
4: Datos y bases de datos
- Page ID
- 153188

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
Al finalizar con éxito este capítulo, usted será capaz de:
- describir las diferencias entre los datos, la información y el conocimiento;
- definir el término base de datos e identificar los pasos para crear una;
- describir el papel de un sistema de gestión de bases de datos;
- describir las características de un almacén de datos; y
- definir la minería de datos y describir su papel en una organización.
Introducción
Ya te han presentado los dos primeros componentes de los sistemas de información: hardware y software. Sin embargo, esos dos componentes por sí mismos no hacen que una computadora sea útil. Imagínese si encendiera una computadora, iniciara el procesador de textos, pero no pudiera guardar un documento. Imagínese si abriera un reproductor de música pero no hubiera música para tocar. Imagina abrir un navegador web pero no había páginas web. Sin datos, ¡el hardware y el software no son muy útiles! Los datos son el tercer componente de un sistema de información.
Datos, Información y Conocimiento
Los datos son los bits brutos y piezas de información sin contexto. Si te dijera, “15, 23, 14, 85”, no habrías aprendido nada. Pero yo te hubiera dado datos.
Los datos pueden ser cuantitativos o cualitativos. Los datos cuantitativos son numéricos, el resultado de una medición, conteo o algún otro cálculo matemático. Los datos cualitativos son descriptivos. “Rojo Rubí”, el color de un Ford Focus 2013, es un ejemplo n de datos cualitativos. Un número también puede ser cualitativo: si te digo mi número favorito es 5, ese es dato cualitativo porque es descriptivo, no el resultado de una medición o cálculo matemático.
 Por sí mismos, los datos no son tan útiles. Para ser útil, es necesario darle contexto. Volviendo al ejemplo anterior, si te dijera que “15, 23, 14, y 85″ son los números de alumnos que se habían inscrito para las próximas clases, eso sería información. Al agregar el contexto —que los números representan el recuento de alumnos que se inscriben en clases específicas—, he convertido los datos en información.
Por sí mismos, los datos no son tan útiles. Para ser útil, es necesario darle contexto. Volviendo al ejemplo anterior, si te dijera que “15, 23, 14, y 85″ son los números de alumnos que se habían inscrito para las próximas clases, eso sería información. Al agregar el contexto —que los números representan el recuento de alumnos que se inscriben en clases específicas—, he convertido los datos en información.
Una vez que hemos puesto nuestros datos en contexto, los hemos agregado y analizado, podemos utilizarlos para tomar decisiones para nuestra organización. Podemos decir que este consumo de información produce conocimiento. Este conocimiento puede ser utilizado para tomar decisiones, establecer políticas e incluso impulsar la innovación.
El paso final en la escalera de la información es el paso del conocimiento (saber mucho sobre un tema) a la sabiduría. Podemos decir que alguien tiene sabiduría cuando puede combinar sus conocimientos y experiencia para producir una comprensión más profunda de un tema. A menudo lleva muchos años desarrollar sabiduría sobre un tema en particular, y requiere paciencia.
Ejemplos de datos
Casi todos los programas de software requieren datos para hacer algo útil. Por ejemplo, si está editando un documento en un procesador de textos como Microsoft Word, el documento en el que está trabajando son los datos. El software de procesamiento de textos puede manipular los datos: crear un nuevo documento, duplicar un documento o modificar un documento. Algunos otros ejemplos de datos son: un archivo de música MP3, un archivo de video, una hoja de cálculo, una página web y un libro electrónico. En algunos casos, como con un libro electrónico, es posible que solo tengas la capacidad de leer los datos.
Bases de datos
El objetivo de muchos sistemas de información es transformar los datos en información con el fin de generar conocimiento que pueda ser utilizado para la toma de decisiones. Para ello, el sistema debe ser capaz de tomar datos, ponerlos en contexto y proporcionar herramientas de agregación y análisis. Una base de datos está diseñada para tal propósito.
Una base de datos es una colección organizada de información relacionada. Se trata de una colección organizada, pues en una base de datos, todos los datos son descritos y asociados con otros datos. Toda la información de una base de datos también debe estar relacionada; se deben crear bases de datos separadas para administrar la información no relacionada. Por ejemplo, una base de datos que contenga información sobre los estudiantes no debe contener también información sobre los precios de las acciones de la empresa. Las bases de datos no siempre son digitales; un archivador, por ejemplo, podría considerarse una forma de base de datos. Para los efectos de este texto, sólo consideraremos bases de datos digitales.
