
19.2: Construyendo un Modelo Basado en Agentes




- Última actualización
- 30 oct 2022
- Guardar como PDF
( \newcommand{\kernel}{\mathrm{null}\,}\)
Empecemos con el modelado basado en agentes. De hecho, ya existen muchos tutoriales geniales sobre cómo construir un ABM, especialmente los de Charles Macal y Michael North, renombrados modeladores basados en agentes en el Laboratorio Nacional Argonne [84]. Macal y Norte sugieren considerar los siguientes aspectos al diseñar un modelo basado en agentes:
- Problema específico a resolver por la ABM
- Diseño de agentes y sus atributos estáticos/dinámicos
- Diseño de un entorno y la forma en que los agentes interactúan con él
- Diseño de comportamientos de los agentes
- Diseño de interacciones mutuas de agentes
- Disponibilidad de datos
- Método de validación del modelo
Entre esos puntos, 1, 6 y 7 se refieren a metodologías científicas fundamentales. Es importante tener en cuenta que solo construir un ABM arbitrario y obtener resultados por simulación no produciría ninguna conclusión científicamente significativa. Para que una ABM sea científicamente significativa, tiene que ser construida y utilizada en cualquiera de los dos enfoques complementarios siguientes:
- Construir una ABM utilizando suposiciones modelo que se derivan de fenómenos empíricamente observados, y luego producir comportamientos colectivos previamente desconocidos por simulación.
- Construir un ABM usando supuestos hipotéticos de modelo, y luego reproducir fenómenos colectivos empíricamente observados mediante simulación.
La primera consiste en utilizar ABM para hacer predicciones utilizando teorías validadas de comportamientos de agentes, mientras que la segunda es para explorar y desarrollar nuevas explicaciones de fenómenos empíricamente observados. Estos dos enfoques son diferentes en cuanto a las escalas de lo conocido y lo desconocido (A usa micro-conocido para producir macro-desconocido, mientras que B usa micro-desconocido para reproducir macro-conocido), pero lo importante es que una de esas escalas debe basarse en un conocimiento empírico bien establecido. De lo contrario, los resultados de la simulación no tendrían implicaciones para el sistema del mundo real que se está modelando. Por supuesto, una exploración libre de diversas dinámicas colectivas probando comportamientos hipotéticos de agentes para generar resultados hipotéticos es bastante divertida y educativa, con muchos beneficios intelectuales propios. Mi punto es que no debemos malinterpretar los resultados obtenidos de tales ABM exploratorios como una predicción validada de la realidad.
Mientras tanto, los ítems 2, 3, 4 y 5 de la lista anterior de Macal y North están más enfocados en los aspectos técnicos del modelado. Se pueden traducir en las siguientes tareas de diseño en codificación real usando un lenguaje de programación como Python:
- Diseñar la estructura de datos para almacenar los atributos de los agentes.
- Diseñar la estructura de datos para almacenar los estados del entorno.
- Describir las reglas de cómo se comporta el medio ambiente por sí solo.
- Describir las reglas de cómo los agentes interactúan con el entorno.
- Describir las reglas de cómo se comportan los agentes por su cuenta.
- Describir las reglas de cómo los agentes interactúan entre sí.
Representación de agentes en Python
A menudo es conveniente y habitual definir los atributos y comportamientos de ambos agentes usando una clase en lenguajes de programación orientados a objetos, pero en este libro de texto, no cubriremos la programación orientada a objetos con mucho detalle. En su lugar, usaremos la clase dinámica de Python como una estructura de datos pura para almacenar los atributos de los agentes de una manera concisa. Por ejemplo, podemos definir una clase de agente vacía de la siguiente manera:

El comando class define una nueva clase bajo la cual se pueden definir diversos atributos (variables, propiedades) y métodos (funciones, acciones). En la programación convencional orientada a objetos, es necesario dar definiciones más específicas de atributos y métodos disponibles bajo esta clase. Pero en este libro de texto, seremos un poco perezosos y explotaremos la naturaleza dinámica y flexible de las clases de Python. Por lo tanto, acabamos de lanzar pass a la definición de clase anteriormente. pass es una palabra clave ficticia que no hace nada, pero todavía necesitamos algo ahí solo por razones sintácticas.
De todos modos, una vez definida esta clase de agente, puede crear un nuevo objeto agente vacío de la siguiente manera:

Luego puede agregar dinámicamente varios atributos a este objeto agente a:

Esta flexibilidad es muy similar a la fexibilidad del diccionario de Python. No es necesario predefinir atributos de un objeto Python. Al asignar un valor a un atributo (escrito como “nombre del objeto”. “atributo”), Python genera automáticamente un nuevo atributo si no se ha definido antes. Si quieres saber qué tipos de atributos están disponibles bajo un objeto, puedes usar el comando dir:

