
16.2: Conceptos básicos de datos multiplex
( \newcommand{\kernel}{\mathrm{null}\,}\)
Los datos multiplex son datos que describen múltiples relaciones entre un mismo conjunto de actores. Las medidas de las relaciones pueden ser dirigidas o no; y las relaciones se pueden registrar como binarias, nominales multivaloradas o valoradas (ordinal o intervalo).
La estructura más común para los datos multiplex es un conjunto de matrices actor por actor (o “cortes”), una para cada relación. La Figura 16.1 muestra la salida de Data>Display para el conjunto de datos de organizaciones de bienestar social Knoke, que contiene información sobre dos relaciones (binarias, dirigidas): intercambio de información (KNOKI) y cambio de dinero (KNOKM).

Figura 16.1: Datos>Visualización de la estructura de datos multi-relacional de Knoke
Las dos relaciones se almacenan como matrices separadas, pero dentro del mismo archivo. Muchas de las herramientas de análisis en UCINET procesarán cada matriz o “slice” de un archivo de datos de matriz múltiple como el ejemplo de Knoke. Data>Unpack se puede usar para eliminar matrices individuales de un archivo de matriz múltiple; Data>Join se puede usar para crear un conjunto de datos de matriz múltiple a partir de archivos de datos de matriz única separados.
El enfoque de matriz múltiple es más general, y nos permite registrar tantas relaciones diferentes como queramos mediante el uso de matrices separadas. Algunas matrices pueden ser simétricas y otras no; algunas pueden ser binarias y otras valoradas. Varias de las herramientas que discutiremos en breve, sin embargo, requerirán que los datos en las múltiples matrices sean del mismo tipo (simétrico/asimétrico, binario/valorado). Entonces, muchas veces será necesario hacer transformaciones en matrices individuales antes de que se puedan aplicar estrategias de “reducción” y “combinación”.
Una estructura de datos múltiplex estrechamente relacionada es la “Estructura social cognitiva” o CSS. Un CSS registra las percepciones de varios actores de las relaciones entre un conjunto de nodos. Por ejemplo, podríamos pedirle a cada uno de Bob, Carol, Ted y Alice que nos diga quién de ellos era amigo de quién. El resultado serían cuatro matrices de la misma forma (4 actores por 4 actores), reportando la misma relación (quién es amigo de quién), pero diferenciándose según quien esté haciendo el reportaje y percibiendo.
Los datos CSS tienen exactamente la misma forma que las rebanadas estándar actor por actor. Y algunas de las herramientas utilizadas para indexar datos CSS son las mismas. Debido a la naturaleza única de los datos CSS -que se centran en la percepción compleja de una sola estructura, en lugar de una sola percepción de una estructura compleja- se pueden aplicar algunas herramientas adicionales (más, a continuación).
Una tercera estructura de datos, y bastante diferente, es la matriz multivalorada. Supongamos que las relaciones entre actores eran nominales (es decir, cualitativas, o “present-ausentes”) pero hubo múltiples tipos de relaciones que cada par de actores podría tener, formando una poliotomía nominal. Es decir, cada par de actores tenía una (y sólo una) de varios tipos de relaciones. Por un ejemplo, las relaciones entre un conjunto de actores podrían (en algunas poblaciones) codificarse como “co-miembro de la familia nuclear” o “compañeros de trabajo” o “miembro de la familia extendida” o “correligionista” o “ninguno”. Para otro ejemplo, podríamos combinar múltiples relaciones para crear tipos cualitativos: 1 = solo kin, 2 = solo compañero de trabajo, 3 = tanto kin como compañero de trabajo, y 4 = ni kin ni compañero de trabajo.
Los datos nominales, pero multivalorados, combinan información sobre relaciones multiplex en una sola matriz. Los valores, sin embargo, no representan fuerza, costo o probabilidad de empate, sino que distinguen el tipo cualitativo de empate que existe entre cada par de actores. Grabar datos de esta manera es eficiente, y algunos algoritmos en UCINET (por ejemplo, Categorical REGE) pueden trabajar directamente con ellos. A menudo, sin embargo, los datos sobre relaciones multiplex que se han almacenado en una sola matriz multivalorada necesitarán transformarse antes de que podamos realizar muchas operaciones de red en ella.
