
18.4: Explicación de los atributos de los actores en red
- Page ID
- 115166
En la sección anterior examinamos métodos para probar diferencias y asociación entre redes enteras. Es decir, estudiar los macro-patrones de cómo la posición de un actor en una red podría estar asociada con su posición en otra.
A menudo también nos interesan las micro preguntas. Por ejemplo: ¿el género de un actor afecta su centralidad entre ellos? Esta pregunta relaciona un atributo (género) con una medida de la posición del actor en una red (centralidad entre medias). Nos podría interesar la relación entre dos (o más) aspectos de las posiciones del actor. Por ejemplo: ¿cuánto de la variación en la centralidad entre actores puede explicarse por su grado de salida y el número de camarillas a las que pertenecen? Incluso podríamos estar interesados en la relación entre dos atributos individuales entre un conjunto de actores que están conectados en una red. Por ejemplo, en un aula escolar, ¿existe una asociación entre el género del actor y su rendimiento académico?
En todos estos casos nos estamos enfocando en variables que describen nodos individuales. Estas variables pueden ser atributos no relacionales (como género), o variables que describen algún aspecto de la posición relacional de un individuo (como el entretiempo). En la mayoría de los casos, se pueden aplicar herramientas estadísticas estándar para el análisis de variables para describir diferencias y asociaciones.
Pero, las herramientas estadísticas estándar para el análisis de variables no pueden aplicarse a preguntas inferenciales — pruebas de hipótesis o significancia, porque los individuos están examinando no son observaciones independientes sacadas al azar de alguna gran población. En lugar de aplicar las fórmulas normales (es decir, las integradas en paquetes de software estadístico y discutidas en la mayoría de los textos estadísticos básicos), necesitamos usar otros métodos para obtener estimaciones más correctas de la confiabilidad y estabilidad de las estimaciones (es decir, errores estándar). El enfoque “boot-strapping” (estimando la variación de estimaciones del parámetro de interés a partir de grandes números de submuestras aleatorias de actores) se puede aplicar en algunos casos; en otros casos, se puede aplicar la idea de permutación aleatoria para generar errores estándar correctos.
Hipótesis sobre las medias de dos grupos
Supongamos que teníamos la noción de que las organizaciones privadas con fines de lucro tenían menos probabilidades de participar activamente en el intercambio de información con otras personas en su campo que organizaciones gubernamentales. Nos gustaría probar esta hipótesis comparando el grado promedio de actores gubernamentales y no gubernamentales en un campo organizacional.
Usando la red de intercambio de información de Knoke, ejecutamos Redes>Centralidad>Grado , y guardó los resultados en el archivo de salida “FreeManDegree” como un conjunto de datos UCINET. También hemos utilizado Data>Hojas de cálculo>Matrix para crear un archivo de atributos UCINET “knokegovt” que tenga un código ficticio de una sola columna (1 = organización gubernamental, 0 = organización no gubernamental).
Realicemos una simple prueba t de dos muestras para determinar si la centralidad media del grado de las organizaciones gubernamentales es inferior a la centralidad media de grados de las organizaciones no- organizaciones gubernamentales. La Figura 18.10 muestra el cuadro de diálogo para Herramientas>Hipótesis de prueba>Nivel de nodo>Prueba T para configurar esta prueba.
Figura 18.10: Diálogo para Herramientas>Hipótesis de prueba>Nivel de nodo>Prueba T
Ya que estamos trabajando con nodos individuales como observaciones, los datos se ubican en una columna (o, a veces, una fila) de uno o más archivos. Observe cómo se ingresan en el cuadro de diálogo los nombres de archivo (seleccionados por navegación o mecanografiados) y las columnas dentro del archivo. La medida normalizada de centralidad del grado Freeman pasa a estar ubicada en la segunda columna de su archivo; solo hay un vector (columna) en el archivo que creamos para codificar organizaciones gubernamentales o no gubernamentales.
Para esta prueba, hemos seleccionado el valor por defecto de 10,000 ensayos para crear la distribución de muestreo basada en permutación de la diferencia entre las dos medias. Para cada uno de estos ensayos, los puntajes sobre la centralización normalizada de grados Freeman se permutan aleatoriamente (es decir, asignados aleatoriamente a gobierno o no gubernamental, proporcional al número de cada tipo). La desviación estándar de esta distribución basada en ensayos aleatorios se convierte en el error estándar estimado para nuestra prueba. La Figura 18.11 muestra los resultados.