Bases de datos relacionales
Las bases de datos se pueden organizar de muchas maneras diferentes y, por lo tanto, tomar muchas formas. La forma de base de datos más popular hoy en día es la base de datos relacional. Ejemplos populares de bases de datos relacionales son Microsoft Access, MySQL y Oracle. Una base de datos relacional es aquella en la que los datos se organizan en una o más tablas. Cada tabla tiene un conjunto de campos, que definen la naturaleza de los datos almacenados en la tabla. Un registro es una instancia de un conjunto de campos en una tabla. Para visualizar esto, piense en los registros como las filas de la tabla y los campos como las columnas de la tabla. En el siguiente ejemplo, tenemos una tabla de información del estudiante, con cada fila representando a un estudiante y cada columna representando una pieza de información sobre el estudiante.

Filas y columnas en una tabla
En una base de datos relacional, todas las tablas están relacionadas por uno o más campos, de manera que es posible conectar todas las tablas de la base de datos a través del campo o campos que tienen en común. Para cada tabla, uno de los campos se identifica como clave primaria. Esta clave es el identificador único para cada registro de la tabla. Para ayudarle a comprender más estos términos, recorramos el proceso de diseño de una base de datos.
Diseñar una base de datos
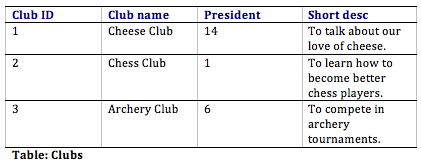
Supongamos que una universidad quiere crear un sistema de información para rastrear la participación en clubes estudiantiles. Después de entrevistar a varias personas, el equipo de diseño se entera de que el objetivo de implementar el sistema es dar una mejor idea de cómo la universidad financia los clubes. Esto se logrará rastreando cuántos miembros tiene cada club y qué tan activos son los clubes. A partir de esto, el equipo decide que el sistema debe realizar un seguimiento de los clubes, sus integrantes y sus eventos. Con esta información, el equipo de diseño determina que se deben crear las siguientes tablas:
- Clubes: esto rastreará el nombre del club, el presidente del club y una breve descripción del club.
- Alumnos: nombre del alumno, correo electrónico y año de nacimiento.
- Membresías: esta tabla correlacionará a los estudiantes con los clubes, lo que nos permitirá que cualquier estudiante se una a múltiples clubes.
- Eventos: esta tabla hará un seguimiento de cuándo se reúnen los clubes y cuántos alumnos se presentaron.
Ahora que el equipo de diseño ha determinado qué tablas crear, necesitan definir la información específica que contendrá cada tabla. Esto requiere identificar los campos que estarán en cada tabla. Por ejemplo, Nombre del Club sería uno de los campos en la tabla de Clubes. Nombre y Apellido serían los campos en la tabla Estudiantes. Por último, dado que esta será una base de datos relacional, cada tabla debe tener un campo en común con al menos otra tabla (en otras palabras: deben tener una relación entre sí).
Para crear adecuadamente esta relación, se debe seleccionar una clave primaria para cada tabla. Esta clave es un identificador único para cada registro de la tabla. Por ejemplo, en la tabla Estudiantes, podría ser posible usar el apellido de los estudiantes como una forma de identificarlos de manera única. No obstante, es más que probable que algunos alumnos compartan apellido (como Rodríguez, Smith o Lee), por lo que se debe seleccionar un campo diferente. La dirección de correo electrónico de un estudiante puede ser una buena opción para una clave primaria, ya que las direcciones de correo electrónico son únicas. Sin embargo, una clave primaria no puede cambiar, por lo que esto significaría que si los estudiantes cambiaban su dirección de correo electrónico tendríamos que eliminarlos de la base de datos y luego volver a insertarlos, no una propuesta atractiva. Nuestra solución es crear un valor para cada estudiante —un ID de usuario— que actuará como clave primaria. También haremos esto para cada uno de los clubes estudiantiles. ¡Esta solución es bastante común y es la razón por la que tienes tantos ID de usuario!
