
18.3: Comparando dos relaciones para el mismo conjunto de actores
- Page ID
- 115167
La cuestión básica de la estadística descriptiva bivariada aplicada a las variables es si las puntuaciones en un atributo se alinean (co-varían, correlacionan) con las puntuaciones en otro , cuando se compara entre los casos. La cuestión básica del análisis bivariado de los datos de la red es si el patrón de vínculos para una relación entre un conjunto de actores se alinea con el patrón de vínculos para otra relación entre los mismos actores. Es decir, ¿se correlacionan las relaciones?
Tres de las herramientas más comunes para el análisis bivariado de atributos también se pueden aplicar al análisis bivariado de relaciones:
¿La tendencia central de una relación difiere significativamente de la tendencia central de otra? Por ejemplo, si tuviéramos dos redes que describieran los lazos militares y económicos entre las naciones, ¿cuál tiene la mayor densidad? ¿Son más prevalentes los lazos militares o económicos? Este tipo de pregunta es análoga a la prueba de la diferencia entre medias en el análisis de atributos pareados o de medidas repetidas.
¿Existe correlación entre los lazos que están presentes en una red, y los lazos que están presentes en otra? Por ejemplo, ¿los pares de naciones que tienen alianzas políticas tienen más probabilidades de tener altos volúmenes de comercio económico? Este tipo de pregunta es análoga a la correlación entre las puntuaciones en dos variables en el análisis de atributos.
Si sabemos que existe una relación de un tipo entre dos actores, ¿cuánto aumenta (o disminuye) esta probabilidad de que exista una relación de otro tipo entre ellos? Por ejemplo, ¿cuál es el efecto de un incremento de un dólar en el volumen de comercio entre dos naciones sobre el volumen de turismo que fluye entre ambas naciones? Este tipo de pregunta es análoga a la regresión de una variable sobre otra en el análisis de atributos.
Hipótesis sobre dos medias o densidades emparejadas
En el apartado anterior sobre estadísticas univariadas para redes, señalamos que la densidad de la matriz de intercambio de información para las burocracias de Knoke parecía ser superior a la densidad de la matriz cambiaria. Es decir, la media o densidad de una relación entre un conjunto de actores parece ser diferente de la media o densidad de otra relación entre los mismos actores.
Redes>Comparar densidades>Pareado (mismo nodo) compara las densidades de dos relaciones para los mismos actores y calcula los errores estándar estimados para probar las diferencias por métodos bootstrap. Cuando ambas relaciones son binarias, esta es una prueba de diferencias en la probabilidad de un empate de un tipo y la probabilidad de un empate de otro tipo. Cuando se valoran ambas relaciones, esta es una prueba de una diferencia en las fortalezas medias de empate de las dos relaciones.
Realicemos esta prueba sobre las relaciones de información y cambio de dinero en los datos de Knoke, como se muestra en la Figura 18.7.
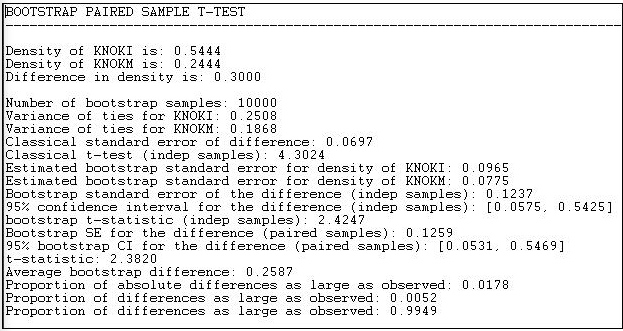
Figura 18.7: Prueba para la diferencia de densidad en las relaciones informativas y cambiarias de Knoke
Los resultados tanto para el enfoque estándar como para el enfoque bootstrap (esta vez, ejecutamos 10,000 submuestras) se reportan en la salida. La diferencia entre medias (o proporciones, o densidades) es de 0.3000. El error estándar de la diferencia por el método clásico es 0.0697; el error estándar por estimación bootstrap es 0.1237. El enfoque convencional subestima en gran medida la variabilidad del muestreo real, y da un resultado demasiado optimista al rechazar la hipótesis nula de que las dos densidades son las mismas.
Por el método bootstrap, podemos ver que hay una probabilidad de dos colas de 0.0178. Si tuviéramos una hipótesis alternativa previa sobre la dirección de la diferencia, podríamos usar el nivel de p de una cola de 0.0052. Entonces, podemos concluir con gran confianza que la densidad de vínculos de información entre las organizaciones es mayor que la densidad de los vínculos monetarios. Es decir, la diferencia observada surgiría muy raramente por casualidad en muestras aleatorias extraídas de estas redes.