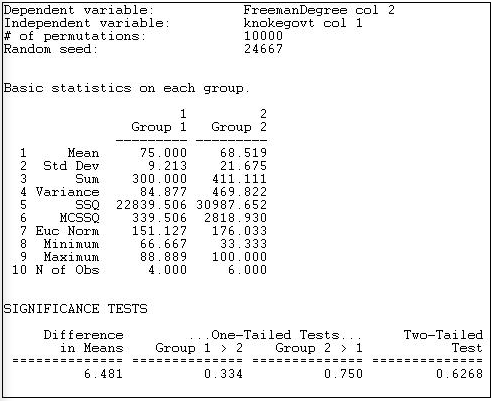
Figura 18.11: Prueba de diferencia en la centralidad media de grados normalizados de organizaciones gubernamentales y no gubernamentales de Knoke
El resultado primero reporta estadísticas descriptivas básicas para cada grupo. Los números de grupo se asignan según el orden de los casos en el expediente que contiene la variable independiente. En nuestro ejemplo, el primer nodo fue COUN, una organización gubernamental; así, el gobierno se convirtió en “Grupo 1" y el no gobierno se convirtió en “Grupo 2".
Vemos que la centralidad promedio de grado normalizado de las organizaciones gubernamentales (75) es 6.481 unidades superior a la centralidad promedio de grado normalizado de las organizaciones no gubernamentales organizaciones (68.519). Esto parecería apoyar nuestra hipótesis; pero las pruebas de significancia estadística exigen una considerable cautela. Diferencias tan grandes como 6.481 a favor de las organizaciones gubernamentales ocurren 33.4% del tiempo en ensayos aleatorios, por lo que estaríamos corriendo un riesgo inaceptable de equivocarnos si concluyéramos que los datos eran consistentes con nuestra hipótesis de investigación.
UCINET no imprime el error estándar estimado, ni los valores de la prueba t convencional de dos grupos.
Hipótesis sobre las medias de grupos múltiples
El enfoque para estimar la diferencia entre las medias de dos grupos discutidos en la sección anterior se puede extender a múltiples grupos con análisis unidireccional de varianza (ANOVA). El procedimiento Herramientas>Hipótesis de prueba>Nivel de nodo>ANOVA proporciona el enfoque regular de OLS para estimar las diferencias en las medias grupales. Debido a que nuestras observaciones no son independientes, también se aplica el procedimiento de estimación de errores estándar mediante replicaciones aleatorias.
Supongamos que dividimos los 23 grandes donantes a campañas políticas de California en tres grupos, y hemos codificado un vector de columna única en un archivo de atributos de la UCINET. Hemos codificado a cada donante como que cae en uno de tres grupos: “otros”, “capitalistas” o “trabajadores”.
Si examinamos la red de conexiones entre donantes (definida por la coparticipación en las mismas campañas), anticipamos que los grupos de trabajadores exhibirán mayor centralidad de vectores propios que los donantes en los otros grupos. Es decir, anticipamos que los grupos de interés “de izquierda” mostrarán una interconexión considerable, y —en promedio— tendrán miembros que están más conectados con otros altamente conectados de lo que es cierto para los capitalistas y otros grupos. Hemos calculado la centralidad de los vectores propios usando Network>Centralidad>Eigenvector , y almacenó los resultados en otro archivo de atributos de la UCINET.
El diálogo para Herramientas>Hipótesis de prueba>Nivel de nodo>ANOVA se parece mucho a Herramientas>Probar hipótesis > Nodo-nivel>T-test , así que no lo mostraremos. Los resultados de nuestro análisis se muestran en la figura 18.12.
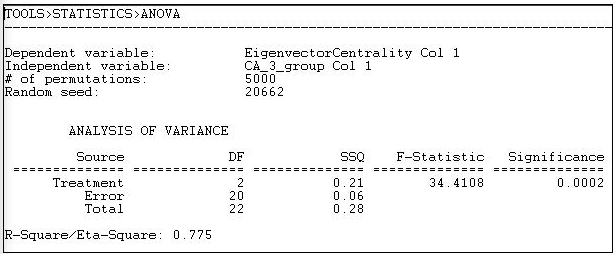
Figura 18.12: ANOVA unidireccional de centralidad de vectores propios de donantes políticos de California, con errores estándar basados en permutación y pruebas
La centralidad media de los ocho “otros” donantes es de .125. Para los siete “capitalistas” es 0.106, y para los siete grupos “obreros” es 0.323 (calculado en otra parte). Las diferencias entre estas medias son altamente significativas (F = 34.4 con 2 d.f. y p = 0.0002). Las diferencias en las medias grupales representan 78% de la varianza total en los puntajes de centralidad de vectores propios entre los donantes.
Posición Regresiva en Atributos
Donde el atributo de actores que nos interesa explicar o predecir se mide a nivel de intervalo, y uno o más de nuestros predictores también están en el nivel de intervalo, la regresión lineal múltiple es un enfoque común. Herramientas>Hipotesis de prueba>Nivel de nodo>Regresión calculará las estadísticas básicas de regresión múltiple lineal por OLS y estimará los errores estándar y la significación usando el método de permutaciones aleatorias para construir distribuciones de muestreo de coeficientes R cuadrados y de pendiente.
Continuemos con el ejemplo en la sección anterior. Nuestro atributo dependiente, como antes, es la centralidad de los vectores propios de los donantes políticos individuales. Esta vez, usaremos tres vectores independientes, que hemos construido usando Datos>Hojas de cálculo> Matriz , como se muestra en la figura 18.13.