Puede ver el diseño final de la base de datos en la siguiente figura:

Diagrama de la base de datos
Con este diseño, no solo tenemos una forma de organizar toda la información que necesitamos para cumplir con los requisitos, sino que también hemos relacionado con éxito todas las tablas juntas. Así es como podrían verse las tablas de la base de datos con algunos datos de muestra. Tenga en cuenta que la tabla Membresías tiene el único propósito de permitirnos relacionar a varios estudiantes con múltiples clubes.



Normalización
Al diseñar una base de datos, un concepto importante a entender es la normalización. En términos simples, normalizar una base de datos significa diseñarla de manera que: 1) reduzca la duplicación de datos entre tablas y 2) le dé a la tabla la mayor flexibilidad posible.
En el diseño de la base de datos Clubes Estudiantiles, el equipo de diseño trabajó para lograr estos objetivos. Por ejemplo, para rastrear las membresías, una solución simple podría haber sido crear un campo Miembros en la tabla Clubes y luego simplemente enumerar los nombres de todos los miembros allí. No obstante, este diseño significaría que si un estudiante se uniera a dos clubes, entonces su información tendría que ser ingresada por segunda vez. En cambio, los diseñadores resolvieron este problema utilizando dos tablas: Estudiantes y Membresías.
En este diseño, cuando un estudiante se une a su primer club, primero debemos agregar al alumno a la tabla Estudiantes, donde se ingresa su nombre, apellido, dirección de correo electrónico y año de nacimiento. Esta adición a la tabla Estudiantes generará una identificación de estudiante. Ahora agregaremos una nueva entrada para denotar que el alumno es miembro de un club específico. Esto se logra agregando un registro con el ID de estudiante y el ID del club en la tabla Membresías. Si este estudiante se une a un segundo club, no tenemos que duplicar la entrada del nombre del estudiante, correo electrónico y año de nacimiento; en cambio, solo necesitamos hacer otra entrada en la tabla de Membresías de la identificación del segundo club y la identificación del estudiante.
El diseño de la base de datos de Clubes Estudiantiles también facilita cambiar el diseño sin mayores modificaciones en la estructura existente. Por ejemplo, si se le pidiera al equipo de diseño que agregara funcionalidad al sistema para rastrear a los asesores de profesores a los clubes, podríamos lograrlo fácilmente agregando una tabla de Asesores de Facultad (similar a la tabla Estudiantes) y luego agregando un nuevo campo a la tabla Clubs para contener la ID de Asesor de Facultad.
Tipos de datos
Al definir los campos en una tabla de base de datos, debemos darle a cada campo un tipo de datos. Por ejemplo, el campo Año de Nacimiento es un año, por lo que será un número, mientras que Nombre será texto. La mayoría de las bases de datos modernas permiten almacenar varios tipos de datos diferentes. Algunos de los tipos de datos más comunes se enumeran aquí:
- Texto: para almacenar datos no numéricos que sean breves, generalmente bajo 256 caracteres. El diseñador de la base de datos puede identificar la longitud máxima del texto.
- Número: para almacenar números. Por lo general, hay algunos tipos de números diferentes que se pueden seleccionar, dependiendo de qué tan grande sea el número más grande.
- Sí/No: una forma especial del tipo de datos numéricos que es (generalmente) de un byte de longitud, con un 0 para “No” o “Falso” y un 1 para “Sí” o “Verdadero”.
- Fecha/Hora: una forma especial del tipo de datos numéricos que puede interpretarse como un número o una hora.
- Moneda: una forma especial del tipo de datos numéricos que formatea todos los valores con un indicador de moneda y dos decimales.
- Texto de párrafo: este tipo de datos permite textos de más de 256 caracteres.
- Objeto: este tipo de datos permite el almacenamiento de datos que no se pueden ingresar a través del teclado, como una imagen o un archivo de música.
Hay dos razones importantes por las que debemos definir adecuadamente el tipo de datos de un campo. Primero, un tipo de datos le dice a la base de datos qué funciones se pueden realizar con los datos. Por ejemplo, si deseamos realizar funciones matemáticas con uno de los campos, debemos asegurarnos de decirle a la base de datos que el campo es un tipo de datos numéricos. Entonces, si tenemos, digamos, un campo que almacena el año de nacimiento, podemos restar el número almacenado en ese campo del año en curso para obtener la edad.
