
15.3: Encontrar conjuntos de equivalencia
- Page ID
- 115297
La definición formal dice que dos actores son regularmente equivalentes si tienen patrones similares de vínculos a otros equivalentes. Considera a dos hombres. Cada uno tiene hijos (aunque tienen diferentes números de hijos, y, obviamente, tienen hijos diferentes). Cada uno tiene esposa (aunque de nuevo, generalmente diferentes personas ocupan este papel con respecto a cada hombre). Cada esposa, a su vez, también tiene hijos y un esposo (es decir, tienen vínculos con uno o más miembros de cada uno de esos conjuntos). Cada hijo tiene vínculos con uno o más miembros del conjunto de “maridos” y “esposas”.
Al identificar qué actores son “maridos” no nos importan los vínculos entre los miembros de este conjunto (en realidad, esperaríamos que este bloque sea un bloque cero, pero realmente no nos importa). Lo importante es que cada “esposo” tenga al menos un vínculo con una persona en la categoría “esposa” y al menos una persona en la categoría “hijo”. Es decir, los esposos son equivalentes entre sí porque cada uno tiene vínculos similares con algún miembro de los conjuntos de esposas e hijos.
Pero parece que hay un problema con esta definición bastante simple. Si la definición de cada posición depende de sus relaciones con otras posiciones, ¿por dónde empezamos?
Hay una serie de algoritmos que son útiles para identificar conjuntos de equivalencia regular. UCINET proporciona algunos métodos que son particularmente útiles para localizar actores aproximadamente equivalentes regularmente en gráficas valoradas, multi-relacionales y dirigidas. Algunos métodos más simples para datos binarios se pueden ilustrar directamente.
Consideremos, nuevamente, la red de ejemplo Wasserman-Fausto. Imagínese, sin embargo, que esta es una imagen de la entrega de órdenes en una jerarquía simple. Es decir, todos los lazos se dirigen desde la parte superior del diagrama en la Figura 15.1 hacia abajo. Encontraremos una caracterización de equivalencia regular de esta gráfica.
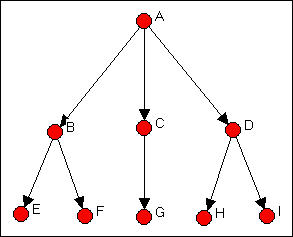
Figura 15.1: Versión de empate dirigido de la red Wasserman-Faust
Para un primer paso, caracterizar cada nodo como una “fuente” (un actor que envía lazos, pero no los recibe), un “repetidor” (un actor que repite y envía), o un “sumidero” (un actor que recibe lazos, pero no los envía). La fuente es A; los repetidores son B, C y D; y los sumideros son E, F, G, H e I. Hay una cuarta posibilidad lógica. Un “aislado” es un nodo que ni envía ni recibe vínculos. Los aislamientos forman un conjunto de equivalencia regular en cualquier red, y deben excluirse del análisis de equivalencia regular de la subgráfica conectada.
Como sólo hay un actor en el conjunto de remitentes, no podemos identificar más complejidad en este “papel”.
Consideremos los tres “repetidores” B, C y D. En el barrio de (es decir, adyacentes a) el actor B se encuentran tanto “fuentes” como “sumideros”. Lo mismo ocurre con los “repetidores” C y D, aunque los tres actores puedan tener diferentes números de fuentes y sumideros, y estos pueden ser diferentes (o iguales) fuentes y sumideros específicos. No podemos definir más el “papel” del conjunto {B, C, D}, porque hemos agotado sus barrios. Es decir, las fuentes a las que están conectados nuestros repetidores no pueden diferenciarse aún más en múltiples tipos (porque solo hay una fuente); los sumideros a los que envían nuestros repetidores no pueden diferenciarse más, porque ellos mismos no tienen más conexiones.
Consideremos ahora nuestros “sumideros” (es decir, los actores E, F, G, H e I). Cada uno está conectado a una fuente (aunque las fuentes pueden ser diferentes). Ya hemos determinado, en el caso actual, que todas estas fuentes (actores B, C y D) son regularmente equivalentes. Entonces, E a I están conectados equivalentemente con otros equivalentes. Ya terminamos con nuestro particionamiento.
El resultado de {A} {B, C, D} {E, F, G, H, I} satisface la condición de que cada actor en cada partición tenga el mismo patrón de conexiones con actores en otras particiones. La matriz de adyacencia permutada se muestra en la Figura 15.2.