Correlación entre dos redes con los mismos actores
Si hay un vínculo entre dos actores particulares en una relación, ¿es probable que haya un vínculo entre ellos en otra relación? Si dos actores tienen un fuerte lazo de un tipo, ¿es probable que también tengan un fuerte lazo de otro?
Cuando tenemos información sobre múltiples relaciones entre los mismos conjuntos de actores, a menudo es de considerable interés si la probabilidad (o fuerza) de un empate de un tipo está relacionado con la probabilidad (o fuerza) de otro. Considera los lazos de información y dinero de Knoke. Si las organizaciones intercambian información, esto puede crear un sentido de confianza, haciendo más probables las relaciones de cambio monetario; o, si intercambian dinero, esto puede facilitar comunicaciones más abiertas. Es decir, podríamos plantear la hipótesis de que la matriz de relaciones de información estaría correlacionada positivamente con la matriz de las relaciones monetarias; los pares que participan en un tipo de intercambio tienen más probabilidades de involucrarse en el otro. Alternativamente, podría ser que las relaciones sean complementarias: el dinero fluye en una dirección, la información en la otra (una correlación negativa). O bien, puede ser que las dos relaciones no tengan nada que ver entre sí (sin correlación).
Herramientas>Hipótesis de Prueba>Diádica (QAP) >Correlación QAP calcula medidas de asociación nominal, ordinal e intervalo entre las relaciones en dos matrices, y utiliza procedimientos de asignación cuadrática para desarrollar errores estándar para probar la significancia de asociación. En la Figura 18.8 se muestran los resultados de la correlación entre las redes de información Knoke y de intercambio monetario.

Figura 18.8: Asociación entre la información de Knoke y las redes monetarias de Knoke por correlación QAP
La primera columna muestra los valores de cinco medidas alternativas de asociación. La correlación de Pearson es una medida estándar cuando ambas matrices tienen relaciones valoradas medidas a nivel de intervalo. Gamma sería una opción razonable si una o ambas relaciones se midieran en una escala ordinal. La coincidencia simple y el coeficiente de Jaccard son medidas razonables cuando ambas relaciones son binarias; la distancia de Hamming es una medida de disimilitud o distancia entre las puntuaciones en una matriz y las puntuaciones en la otra (es el número de valores que difieren, por elementos, de una matriz a otra).
La tercera columna (Avg) muestra el valor promedio de la medida de asociación a través de un gran número de ensayos en los que las filas y columnas de las dos matrices han sido permutado aleatoriamente. Es decir, ¿cuál sería la correlación (u otra medida), en promedio, si emparejáramos actores aleatorios? La idea del “Procedimiento de Asignación Cuadrática” es identificar el valor de la medida de asociación cuando en realidad no es ninguna conexión sistemática entre las dos relaciones. Este valor, como puede ver, no es necesariamente cero —porque diferentes medidas de asociación tendrán rangos limitados de valores basados en las distribuciones de puntuaciones en las dos matrices. Observamos, por ejemplo, que se observa una coincidencia simple de 0.456 (es decir, si hay un 1 en una celda en la matriz uno, hay un 45.6% de probabilidad de que haya un 1 en la celda correspondiente de la matriz dos). Esto parecería indicar asociación. Pero, debido a la densidad de las dos matrices, emparejar matrices reordenadas aleatoriamente mostrará una coincidencia promedio de .475. Por lo que la medida observada apenas difiere de un resultado aleatorio.
Para probar la hipótesis de que existe asociación, observamos la proporción de ensayos aleatorios que generarían un coeficiente tan grande como (o tan pequeño como, dependiendo de la medida) el estadístico realmente observado. Estas cifras se reportan (de los ensayos de permutación aleatoria) en las columnas etiquetadas “P (grande)” y “P (pequeña)”. El apropiado de estos valores para probar la hipótesis nula de no asociación se muestra en la columna “Signif”.
Regresión de red
En lugar de correlacionar una relación con otra, es posible que deseemos predecir una relación conociendo a la otra. Es decir, más que la asociación simétrica entre las relaciones, es posible que deseemos examinar la asociación asimétrica. La herramienta estándar para esta pregunta es la regresión lineal, y el enfoque puede extenderse al uso de más de una variable independiente.
Supongamos, por ejemplo, que quisiéramos ver si podíamos predecir cuál de las burocracias de Knoke enviaba información a cuáles otras. Podemos tratar la red de intercambio de información como nuestra red “dependiente” (con N = 90).