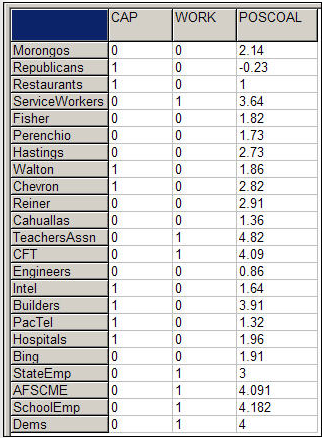
Figura 18.13: Construcción de vectores independientes para regresión lineal múltiple
Se han construido dos variables ficticias para indicar si cada donante es miembro del grupo “capitalista” o del grupo “obrero”. La categoría omitida (“otra”) servirá como categoría de interceptación/referencia. POSCOAL es el número medio de veces que cada donante participa del mismo lado de los asuntos con otros donantes (una puntuación negativa indica oposición a otros donantes).
Sustancialmente, estamos tratando de averiguar si la mayor centralidad de los “trabajadores” (observada en la sección anterior) es simplemente una función de tasas más altas de participación en coaliciones, o si los trabajadores tienen aliados mejor conectados —independientemente de la alta participación.
La Figura 18.14 muestra el diálogo para especificar los vectores dependientes y los múltiples independientes.
Figura 18.14: Diálogo para Herramientas>Hipótesis de prueba>Nivel de nodo>Regresión
Tenga en cuenta que todas las variables independientes deben ingresarse en un solo conjunto de datos (con múltiples columnas). Todas las estadísticas básicas de regresión se pueden guardar como salida, para su uso en gráficos o análisis posteriores. La Figura 18.15 muestra el resultado de la estimación de regresión múltiple.
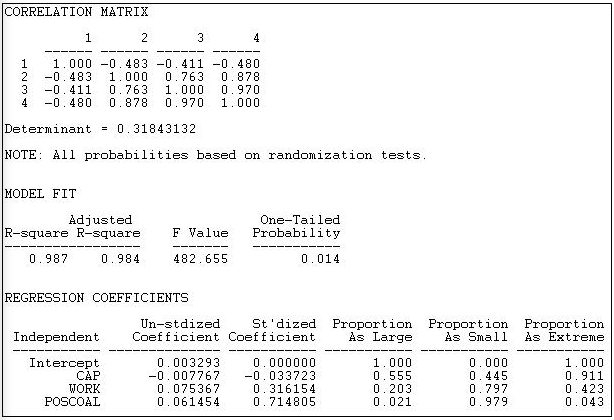
Figura 18.15: Regresión múltiple de centralidad de vectores propios con pruebas de significancia basadas en permutación
La matriz de correlación muestra una colinealidad muy alta entre estar en el grupo de trabajadores (variable 3) y participación en coaliciones (variable 4). Esto sugiere que puede ser difícil separar los efectos de la simple participación de los de ser un grupo de interés obrero.
El R-cuadrado es muy alto para este modelo simple (.987), y altamente significativo mediante pruebas de permutación (p = 0.014).
Al controlar la participación total de la coalición, es probable que los intereses capitalistas tengan una centralidad eigenvector ligeramente menor que otros (-0.0078), pero esto no es significativo (p = 0.555). Los grupos de trabajadores sí parecen tener mayor centralidad de vectores propios, incluso controlando la participación total de la coalición (0.075), pero esta tendencia puede ser un resultado aleatorio (una significación de una cola es solo p = 0.102). Cuanto mayor sea la tasa de participación en coaliciones (POSCOAL), mayor será la centralidad de los actores propios (0.0615, p = 0.021), independientemente del tipo de interés que se esté representando.
Como antes, los coeficientes son generados por técnicas estándar de modelado lineal OLS, y se basan en la comparación de puntuaciones en atributos independientes y dependientes de actores individuales. Lo que aquí difiere es el reconocimiento de que los actores no son independientes, por lo que es necesaria la estimación de errores estándar por simulación, más que por fórmula estándar.
Los enfoques de prueba t, ANOVA y regresión discutidos en esta sección se calculan a nivel micro o actor individual. Las medidas que se analizan como independientes y dependientes pueden ser relacionales o no relacionales. Es decir, podríamos estar interesados en predecir y probar hipótesis sobre los atributos no relacionales de los actores (por ejemplo, sus ingresos) utilizando una mezcla de atributos relacionales (por ejemplo, centralidad) y no relacionales (por ejemplo, género). Podríamos estar interesados en predecir un atributo relacional de actores (por ejemplo, centralidad) usando una mezcla de variables independientes relacionales y no relacionales.
Los ejemplos ilustran cómo los atributos relacionales y no relacionales de los actores pueden analizarse mediante técnicas estadísticas comunes. La clave para recordar, sin embargo, es que las observaciones no son independientes (ya que todos los actores son miembros de una misma red). Debido a esto, se necesita una estimación directa de las distribuciones de muestreo y estadísticas inferenciales resultantes; el software estadístico estándar y básico no dará respuestas correctas.