Visualización de relaciones multiplex
Para redes relativamente pequeñas, dibujar gráficos es la mejor manera de “ver” la estructura. El único problema nuevo es cómo representar múltiples relaciones entre actores. Un enfoque es usar múltiples líneas (con diferentes colores o estilos) y superponer una relación sobre otra. Alternativamente, se pueden “agrupar” las relaciones en tipos cualitativos y representarlas con una sola gráfica usando líneas de diferentes colores o estilos (por ejemplo, kin tie = rojo; work tie = azul; kin y work tie = verde).
Netdraw cuenta con algunas herramientas útiles para visualizar múltiples relaciones entre un mismo conjunto de actores. Si los datos se han almacenado como múltiples matrices dentro del mismo archivo, cuando se abre ese archivo (NetDraw>Archivo>Abrir>UcinetDataset>Red) un cuadro de diálogo Lazos le permitirá seleccionar qué matriz ver (así como establecer valores de corte para visualizar datos valorados). Esto es útil para ir y venir entre relaciones, permaneciendo los nodos en las mismas ubicaciones. Supongamos, por ejemplo, que habíamos almacenado diez matrices en un archivo, reflejando instantáneas de relaciones en una red a medida que evolucionaba a lo largo de algún periodo de tiempo. Usando el diálogo Lazos, podemos “voltear las páginas” para ver cómo evoluciona la red.
Una herramienta aún más útil se encuentra en NetDraw>Propiedades>Líneas>Selección de relaciones múltiples. En la Figura 16.2 se muestra un dibujo de la red Knoke con este cuadro de diálogo visible.
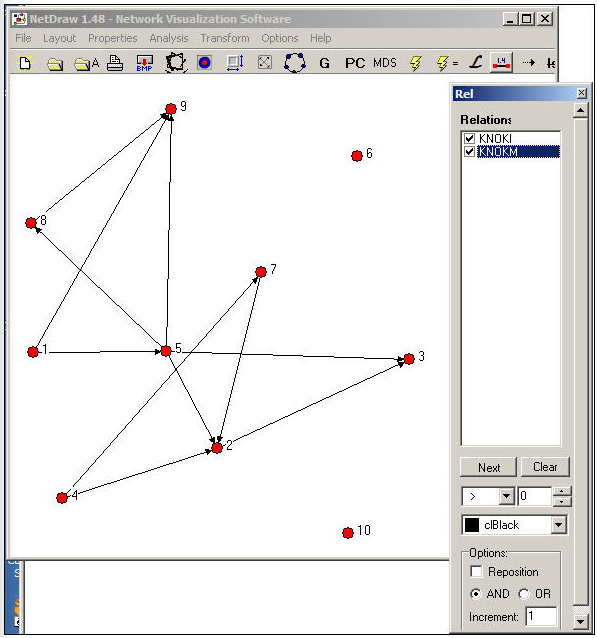
Figura 16.2: Gráfico NetDraw de redes de información y cambio de dinero de Knoke
El cuadro de diálogo Relaciones le permite seleccionar qué relaciones desea ver, y si ver la unión (“o”) o intersección (“y”) de los lazos. En nuestro ejemplo, hemos pedido ver el patrón de vínculos entre organizaciones que envían tanto información como dinero a otras.
Combinando relaciones múltiples
Para la mayoría de los análisis, la información sobre las múltiples relaciones entre actores deberá combinarse en una sola medida resumida. Un enfoque común es combinar las relaciones múltiples en un índice que refleje la calidad (o tipo) de la relación multiplex.
