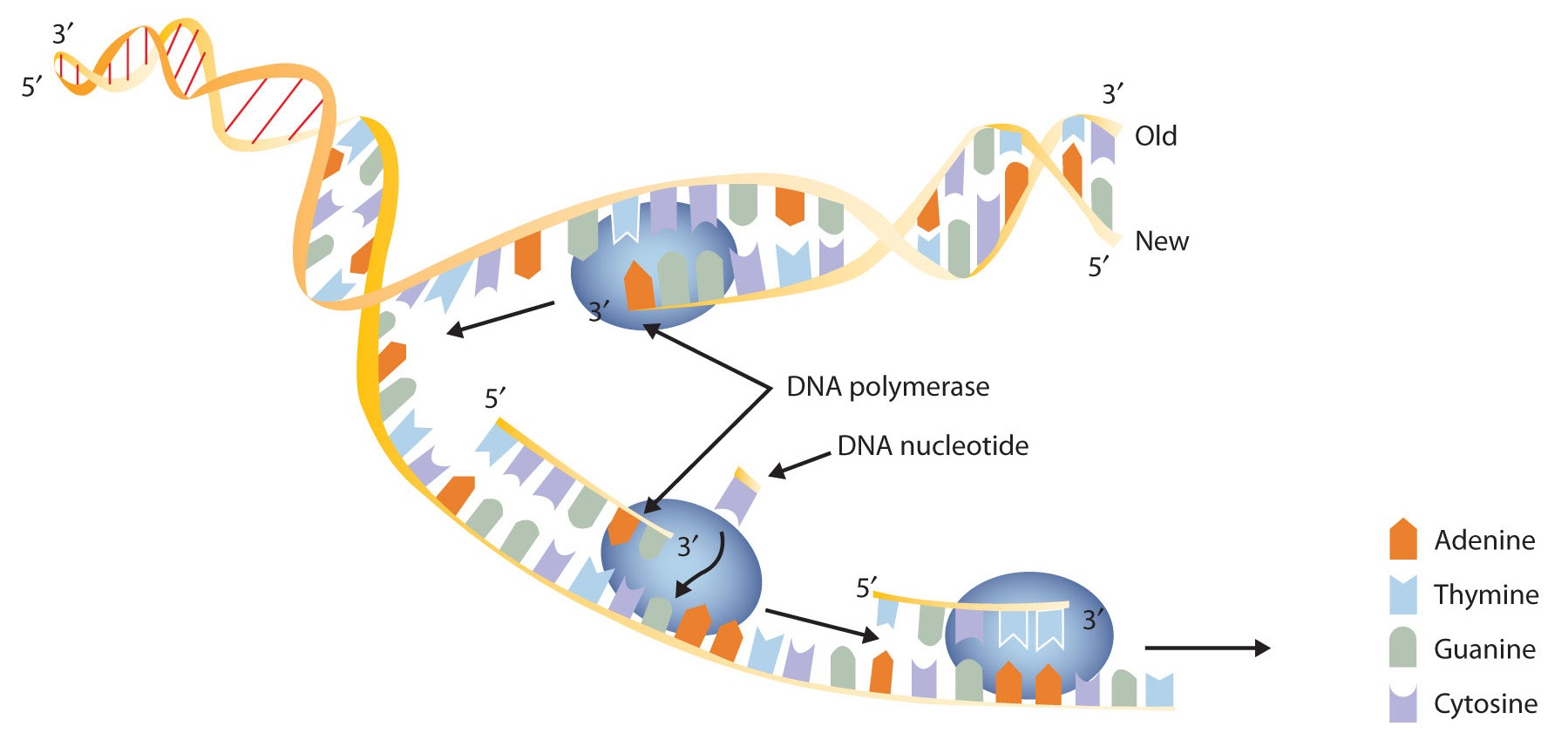
Nuevas células se forman continuamente en el cuerpo a través del proceso de división celular. Para que esto suceda, el ADN en una célula en división debe copiarse en un proceso conocido como replicación. El apareamiento de bases complementarias de la doble hélice proporciona un modelo listo de cómo se produce la replicación genética. Si las dos cadenas de la doble hélice se separan, alterando el enlace de hidrógeno entre pares de bases, cada cadena puede actuar como molde, o patrón, para la síntesis de una nueva cadena de ADN complementaria.
El núcleo contiene todas las enzimas, proteínas y nucleótidos necesarios para esta síntesis. Un segmento corto de ADN se “descomprima”, de manera que las dos cadenas en el segmento se separan para servir como plantillas para el nuevo ADN. La ADN polimerasa, una enzima, reconoce cada base en una cadena molde y la empareja con la base complementaria en un nucleótido libre. La enzima cataliza entonces la formación de un enlace éster entre el grupo fosfato 5' del nucleótido y el extremo 3′ OH de la nueva cadena de ADN en crecimiento. De esta manera, cada hebra de la molécula de ADN original se utiliza para producir un duplicado de su pareja anterior (Figura\(\PageIndex{8}\)). Cualquier información que se codificara en la doble hélice de ADN original ahora está contenida en cada hélice replicada. Cuando la celda se divide, cada celda hija obtiene una de estas réplicas y, por lo tanto, toda la información que originalmente poseía la celda padre.
Un segmento de una hebra de una molécula de ADN tiene la secuencia 5′‑TCCATGAGTTGA-3′. ¿Cuál es la secuencia de nucleótidos en la cadena de ADN opuesta o complementaria?
Solución
Sabiendo que las dos cadenas son antiparalelas y que T pares de bases con A, mientras que C pares de bases con G, la secuencia de la hebra complementaria será 3′‑AGGTATCAACT‑5′.
Un segmento de una cadena de una molécula de ADN tiene la secuencia 5′‑CCAGTGAATTGCCTAT‑3′. ¿Cuál es la secuencia de nucleótidos en la cadena de ADN opuesta o complementaria?
Contestar
3′‑GGTCACTTAACGGATA‑5′.
Resumen
- Los nucleótidos están compuestos por ácido fosfórico, un azúcar pentosa (ribosa o desoxirribosa) y una base que contiene nitrógeno (adenina, citosina, guanina, timina o uracilo). Los ribonucleótidos contienen ribosa, mientras que los desoxirribonucleótidos contienen desoxirribosa.
- El ADN es el ácido nucleico que almacena información genética. El ARN es el ácido nucleico responsable de usar la información genética en el ADN para producir proteínas.
- Las secuencias de ácido nucleico se escriben comenzando con el nucleótido que tiene un grupo fosfato libre (el extremo 5').
- Dos hebras de ADN se unen en una dirección antiparalela y se tuercen para formar una doble hélice. Las bases nitrogenadas se enfrentan al interior de la hélice. La guanina es siempre opuesta a la citosina, y la adenina es siempre opuesta a la timina.
- En la replicación del ADN, cada hebra del ADN original sirve como molde para la síntesis de una cadena complementaria.
- La ADN polimerasa es la enzima primaria necesaria para la replicación.
Colaboradores y Atribuciones
- Libretexto: Fundamentos de la Química GOB (Ball et al.)