La segunda razón importante para definir el tipo de datos es para que se asigne la cantidad adecuada de espacio de almacenamiento para nuestros datos. Por ejemplo, si el campo Nombre se define como un tipo de datos de texto (50), esto significa que se asignan cincuenta caracteres por cada nombre que queremos almacenar. No obstante, aunque el nombre de pila tenga sólo cinco caracteres, se asignarán cincuenta caracteres (bytes). Si bien esto puede no parecer un gran problema, si nuestra tabla termina conteniendo 50,000 nombres, estamos asignando 50 * 50,000 = 2,500,000 bytes para el almacenamiento de estos valores. Puede ser prudente reducir el tamaño del campo para que no desperdiciemos espacio de almacenamiento.
Barra lateral: La diferencia entre una base de datos y una hoja de cálculo
Muchas veces, al introducir el concepto de bases de datos a los estudiantes, rápidamente deciden que una base de datos es más o menos lo mismo que una hoja de cálculo. Después de todo, una hoja de cálculo almacena datos de manera organizada, usando filas y columnas, y se ve muy similar a una tabla de base de datos. Este malentendido se extiende más allá del aula: las hojas de cálculo se utilizan como sustituto de bases de datos en todo tipo de situaciones todos los días, en todo el mundo.
Para ser justos, para usos simples, una hoja de cálculo puede sustituir bastante bien a una base de datos. Si un simple listado de filas y columnas (una sola tabla) es todo lo que se necesita, entonces crear una base de datos probablemente sea exagerado. En nuestro ejemplo de Clubes Estudiantiles, si solo necesitábamos rastrear una lista de clubes, el número de miembros y la información de contacto del presidente, podríamos salirnos con la suya con una sola hoja de cálculo. Sin embargo, la necesidad de incluir una lista de eventos y los nombres de los miembros sería problemática si se rastreara con una hoja de cálculo.
Cuando se deben mezclar varios tipos de datos, o cuando las relaciones entre estos tipos de datos son complejas, entonces una hoja de cálculo no es la mejor solución. Una base de datos permite que los datos de varias entidades (como estudiantes, clubes, membresías y eventos) se relacionen en un todo. Si bien una hoja de cálculo sí permite definir qué tipos de valores se pueden introducir en sus celdas, una base de datos proporciona formas más intuitivas y potentes de definir los tipos de datos que entran en cada campo, reduciendo posibles errores y permitiendo un análisis más fácil.
Aunque no son buenas para reemplazar bases de datos, las hojas de cálculo pueden ser herramientas ideales para analizar los datos almacenados en una base de datos. Un paquete de hoja de cálculo se puede conectar a una tabla o consulta específica en una base de datos y usarse para crear gráficos o realizar análisis sobre esos datos.
Lenguaje de consultas estructuradas
Una vez que tengas una base de datos diseñada y cargada con datos, ¿cómo harás algo útil con ella? La forma principal de trabajar con una base de datos relacional es usar Lenguaje de Consulta Estructurado, SQL (pronunciado “secuela” o simplemente declarado como S-Q-L). Casi todas las aplicaciones que trabajan con bases de datos (como los sistemas de gestión de bases de datos, que se analizan a continuación) hacen uso de SQL como una forma de analizar y manipular datos relacionales. Como su nombre lo indica, SQL es un lenguaje que se puede utilizar para trabajar con una base de datos relacional. Desde una simple solicitud de datos hasta una compleja operación de actualización, SQL es un pilar de programadores y administradores de bases de datos. Para darle una idea de cómo podría ser SQL, aquí hay un par de ejemplos usando nuestra base de datos de Clubes Estudiantiles.
- La siguiente consulta recuperará una lista de los nombres y apellidos de los presidentes del club:
SELECT "First Name", "Last Name" FROM "Students" WHERE "Students.ID" = "Clubs.President"
- La siguiente consulta creará una lista del número de estudiantes en cada club, enumerando el nombre del club y luego el número de miembros:
SELECT "Clubs.Club Name", COUNT("Memberships.Student ID") FROM "Clubs" LEFT JOIN "Memberships" ON "Clubs.Club ID" = "Memberships.Club ID"
Una descripción en profundidad de cómo funciona SQL está más allá del alcance de este texto introductorio, pero estos ejemplos deberían darle una idea del poder de usar SQL para manipular datos relacionales. Muchos paquetes de bases de datos, como Microsoft Access, le permiten crear visualmente la consulta que desea construir y luego generar la consulta SQL por usted.