Transform>Multiplex se puede utilizar para resumir múltiples relaciones entre actores en un índice cualitativo multivalorado. Supongamos que habíamos medido dos relaciones entre Bob, Carol, Ted y Alice. La primera es una nominación dirigida a la amistad, y la segunda es una relación conyugal no dirigida. Estas dos matrices binarias de cuatro por cuatro se han empaquetado en un solo archivo de datos llamado BctaJoin. El cuadro de diálogo para Transform>Multiplex se muestra como Figura 16.3.
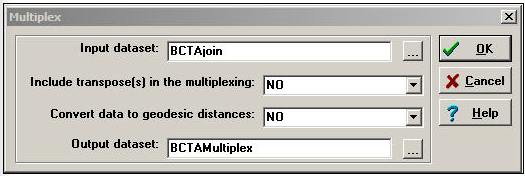
Figura 16.3: Diálogo Transform>Multiplex
Aquí hay dos opciones. Convertir datos a distancias geodésicas nos permite convertir primero cada relación en una métrica valorada a partir del binario. Nosotros hemos optado por no hacer esto. Otra opción es si incluir o no transposición (s) en la multiplexación. Para los datos asimétricos, seleccionar sí hará que las filas y las columnas de la matriz de entrada sean tratadas como relaciones separadas en la formación de las combinaciones cualitativas. Nuevamente, hemos optado por no hacer esto (aunque es una idea razonable en muchos casos reales).
En la Figura 16.4 se muestra el archivo de entrada, el cual está compuesto por dos matrices “apiladas” o “cortadas” que representan lazos de amistad y conyugales.

Figura 16.4: Transform>Entrada multiplex
En la Figura 16.5 se muestra la “tipología” resultante de tipos de relaciones entre los actores, la cual se ha generado como un índice nominal multivalorado.
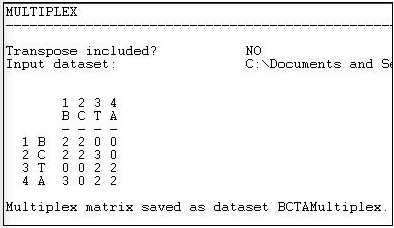
Figura 16.5: Transform>Salida multiplex
Donde no hay empate en ninguna de las matrices, se le ha asignado el tipo “0". Donde hay tanto una amistad como un empate conyugal, se le ha asignado el número “2"; donde hay un empate de amistad, pero no vínculo conyugal, se le ha asignado el número “3". Podría haber habido un tipo adicional (corbata conyugal, pero no amistad) al que se le habría asignado un número diferente.
Combinar múltiples relaciones de esta manera produce una tipología cualitativa de los tipos de relaciones que existen entre los actores. Un índice de este tipo podría ser de considerable interés para describir la prevalencia de los tipos en una población y seleccionar subgráficas para un análisis más detallado.
La operación Transform>Multígrafo hace lo contrario de lo que hace Transform>Multiplex. Es decir, si comenzamos con una matriz única multivalorada (como en la Figura 16.5), esta operación dividirá los datos y creará un archivo de datos de matriz múltiple con una matriz por cada “tipo” de relación. En el caso de nuestro ejemplo, Transform>Multígrafo generaría dos nuevas matrices (una describiendo la relación “2" y otra describiendo la relación “3").
Al tratar las múltiples relaciones entre actores, también podríamos querer crear un índice cuantitativo que combine las relaciones. Por ejemplo, podríamos suponer que si los actores están atados por 4 relaciones diferentes comparten un lazo “más fuerte” que si comparten solo 3 relaciones. Pero, hay muchas formas posibles de crear índices que capten diferentes aspectos o dimensiones de las múltiples relaciones entre actores. Dos kits de herramientas en UCINET admiten la combinación de múltiples matrices con una amplia variedad de funciones integradas para capturar diferentes aspectos de los datos multi-relacionales.
Transform>Operaciones de matriz>Operaciones de matriz>Entre Datasets>Resúmenes Estadísticos proporciona algunas herramientas básicas para crear una matriz de valor único a partir de múltiples matrices. La Figura 16.6 muestra el diálogo de esta herramienta.
