
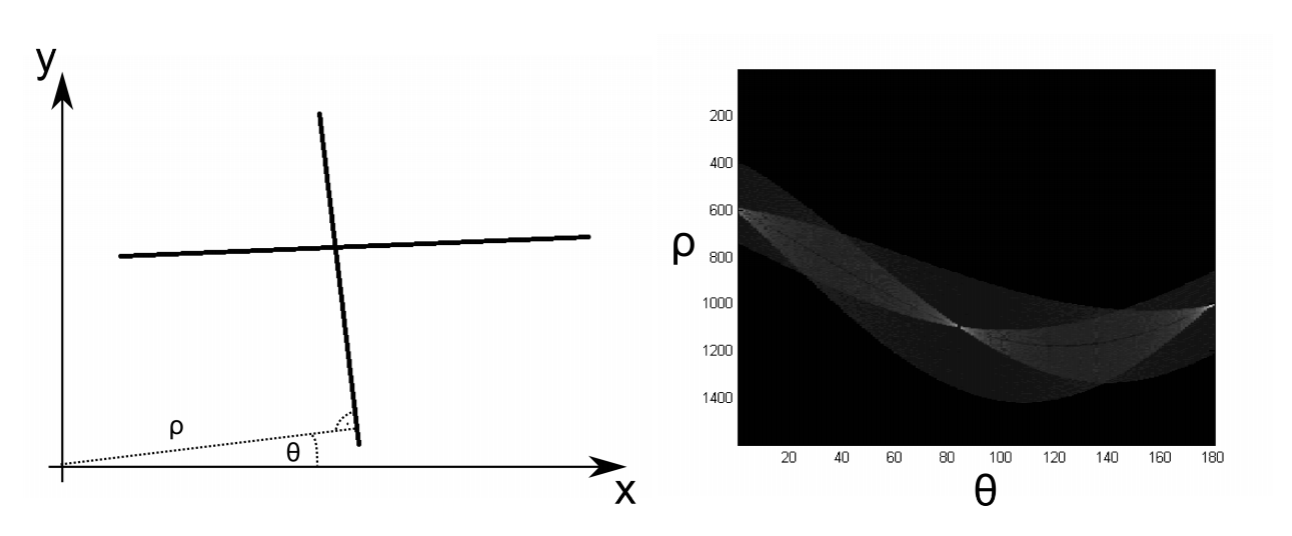
7.4: Transformaciones de entidades invariantes a escala
- Page ID
- 84973

Las transformaciones de características invariantes de escala son una clase de algorítmos/técnicas de procesamiento de señales que permiten extraer características que son fácilmente detectables a través de diferentes escalas (o distancias a un objeto), independientemente de su rotación y, en cierta medida, robustas para afinar transformaciones, es decir, vistas del mismo objeto desde diferentes perspectivas, y cambios de iluminación. Un algoritmo temprano en esta clase es el algoritmo SIFT (Lowe 1999), que sin embargo ha perdido popularidad debido al costo de licencia y de código cerrado, y ha sido reemplazado en el pasado por SURF (Speed-Up Robusto Feature) (?) y ORB (?) , que están disponibles gratuitamente y tienen un rendimiento ligeramente diferente y diferentes casos de uso. A medida que las matemáticas detrás de SURF están más involucradas, nos enfocamos en la intuición detrás de SIFT y alentamos al lector a descargar y jugar con las diversas implementaciones de código abierto de otros detectores de características que están disponibles en código abierto.
7.4.1. Descripción general
El tamizado procede en múltiples pasos. Las descripciones del algoritmo a menudo incluyen su aplicación al reconocimiento de objetos, pero estos algoritmos son independientes de la generación de características (ver más abajo).
- Diferencias de Gaussianos (DOG) a diferentes escalas:
- Genere múltiples versiones escaladas de la misma imagen volviendo a muestrear cada segundo, 4º y así sucesivamente píxel.
- Filtrado de cada imagen escalada con varios filtros gaussianos de diferente varianza.
- Calcular la diferencia entre pares de imágenes filtradas. Esto equivale a un filtro DOG.
- Detectar mínimos y máximos locales en las imágenes DOg a través de diferentes escalas (Figura 7.4.2, izquierda) y rechazar aquellas con bajo contraste (Figura 7.4.2, derecha).

- Rechazar los extremos que están a lo largo de los bordes mirando la segunda derivada alrededor de cada extremo (Figura 7.5, derecha). Los bordes tienen una curvatura principal mucho mayor a través de ellos que a lo largo de ellos.
- Asigne una “magnitud” y una “orientación” a cada extremo restante (punto clave). La magnitud es la diferencia cuadrada entre los píxeles vecinos y la orientación es el ángulo entre la magnitud a lo largo del eje y frente a la magnitud a lo largo del eje x. Estos cálculos se realizan para todos los píxeles en una vecindad fija alrededor del punto clave inicial, por ejemplo, en una vecindad de 16x16 píxeles.
- Recoge orientaciones de píxeles vecinos en un histograma, por ejemplo, 36 bins cada uno cubriendo 10 grados. Mantener la orientación correspondiente al pico más fuerte y asociarlo con el punto clave.
- Repita el 4º paso, pero para cuatro áreas de píxeles 4x4 alrededor del punto clave en la escala de imagen que tiene el mínimo/máximo más extremo. Aquí, solo se utilizan 8 bins para el histograma de orientación. Como hay 16 histogramas en un área de 16x16 píxeles, el descriptor de características tiene 128 dimensiones.
- El vector descriptor de características se normaliza, se traspasa y nuevamente se normaliza para hacerlo más robusto contra los cambios de iluminación.
- La magnitud y orientación del gradiente local se agrupan en bins y crean un descriptor de características de 128 dimensiones.
Los 128 vectores de características dimensionales resultantes son ahora invariables a escala (debido al paso 2), invariantes de rotación (debido al paso 5) y robustos a los cambios de iluminación (debido al paso 7).
7.4.2. Reconocimiento de objetos mediante funciones invariantes de escala
Las características invariantes de escala de las imágenes de entrenamiento se pueden almacenar en una base de datos y pueden usarse para identificar estos objetos en el futuro. Esto se hace encontrando todas las características en una imagen y comparándolas con las de la base de datos. Esta comparación se realiza utilizando la distancia euclidiana como métrica y buscando un árbol kd (con d=128). Para que este enfoque sea robusto, cada objeto necesita ser identificado por al menos 3 características independientes. Para ello, cada descriptor almacena la ubicación, escala y orientación del mismo en relación con algún punto común en el objeto. Esto permite que cada característica detectada “vote” por la posición del objeto con el que está más estrechamente asociado en la base de datos. Esto se hace usando una transformada de Hough. Por ejemplo, la posición (2 dimensiones) y la orientación (1 dimensión) se pueden discretizar en contenedores (30 grados de ancho para la orientación); los puntos brillantes en el espacio Hough corresponden entonces a una pose de objeto que ha sido identificada por múltiples entidades.