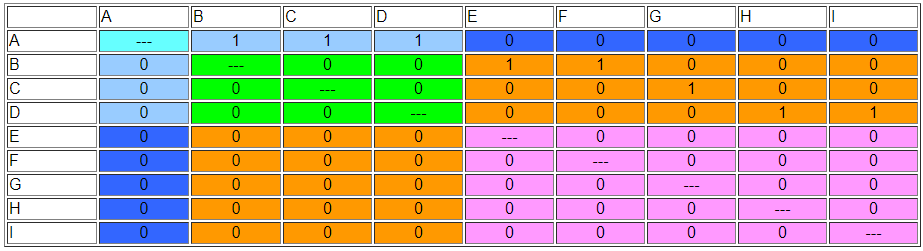
Figura 15.2: Red permutada de Wasserman-Fausto para mostrar clases de equivalencia regular
Es útil bloquear esta matriz y mostrar su imagen. Aquí, sin embargo, utilizaremos algunas reglas especiales para determinar los bloques cero y 1. Si un bloque es todo ceros, será un bloque cero. Si cada actor en una partición tiene un vínculo con algún actor en otro, entonces definiremos el bloque conjunto como un bloque de 1. Tened paciencia conmigo un momento. La imagen que utiliza esta regla se muestra en la Figura 15.3.

Figura 15.3: Imagen de bloque de clases de equivalencia regular en red dirigida Wasserman-Faust
{A} envía a uno o más de {BCD} pero a ninguno de {EFGHI}. {BCD} no envía a {A}, pero cada uno de {BCD} envía al menos a uno de {EFGHI}. Ninguno de {EFGHI} envía a ninguno de {A}, o de {BCD}. La imagen, de hecho, muestra el patrón característico de una jerarquía estricta: unos en el primer vector fuera de diagonal y ceros en otra parte. La regla de definir un bloque 1 cuando cada actor en una partición tiene una relación con cualquier actor en la otra partición es una manera de operacionalizar la noción de que los actores en el primer conjunto son equivalentes si están conectados a actores equivalentes (es decir, actores en la otra partición), sin requerir (o prohibiendo) que estén vinculados a los mismos otros actores, o al mismo número de actores en otra partición.
Para las gráficas binarias dirigidas, el método de búsqueda de vecindarios que aplicamos aquí suele funcionar bastante bien. Para las gráficas binarias que no son dirigidas, generalmente se calcula la distancia geodésica entre actores y se usa en lugar de la adyacencia cruda. Para gráficas con relaciones valoradas (fuerza, costo, probabilidad), White y Reitz desarrollaron un método para identificar equivalencia regular aproximada. Estas diversas alternativas se ilustran a continuación.
REGE categórico para datos binarios dirigidos (Red dirigida Wasserman-Faust)
El método de búsqueda de vecindarios ilustrado anteriormente (con la red dirigida Wasserman-Faust) es el algoritmo realizado por Network>Roles & Posiciones>Máximo Regular>Catrege. Este enfoque es ideal para redes donde las relaciones se miden a nivel nominal, y se dirigen. Nuestro ejemplo será de una gráfica binaria; el algoritmo, sin embargo, también puede tratar datos nominales multivalorados (por ejemplo, “1" = amigo, “2" = kin, “3" = compañero de trabajo, etc.).
Aplicando Redes>Roles y Posiciones>Máximo Regular>Catrege a la red dirigida Wasserman-Faust da los resultados mostrados en la Figura 15.4.
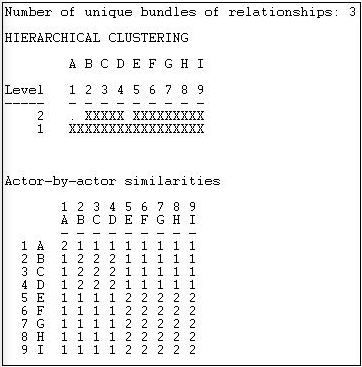
Figura 15.4: Análisis categórico de REGE de la red dirigida Wasserman-Faust
Este resultado es el mismo que el que hicimos “a mano” anteriormente en el capítulo. Un diagrama de agrupamiento jerárquico puede ser útil si las equivalencias encontradas son inexactas, o numerosas, y se necesita una simplificación adicional. Aquí, vemos en el nivel 2 del clustering que hay tres grupos {A}, {B, C, D}, y {E, F, G, H, I}. También se produce una matriz de imagen (pero no “reducida” a 3 por 3).
Los resultados también se pueden visualizar de manera útil con un dendograma, como en la Figura 15.5.
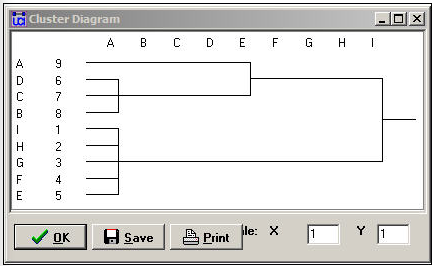
Figura 15.5: Dendograma de REGE categórica (Figura 15.4)
Sabemos, por nuestro análisis, que realmente hay exactamente tres clases de equivalencia regular. Si queremos usar solo dos, sin embargo, el dendograma sugiere que agrupar A con B, C y D sería la opción más razonable.