Otros tipos de bases de datos
El modelo de base de datos relacional es el modelo de base de datos más utilizado actualmente. Sin embargo, existen muchos otros modelos de bases de datos que proporcionan diferentes fortalezas que el modelo relacional. El modelo de base de datos jerárquica, popular en las décadas de 1960 y 1970, conectó los datos juntos en una jerarquía, permitiendo una relación padre/hijo entre los datos. El modelo centrado en documentos permitió un almacenamiento de datos más desestructurado al colocar datos en “documentos” que luego podrían ser manipulados.
Quizás el nuevo desarrollo más interesante es el concepto de NoSQL (de la frase “no solo SQL”). NoSQL surgió de la necesidad de resolver el problema de bases de datos a gran escala repartidas en varios servidores o incluso en todo el mundo. Para que una base de datos relacional funcione correctamente, es importante que solo una persona pueda manipular un dato a la vez, concepto conocido como bloqueo de registros. Pero con las bases de datos actuales a gran escala (piense en Google y Amazon), esto simplemente no es posible. Una base de datos NoSQL puede trabajar con datos de una manera más flexible, permitiendo un entorno más desestructurado, comunicando cambios en los datos a lo largo del tiempo a todos los servidores que forman parte de la base de datos.
Sistemas de Gestión de Bases de

Screen shot del sistema de gestión de bases de datos Open Office
Para la computadora, una base de datos se parece a uno o más archivos. Para que los datos de la base de datos sean leídos, cambiados, agregados o eliminados, un programa de software debe acceder a ellos. Muchas aplicaciones de software tienen esta capacidad: iTunes puede leer su base de datos para darte una lista de sus canciones (y reproducir las canciones); tu software de teléfono móvil puede interactuar con tu lista de contactos. Pero, ¿qué pasa con las aplicaciones para crear o administrar una base de datos? ¿Qué software puedes usar para crear una base de datos, cambiar la estructura de una base de datos o simplemente hacer análisis? Ese es el propósito de una categoría de aplicaciones de software llamada sistemas de gestión de bases de datos (DBMS).
Los paquetes DBMS generalmente proporcionan una interfaz para ver y cambiar el diseño de la base de datos, crear consultas y desarrollar informes. La mayoría de estos paquetes están diseñados para funcionar con un tipo específico de base de datos, pero generalmente son compatibles con una amplia gama de bases de datos.
Por ejemplo, Apache OpenOffice.org Base (ver captura de pantalla) se puede utilizar para crear, modificar y analizar bases de datos en formato de base de datos abiertos (ODB). Access DBMS de Microsoft se utiliza para trabajar con bases de datos en su propio formato Microsoft Access Database. Tanto Access como Base tienen la capacidad de leer y escribir en otros formatos de base de datos también.
Microsoft Access y Open Office Base son ejemplos de sistemas de administración de bases de datos personales. Estos sistemas se utilizan principalmente para desarrollar y analizar bases de datos de un solo usuario. Estas bases de datos no están destinadas a ser compartidas a través de una red o Internet, sino que se instalan en un dispositivo en particular y funcionan con un solo usuario a la vez.
Bases de Datos Empresariales
Una base de datos que solo puede ser utilizada por un solo usuario a la vez no va a satisfacer las necesidades de la mayoría de las organizaciones. A medida que las computadoras se han conectado en red y ahora se unen en todo el mundo a través de Internet, ha surgido una clase de base de datos a la que pueden acceder dos, diez o incluso un millón de personas. Estas bases de datos a veces se instalan en una sola computadora para ser accedidas por un grupo de personas en una sola ubicación. Otras veces, se instalan sobre varios servidores en todo el mundo, destinados a ser accedidos por millones. Estos paquetes de bases de datos empresariales relacionales son construidos y soportados por compañías como Oracle, Microsoft e IBM. El MySQL de código abierto también es una base de datos empresarial.