Podríamos plantear la hipótesis de que la presencia de un vínculo de dinero de una organización a otra aumentaría la probabilidad de un vínculo de información (por supuesto, del anterior sección, ¡sabemos que esto no está apoyado empíricamente!). Además, podríamos plantear la hipótesis de que organizaciones institucionalmente similares tendrían más probabilidades de intercambiar información. Entonces, hemos creado otra matriz de 10 por 10, codificando cada elemento para que sea un “1" si ambas organizaciones en la díada son órganos gubernamentales, o ambas son organismos no gubernamentales, y “0" si son de tipo mixto.
Ahora podemos realizar un análisis estándar de regresión múltiple mediante la regresión de cada elemento de la red de información sobre sus elementos correspondientes en la red monetaria y la red de instituciones gubernamentales. Para estimar los errores estándar para R-cuadrado y para los coeficientes de regresión, podemos utilizar la asignación cuadrática. Ejecutaremos muchos ensayos con las filas y columnas en la matriz dependiente aleatoriamente barajadas, y recuperaremos los coeficientes R-cuadrados y de regresión de estas corridas. Estos se utilizan para ensamblar distribuciones empíricas de muestreo para estimar errores estándar bajo la hipótesis de no asociación.
La versión 6.81 de UCINET ofrece cuatro métodos alternativos para Herramientas>Hipótesis de Prueba>Diádica (QAP) >Regresión QAP . La Figura 18.9 muestra los resultados del método de "partialización completa"”.
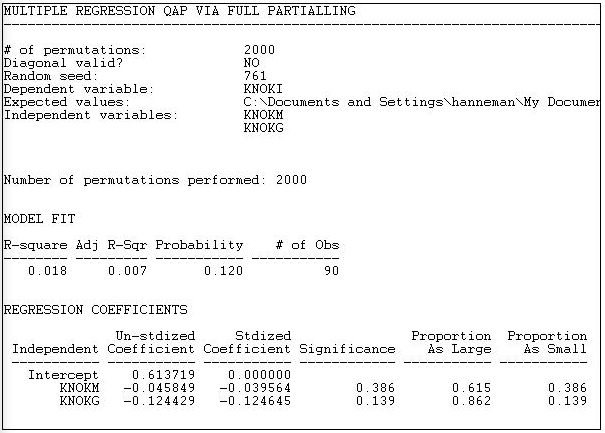
Figura 18.9: Regresión QAP de vínculos de información sobre vínculos monetarios y estatus gubernamental mediante el método de partialling completo
La estadística descriptiva y la medida de bondad de ajuste son resultados estándar de regresión múltiple, excepto, por supuesto, que estamos buscando predecir relaciones entre actores, no los atributos de los actores.
El modelo R-cuadrado (0.018) indica que saber si una organización envía dinero a otra, y si las dos organizaciones son institucionalmente similares reduce incertidumbre en la predicción de un empate de información en solo alrededor del 2%. El nivel de significancia (por el método QAP) es 0.120. Por lo general, concluiríamos que no podemos estar seguros de que el resultado observado sea no aleatorio.
Dado que la matriz dependiente en este ejemplo es binaria, la ecuación de regresión es interpretable como un modelo de probabilidad lineal (uno podría querer considerar logit o probit modelos — pero UCINET no proporciona estos). El intercepto indica que, si dos organizaciones no son del mismo tipo institucional, y una no envía dinero a la otra, la probabilidad de que una envíe información a la otra es de 0.61. Si una organización envía dinero a la otra, esto reduce la probabilidad de un enlace de información en 0.046. Si las dos organizaciones son del mismo tipo institucional, la probabilidad de envío de información se reduce en 0.124.
Sin embargo, usando el método QAP, ninguno de estos efectos es diferente de cero en niveles convencionales (p. ej. p < 0.05). Los resultados son interesantes: sugieren que los vínculos monetarios e informativos son, en todo caso, alternativos en lugar de reforzar los vínculos, y que las organizaciones institucionalmente similares tienen menos probabilidades de comunicarse. Pero, no debemos tomarnos en serio estos aparentes patrones, porque podrían aparecer con bastante frecuencia simplemente por permutación aleatoria de los casos.
Las herramientas de esta sección son muy útiles para examinar cómo “van juntas” las relaciones multiplex entre un conjunto de actores. Estas herramientas a menudo pueden ser útiles adiciones a algunas de las herramientas para trabajar con datos multiplex que examinamos en el capítulo 16.