Una vez que se ha logrado un bloqueo de equivalencia regular, suele ser una buena idea producir una versión permutada y bloqueada de los datos originales para que puedas ver los perfiles de empate de cada una de las clases. Una forma de hacerlo es guardar el vector de permutación de Network>Roles y posiciones>Máximo Regular>Catrege, y usarlo para permutar los datos originales (Datos>Permute).
REGE categórica para distancias geodésicas (Datos de matrimonio de Padgett)
Los datos de Padgett sobre alianzas matrimoniales entre las principales familias florentinas son de baja a moderada densidad. Existen diferencias considerables entre las posiciones de las familias, como puede verse en la gráfica de la Figura 15.6. Los datos son binarios, y no dirigidos. Esto provoca un problema para el análisis regular de equivalencia, ya que todos los actores (excepto los aislados) son “equivalentes” como “transmisores”.
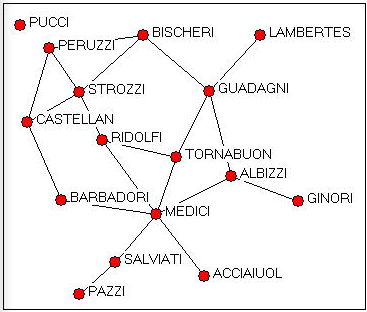
Figura 15.6: Alianzas matrimoniales florentinas Padgett
El algoritmo categórico REGE (Network>Roles & Posiciones>Máximo Regular>CATREGE) se puede utilizar para identificar actores regularmente equivalentes tratando los elementos de la matriz de distancia geodésica como describiendo “tipos” de lazos, es decir, diferentes distancias geodésicas se tratan como” cualitativamente” en lugar de “cuantitativamente” diferente. Dos nodos son más equivalentes si cada uno tiene un actor en su barrio del mismo “tipo”. En este caso, eso significa que son similares si cada uno tiene un actor que se encuentra a la misma distancia geodésica de sí mismos. Con muchos conjuntos de datos, los niveles de similitud de los barrios pueden llegar a ser bastante altos -y puede ser difícil diferenciar las posiciones de los actores por motivos de equivalencia “regulares”.
La Figura 15.7 muestra los resultados del análisis de equivalencia regular donde se han utilizado distancias geodésicas para representar múltiples tipos cualitativos de relaciones entre actores.

Figura 15.7: Análisis categórico multivalor (distancia geodésica) de alianzas matrimoniales Padgett
Dado que los datos están altamente conectados y las distancias geodésicas son cortas, no somos capaces de discriminar clases regulares altamente distintivas en estos datos. Dos familias (Albizzi y Ridolfi) sí emergen como más similares que otras, pero generalmente las diferencias entre perfiles son pequeñas.
El uso de REGE con datos no dirigidos, incluso sustituyendo distancias geodésicas por valores binarios, puede producir resultados bastante inesperados. Puede ser más útil combinar varios lazos diferentes para producir valores continuos. El principal problema, sin embargo, es que con datos no dirigidos, la mayoría de los casos parecerán ser muy similares entre sí (en el sentido “regular”), y ningún algoritmo realmente puede “arreglar” esto. Si las distancias geodésicas pueden ser utilizadas para representar diferencias en los tipos de lazos (y esta es una cuestión conceptual), y si los actores tienen alguna variabilidad en sus distancias, este método puede producir resultados significativos. Pero, en mi opinión, debería usarse con cautela, si acaso, con datos no dirigidos.
REGE Continuo para Distancias Geodésicas (Datos de Matrimonio de Padgett)
Un enfoque alternativo a los datos no dirigidos de Padgett es tratar los diferentes niveles de distancias geodésicas como medidas de (la inversa de) la fuerza de los lazos. Se dice que dos nodos son más equivalentes si tienen un actor de distancia similar en su vecindario (similar en el sentido cuantitativo de “5" es más similar a “4" que “6"). Por defecto, el algoritmo extiende la búsqueda a barrios de distancia 3 (aunque se pueden seleccionar menos o más).
En la Figura 15.8 se muestran los resultados de aplicar Network>Roles y Posiciones>Máximo Regular>Rege a los datos de Padgett, usando “3 iteraciones” (es decir, vecindarios de tres pasos).