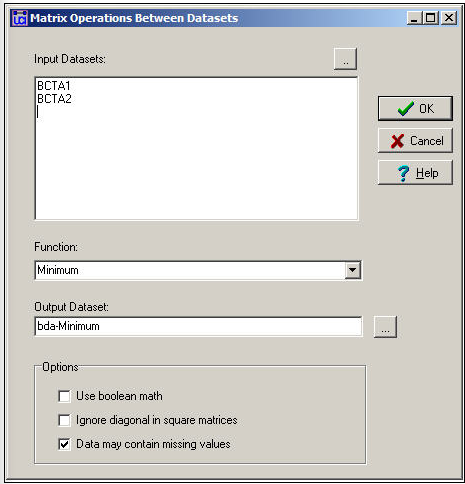
Figura 16.6: Diálogo entre operaciones de matriz de conjuntos de datos - resúmenes estadísticos
En el ejemplo, hemos seleccionado las dos matrices separadas de relación única para Bob, Carol, Ted y Alice, y solicitamos crear un nuevo conjunto de datos (matriz única) llamado BDA-Minimum. Al seleccionar la función Mínimo, hemos elegido una regla que dice: mirar las relaciones a través de las matrices, y resumir cada relación por pares como la más débil. Para los datos binarios, esto es lo mismo que la operación lógica “y”.
También están disponibles en este cuadro de diálogo Suma (que agrega los valores, por elementos, a través de matrices); Promedio (que computa la media, por elementos a través de matrices); Máximo (que selecciona el valor más grande, por elementos); y Multiplicación por elemento (que multiplica los elementos a través de matrices). Este es un kit de herramientas bastante útil, y captura la mayoría de las formas en que podrían crearse índices cuantitativos (empate más débil, empate más fuerte, empate promedio, interacción de corbatas).
Es posible que queramos combinar la información sobre relaciones múltiples en un índice cuantitativo usando operaciones lógicas en lugar de numéricas. La Figura 16.7 muestra el diálogo para Transform>Operaciones de matriz>Operaciones de matriz>Entre Datasets>Combinaciones Booleanas.
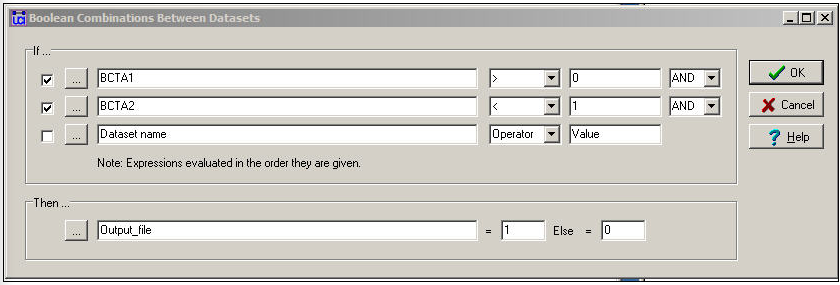
Figura 16.7: Diálogo entre operaciones de matriz de conjuntos de datos - Combinaciones booleanas
En este diálogo, hemos dicho: si hay un empate de amistad y no hay vínculo conyugal, entonces codifica la relación de salida como “1". De lo contrario, codifique la relación de salida como “0". Esto no es algo muy sensato de hacer, pero ilustra el punto de que esta herramienta puede ser utilizada para realizar operaciones lógicas básicas para crear índices valorados (o binarios) que combinen la información sobre múltiples relaciones.
Combinando múltiples vistas
Supongamos que le pedí a cada miembro de la facultad de mi departamento que llenara un cuestionario informando sobre sus percepciones de a quién le gusta a quién entre la facultad. Estaríamos recopilando datos de “estructura social cognitiva”; es decir, informes de actores incrustados en una red sobre toda la red. Existe una literatura de investigación muy interesante que explora la relación entre las posiciones de los actores en las redes, y sus percepciones de la red. Por ejemplo, ¿tienen los actores un sesgo hacia percibir sus propias posiciones como más “centrales” que las percepciones de otros actores sobre su centralidad?