Como se indicó anteriormente, el modelo de base de datos relacional no escala bien. El término escala aquí se refiere a una base de datos cada vez más grande, siendo distribuida en un mayor número de computadoras conectadas a través de una red. Algunas empresas buscan proporcionar soluciones de bases de datos a gran escala al alejarse del modelo relacional a otros modelos más flexibles. Por ejemplo, Google ahora ofrece el almacén de datos de App Engine, que se basa en NoSQL. Los desarrolladores pueden usar el almacén de datos de App Engine para desarrollar aplicaciones que accedan a los datos desde cualquier parte del mundo. Amazon.com ofrece varios servicios de bases de datos para uso empresarial, incluyendo Amazon RDS, que es un servicio de base de datos relacional, y Amazon DynamoDB, una solución empresarial NoSQL.
Big Data
Una nueva palabra de moda que últimamente ha estado captando la atención de las empresas es el big data. El término se refiere a conjuntos de datos tan masivamente grandes que las herramientas de bases de datos convencionales no tienen el poder de procesamiento para analizarlos. Por ejemplo, Walmart debe procesar más de un millón de transacciones de clientes cada hora. Almacenar y analizar esa cantidad de datos está más allá del poder de las herramientas tradicionales de administración de bases de datos. Comprender las mejores herramientas y técnicas para administrar y analizar estos grandes conjuntos de datos es un problema que tanto los gobiernos como las empresas están tratando de resolver.
Barra lateral: ¿Qué son los metadatos?
El término metadatos puede entenderse como “datos sobre datos”. Por ejemplo, al mirar uno de los valores de Año de Nacimiento en la tabla Estudiantes, los datos en sí pueden ser “1992″. Los metadatos sobre ese valor serían el nombre de campo Año de Nacimiento, la hora en que se actualizó por última vez y el tipo de datos (entero). Otro ejemplo de metadatos podría ser para un archivo de música MP3, como el que se muestra en la imagen de abajo; información como la duración de la canción, el artista, el álbum, el tamaño del archivo, e incluso la portada del álbum, se clasifican como metadatos. Cuando se está diseñando una base de datos, se crea un “diccionario de datos” para contener los metadatos, definiendo los campos y la estructura de la base de datos.
Data Warehouse
A medida que las organizaciones han comenzado a utilizar las bases de datos como pieza central de sus operaciones, la necesidad de comprender y aprovechar completamente los datos que están recopilando se ha vuelto cada vez más evidente. Sin embargo, analizar directamente los datos que se necesitan para las operaciones del día a día no es una buena idea; no queremos gravar las operaciones de la empresa más de lo que necesitamos. Además, las organizaciones también quieren analizar datos en un sentido histórico: ¿Cómo se comparan los datos que tenemos hoy con el mismo conjunto de datos esta vez el mes pasado, o el año pasado? De estas necesidades surgió el concepto de almacén de datos.
El concepto de almacén de datos es simple: extraer datos de una o más de las bases de datos de la organización y cargarlos en el almacén de datos (que en sí es otra base de datos) para su almacenamiento y análisis. No obstante, la ejecución de este concepto no es tan sencilla. Un almacén de datos debe diseñarse de manera que cumpla con los siguientes criterios:
- Utiliza datos no operativos. Esto significa que el almacén de datos está utilizando una copia de los datos de las bases de datos activas que la empresa utiliza en sus operaciones diarias, por lo que el almacén de datos debe extraer datos de las bases de datos existentes de forma regular y programada.
- Los datos son variables en el tiempo. Esto significa que cada vez que se cargan datos en el almacén de datos, recibe una marca de tiempo, lo que permite comparaciones entre diferentes períodos de tiempo.
- Los datos están estandarizados. Debido a que los datos en un almacén de datos suelen provenir de varias fuentes diferentes, es posible que los datos no utilicen las mismas definiciones o unidades. Por ejemplo, nuestra tabla Eventos en nuestra base de datos de Clubes Estudiantiles enumera las fechas de los eventos usando el formato mm/dd/aaaa (por ejemplo, 01/10/2013). Una tabla en otra base de datos podría usar el formato yy/mm/dd (por ejemplo, 13/01/10) para las fechas. Para que el almacén de datos coincida con las fechas actualizadas, habría que acordar un formato de fecha estándar y todos los datos cargados en el almacén de datos tendrían que ser convertidos para usar este formato estándar. Este proceso se llama extracción-transformación-carga (ETL).