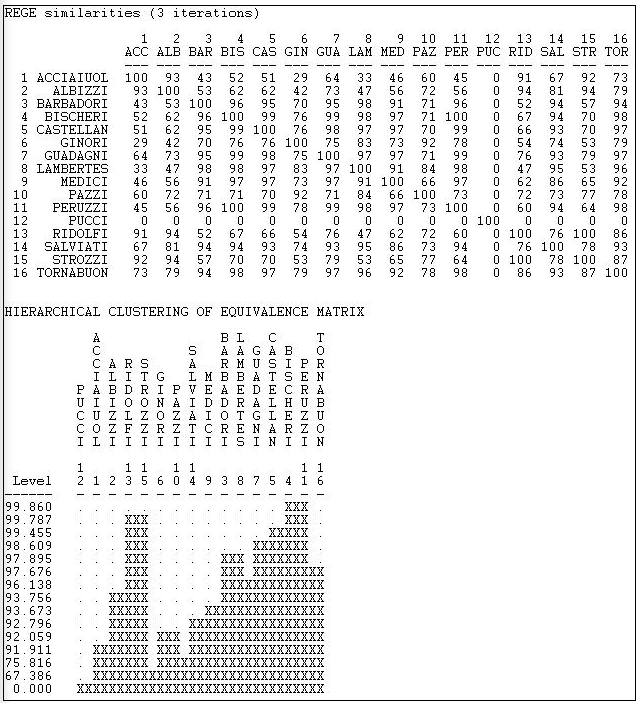
Figura 15.8: REGE continua de datos de alianza matrimonial Padgett
El primer panel de la salida muestra las similitudes regulares aproximadas por pares como una matriz. Tenga en cuenta que la familia aislada (Pucci) es tratada como una clase separada. También hay que señalar que estos resultados están encontrando características bastante diferentes de los datos que el tratamiento categórico. El algoritmo REGE continuo aplicado a los datos no dirigidos es probablemente una mejor opción que el enfoque categórico. El resultado aún muestra una equivalencia regular muy alta entre los actores, y la solución sólo es modestamente similar a la del enfoque categórico.
La red de intercambio de información de las burocracias de Knoke Analizada por Tabu Buscar
Al final de nuestro análisis en la sección “Encontrar conjuntos de equivalencia” anterior, producimos una versión “permutada y bloqueada” de nuestros datos. Al hacer esto, utilizamos algunas reglas que, de hecho, identifican cómo “parecen” las relaciones regulares de equivalencia. Para repetir los puntos principales: no nos importan los vínculos entre los miembros de una clase regular; los vínculos entre los miembros de una clase regular y otra clase son todos cero, o de tal manera que cada miembro de una clase tiene un vínculo con al menos un miembro de la otra clase.
Esta “imagen” de cómo se ven las clases regulares se puede utilizar para buscarlas usando métodos numéricos. El algoritmo Net>Roles y posiciones>Máximo Regular>Optimización busca ordenar los nodos en (un número seleccionado por el usuario de) categorías que se acerquen lo más posible a satisfacer la “imagen” de equivalencia regular. La Figura 15.9 muestra los resultados de aplicar este algoritmo a la red de información Knoke.
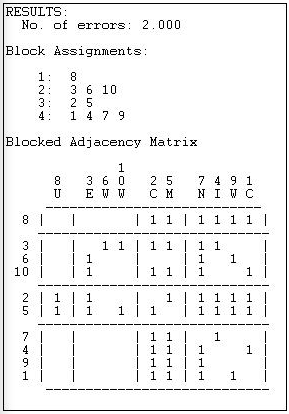
Figura 15.9: Cuatro clases de equivalencia regular para la red de información Knoke por búsqueda óptima
El método produce una estadística de ajuste (número de errores) y se deben comparar las soluciones para diferentes números de particiones.
La matriz de adyacencia bloqueada para la solución de cuatro grupos es, sin embargo, bastante convincente. De los 12 bloques de interés (los bloques en la diagonal no suelen ser tratados como relevantes para el análisis de “roles”) 11 satisfacen perfectamente las reglas para cero o uno bloques. Solo el bloque que conecta el envío desde {3, 6, 10} al bloque {2, 5} no logra satisfacer la imagen de equivalencia regular (porque el actor 6 no tiene vínculos de envío ni con el actor 2 ni con el 5).
La solución también es interesante de manera sustantiva. El tercer conjunto {2, 5} por ejemplo, son puros “repetidores” que envían y reciben de todos los demás roles. El conjunto {3, 6, 10} envía solo a otros dos tipos (no a los tres otros tipos) y recibe de un solo otro tipo. Y así sucesivamente.
El método de búsqueda tabú puede ser muy útil, y suele producir resultados bastante agradables. Es un algoritmo de búsqueda iterativa, sin embargo, y puede encontrar soluciones locales. Muchas redes tienen más de una partición válida por equivalencia regular, y no hay garantía de que el algoritmo siempre encuentre la misma solución. Se debe ejecutar varias veces con diferentes configuraciones de inicio.