Un conjunto de datos de estructura social cognitiva (CSS) contiene múltiples matrices actor por actor. Cada matriz informa sobre el conjunto completo de una relación única entre todos los actores, tal como lo percibe un encuestado particular. Si bien podríamos usar muchas de las herramientas discutidas en la sección anterior para combinar o reducir datos como estos en índices, existen algunas herramientas especiales que se aplican a los datos cognitivos. La Figura 16.8 muestra el diálogo de datos>CSS, que proporciona acceso a algunas herramientas especializadas para la investigación cognitiva en redes.
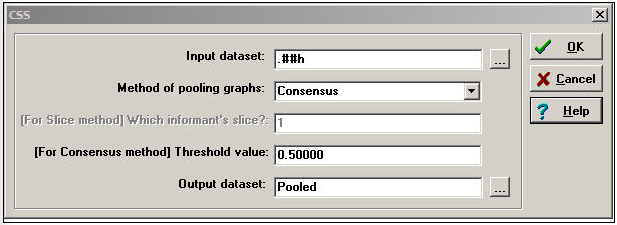
Figura 16.8: Diálogo para datos>CSS
El elemento clave aquí es la elección del Método para aunar gráficas. Al crear un único resumen de las relaciones, podríamos seleccionar las percepciones de un solo actor; o bien, podríamos querer enfocarnos en las percepciones de la pareja de actores involucrados en cada relación particular; o podríamos querer combinar la información de todos los actores de la red.
Slice selecciona la percepción de un actor en particular para representar la red (el diálogo pregunta entonces, “¿qué informante?”). Si tuviéramos un informante experto en particular, podríamos elegir su visión de la red como un resumen. O bien, podríamos extraer múltiples actores diferentes en diferentes archivos. También podríamos extraer actores basados en algún atributo (por ejemplo, género) y extraer sus gráficos, luego agruparlos por algún otro método.
La fila LAS utiliza los datos de la fila de cada actor para ser la entrada de fila en la matriz de salida. Es decir, las percepciones del actor A de sus valores de fila se utilizan para la fila A en la matriz de salida; las percepciones del actor B de sus valores de fila se utilizan para la fila B en la matriz de salida. Esto utiliza a cada actor como el “informante” sobre sus propios out-ties.
Columna LAS utiliza la columna de cada actor para ser la entrada de columna en la matriz de salida. Es decir, cada actor está siendo utilizado como el “informante” respecto a sus propios vínculos.
Intersección LAS construye la matriz de salida examinando las entradas del par particular de actores involucrados. Por ejemplo, en la matriz de salida tendríamos un elemento que describiera la relación entre Bob y Ted. Tenemos datos sobre cómo Bob, Ted, Carol y Alice perciben cada uno la relación de Bob y Ted. El método LAS se enfoca solo en los dos nodos involucrados (Bob y Ted) e ignora a los demás. El método de intersección le da un “1" al empate si tanto Bob como Ted dicen que hay empate, y un “0" de lo contrario.
Union LAS asigna un “1" a la relación de pares si alguno de los actores (es decir, Bob o Ted) dice que hay un empate.
Mediana LAS selecciona la mediana de los dos valores para la relación B, T que son reportados por B y por T. Esto es útil si la relación que se examina es valorada, en lugar de binaria.
El consenso utiliza las percepciones de todos los actores para crear el índice resumido. Se suman las percepciones de Bob, Carol, Ted y Alice, y si la suma es mayor que un valor de corte especificado por el usuario, se asigna “1", sino “0".
Promedio calcula el promedio numérico de las percepciones de todos los actores sobre cada empate por pares.
Sum calcula la suma de todas las percepciones de los actores para cada empate por pares.
El rango de opciones aquí sugiere un área fértil de investigación sobre cómo los actores incrustados en las relaciones perciben esas relaciones. La variedad de métodos de indexación también sugiere una serie de preguntas interesantes sobre, y métodos para tratar, la confiabilidad de los datos de la red cuando se recopilan de encuestados incrustados.