Hay dos escuelas primarias de pensamiento a la hora de diseñar un data warehouse: bottom-up y top-down. El enfoque de abajo hacia arriba comienza creando pequeños almacenes de datos, llamados data marts, para resolver problemas específicos de negocio. A medida que se crean estos data marts, se pueden combinar en un almacén de datos más grande. El enfoque de arriba hacia abajo sugiere que debemos comenzar por crear un almacén de datos para toda la empresa y luego, a medida que se identifican las necesidades específicas del negocio, crear data marts más pequeños a partir del almacén de datos.

Proceso de almacén de datos (de arriba hacia abajo)
Beneficios de los Almacenes de Datos
Las organizaciones encuentran los almacenes de datos bastante beneficiosos por varias razones:
- El proceso de desarrollo de un almacén de datos obliga a una organización a comprender mejor los datos que está recopilando actualmente y, igualmente importante, qué datos no se están recopilando.
- Un almacén de datos proporciona una vista centralizada de todos los datos que se recopilan en toda la empresa y proporciona un medio para determinar datos que son inconsistentes.
- Una vez que todos los datos son identificados como consistentes, una organización puede generar una versión de la verdad. Esto es importante cuando la empresa quiere reportar estadísticas consistentes sobre sí misma, como ingresos o número de empleados.
- Al tener un almacén de datos, las instantáneas de los datos se pueden tomar a lo largo del tiempo. Esto crea un registro histórico de datos, lo que permite un análisis de tendencias.
- Un almacén de datos proporciona herramientas para combinar datos, que pueden proporcionar nueva información y análisis.
Minería de Datos
La minería de datos es el proceso de análisis de datos para encontrar tendencias, patrones y asociaciones previamente desconocidas para tomar decisiones. Generalmente, la minería de datos se realiza a través de medios automatizados contra conjuntos de datos extremadamente grandes, como un almacén de datos. Algunos ejemplos de minería de datos incluyen:
- Un análisis de las ventas de una gran cadena de abarrotes podría determinar que la leche se compra con mayor frecuencia al día siguiente de que llueve en ciudades con una población menor a 50,000.
- Un banco puede encontrar que los solicitantes de préstamos cuyas cuentas bancarias muestran patrones particulares de depósito y retiro no son buenos riesgos crediticios.
- Un equipo de béisbol puede encontrar que jugadores universitarios de béisbol con estadísticas específicas en bateo, pitcheo y fildeo hacen que los jugadores de Grandes Ligas sean más exitosos.
En algunos casos, se inicia un proyecto de minería de datos con un resultado hipotético en mente. Por ejemplo, una cadena de abarrotes puede que ya tenga alguna idea de que los patrones de compra cambian después de que llueve y quiera obtener una comprensión más profunda de exactamente lo que está sucediendo. En otros casos, no hay presuposiciones y se ejecuta un programa de minería de datos contra grandes conjuntos de datos para encontrar patrones y asociaciones.
Preocupaciones de privacidad
El creciente poder de la minería de datos ha causado preocupaciones para muchos, especialmente en el área de la privacidad. En el mundo digital actual, cada vez es más fácil que nunca tomar datos de fuentes dispares y combinarlos para hacer nuevas formas de análisis. De hecho, en torno a esta tecnología ha surgido toda una industria: los corredores de datos. Estas firmas combinan datos de acceso público con información obtenida del gobierno y otras fuentes para crear vastos almacenes de datos sobre personas y empresas que luego pueden vender. Este tema será tratado con mucho más detalle en el capítulo 12 —el capítulo sobre las preocupaciones éticas de los sistemas de información—.
Inteligencia de negocios y análisis de negocios
Con herramientas como el almacenamiento de datos y la minería de datos a su disposición, las empresas están aprendiendo a usar la información en su beneficio. El término inteligencia de negocios se utiliza para describir el proceso que utilizan las organizaciones para tomar los datos que están recopilando y analizarlos con la esperanza de obtener una ventaja competitiva. Además de usar datos de sus bases de datos internas, las empresas a menudo compran información de corredores de datos para obtener una comprensión general de sus industrias. Análisis de negocios es el término utilizado para describir el uso de datos internos de la empresa para mejorar los procesos y prácticas de negocio.
Gestión del Conocimiento
Terminamos el capítulo con una discusión sobre el concepto de gestión del conocimiento (KM). Todas las empresas acumulan conocimientos a lo largo de su existencia. Parte de este conocimiento está escrito o guardado, pero no de manera organizada. Gran parte de este conocimiento no está escrito; en cambio, se almacena dentro de las cabezas de sus empleados. La gestión del conocimiento es el proceso de formalizar la captura, indexación y almacenamiento del conocimiento de la compañía para beneficiarse de las experiencias y conocimientos que la compañía ha capturado durante su existencia.
Resumen
En este capítulo aprendimos sobre el papel que juegan los datos y las bases de datos en el contexto de los sistemas de información. Los datos se componen de pequeños hechos e información sin contexto. Si le das contexto a los datos, entonces tienes información. El conocimiento se adquiere cuando la información se consume y se utiliza para la toma de decisiones. Una base de datos es una colección organizada de información relacionada. Las bases de datos relacionales son el tipo de base de datos más utilizado, donde los datos se estructuran en tablas y todas las tablas deben estar relacionadas entre sí a través de identificadores únicos. Un sistema de gestión de bases de datos (DBMS) es una aplicación de software que se utiliza para crear y administrar bases de datos, y puede tomar la forma de un DBMS personal, utilizado por una persona, o un DBMS empresarial que puede ser utilizado por múltiples usuarios. Un almacén de datos es una forma especial de base de datos que toma datos de otras bases de datos en una empresa y los organiza para su análisis. La minería de datos es el proceso de búsqueda de patrones y relaciones en grandes conjuntos de datos. Muchas empresas utilizan bases de datos, almacenes de datos y técnicas de minería de datos para producir inteligencia de negocios y obtener una ventaja competitiva.
Preguntas de Estudio
- ¿Cuál es la diferencia entre datos, información y conocimiento?
- Explique con sus propias palabras cómo el componente de datos se relaciona con los componentes de hardware y software de los sistemas de información.
- ¿Cuál es la diferencia entre datos cuantitativos y datos cualitativos? ¿En qué situaciones podrían considerarse datos cualitativos el número 42?
- ¿Cuáles son las características de una base de datos relacional?
- ¿Cuándo tendría sentido usar un DBMS personal?
- ¿Cuál es la diferencia entre una hoja de cálculo y una base de datos? Enumere tres diferencias entre ellos.
- Describir lo que significa el término normalización.
- ¿Por qué es importante definir el tipo de datos de un campo al diseñar una base de datos relacional?
- Nombra una base de datos con la que interactúe frecuentemente. ¿Cuáles serían algunos de los nombres de campo?
- ¿Qué son los metadatos?
- Nombra tres ventajas de usar un almacén de datos.
- ¿Qué es la minería de datos?
Ejercicios
- Revise el diseño de la base de datos de Clubes Estudiantiles anteriormente en este capítulo. Revisando las listas de tipos de datos dadas, qué tipos de datos asignarías a cada uno de los campos en cada una de las tablas. ¿Qué longitudes asignarías a los campos de texto?
- Descarga Apache OpenOffice.org y usa la herramienta de base de datos para abrir el archivo “Student Clubs.odb” disponible aquí. Tómese un tiempo para aprender a modificar la estructura de la base de datos y luego ver si puede agregar los elementos requeridos para apoyar el seguimiento de los asesores de la facultad, como se describe al final de la sección Normalización en el capítulo. Aquí hay un enlace a la documentación de Primeros pasos.
- Usando Microsoft Access, descargue el archivo de base de datos de estadísticas integrales de béisbol del sitio web Seanlahman.com. (Si no tienes Microsoft Access, puedes descargar aquí una versión abreviada del archivo que sea compatible con Apache Open Office). Revisar la estructura de las tablas incluidas en la base de datos. Cree tres experimentos diferentes de minería de datos que le gustaría probar y explique qué campos en qué tablas tendrían que analizarse.
- Haz algunas investigaciones originales y encuentra dos ejemplos de minería de datos. Resume cada ejemplo y luego escribe sobre lo que los dos ejemplos tienen en común.
- Realizar algunas investigaciones independientes sobre el proceso de inteligencia de negocios. Usando al menos dos fuentes académicas o profesionales, escriba un artículo de dos páginas dando ejemplos de cómo se está utilizando la inteligencia de negocios.
- Realizar algunas investigaciones independientes sobre las últimas tecnologías que se utilizan para la gestión del conocimiento. Usando al menos dos fuentes académicas o profesionales, escriba un artículo de dos páginas dando ejemplos de aplicaciones de software o nuevas tecnologías que se utilizan en este campo.