Los dos primeros atributos son los atributos predeterminados de Python que están disponibles para cualquier objeto (puedes ignorarlos por ahora). Aparte de esos, vemos que hay cuatro atributos definidos para este objeto a.
n el resto de este capítulo, utilizaremos esta representación de agente basada en clases. La arquitectura técnica de los códigos de simulador sigue siendo la misma que antes, compuesta por tres componentes: inicialización, visualización y funciones de actualización. Trabajemos en algunos ejemplos para ver cómo se puede construir un ABM en Python.
Modelo de segregación de Schelling
Hay un modelo perfecto para nuestro primer ejercicio ABM. Se llama modelo de segregación de Schelling, ampliamente conocido como el primer ABM propuesto a principios de la década de 1970 por Thomas Schelling, el Premio Nobel de Economía de 2005 [85]. Schelling creó este modelo para dar una explicación de por qué las personas con diferentes orígenes étnicos tienden a segregarse geográficamente. Por lo tanto, este modelo se desarrolló en el enfoque B discutido anteriormente, reproduciendo lo macro-conocido mediante el uso de micro-incógnitas hipotéticas. Los supuestos modelo utilizados por Schelling fueron los siguientes:
- Dos tipos diferentes de agentes se distribuyen en un espacio 2-D finito.
- En cada iteración, un agente elegido aleatoriamente mira alrededor de su vecindario, y si la fracción de agentes del mismo tipo entre sus vecinos está por debajo de un umbral, salta a otra ubicación elegida aleatoriamente en el espacio.
Como puedes ver, la regla de este modelo es sumamente sencilla. La principal pregunta que Schelling abordó con este modelo fue qué tan alto tenía que ser el umbral para que ocurriera la segregación. Puede sonar razonable suponer que la segregación requeriría agentes altamente homofílicos, por lo que el umbral crítico podría ser relativamente alto, digamos 80% más o menos. Pero lo que Schelling realmente mostró fue que el umbral crítico puede ser mucho más bajo de lo que uno esperaría. Esto significa que la segregación puede ocurrir aunque las personas no sean tan homófilas. Mientras tanto, bastante contrario a nuestra intuición, un alto nivel de homofilia puede resultar en realidad en un estado mixto de la sociedad porque los agentes siguen moviéndose sin llegar a un estado estacionario. Podemos observar estos comportamientos emergentes en simulaciones.
A principios de la década de 1970, Schelling simuló su modelo en papel cuadriculado usando centavos y cinco centavos como dos tipos de agentes (¡esto seguía siendo una simulación perfectamente computacional!). Pero aquí, podemos aflojar las restricciones espaciales y simular este modelo en un espacio continuo. Diseñemos el modelo de simulación paso a paso, pasando por las tareas de diseño enumeradas anteriormente.
1. Diseñar la estructura de datos para almacenar los atributos de los agentes. En este modelo, cada agente tiene un atributo type así como una posición en el espacio 2-D. Los dos tipos se pueden representar por 0 y 1, y la posición espacial puede estar en cualquier lugar dentro de una unidad cuadrada. Por lo tanto podemos generar cada agente de la siguiente manera:

Para generar una población de agentes, podemos escribir algo como:

2. Diseñar la estructura de datos para almacenar los estados del entorno, 3. Describir las reglas de cómo se comporta el medio ambiente por sí solo, & 4. Describir las reglas de cómo los agentes interactúan con el entorno. El modelo de Schelling no tiene un entorno separado que interactúe con los agentes, por lo que podemos omitir estas tareas de diseño.
5. Describir las reglas de cómo se comportan los agentes por su cuenta. Suponemos que los agentes no hacen nada por sí mismos, porque sus acciones (movimientos) son desencadenadas únicamente por interacciones con otros agentes. Así que también podemos ignorar esta tarea de diseño.
6. Describir las reglas de cómo los agentes interactúan entre sí. Por último, hay algo que tenemos que implementar. El supuesto modelo dice que cada agente comprueba quiénes están en su vecindario, y si la fracción de los otros agentes del mismo tipo es menor que un umbral, salta a otra ubicación seleccionada aleatoriamente. Esto requiere la detección de vecinos, lo cual fue fácil en CA y redes porque las relaciones de vecindad se modelaron explícitamente en esos marcos de modelado. Pero en ABM, las relaciones vecinales pueden estar implícitas, como es el caso de nuestro modelo. Por lo tanto, necesitamos implementar un código que permita a cada agente encontrar quién está cerca.
Existen varios algoritmos computacionalmente eficientes disponibles para la detección de vecinos, pero aquí utilizamos el método más simple posible: Búsqueda exhaustiva. Literalmente revisas a todos los agentes, uno por uno, para ver si están lo suficientemente cerca del agente focal. Esto no es computacionalmente eficiente (su cantidad computacional aumenta cuadráticamente a medida que aumenta el número de agentes), pero es muy sencillo y extremadamente fácil de implementar. Puede escribir una detección exhaustiva de vecinos usando la comprensión de listas de Python, por ejemplo:

Aquí ag es el agente focal cuyos vecinos son buscados. La parte if en la comprensión de la lista mide la distancia al cuadrado entre ag y nb, y si es menor que r al cuadrado (r es el radio de vecindad, que debe definirse anteriormente en el código) nb se incluye en el resultado. También tenga en cuenta que una condición adicional nb! = ag se da en la parte if. Esto se debe a que si nb == ag, la distancia es siempre 0 así que ag mismo se incluiría erróneamente como vecino de ag.
Una vez que obtenemos vecinos para ag, podemos calcular la fracción de los otros agentes cuyo tipo es el mismo que ag, y si es menor que un umbral dado, la posición de ag se restablece aleatoriamente. A continuación se muestra el código del simulador completado, con la función de visualización también implementada usando la función de trazado simple:




Cuando ejecutes este código, debes establecer el tamaño del paso en 50 debajo de la pestaña “Configuración” para acelerar las simulaciones.
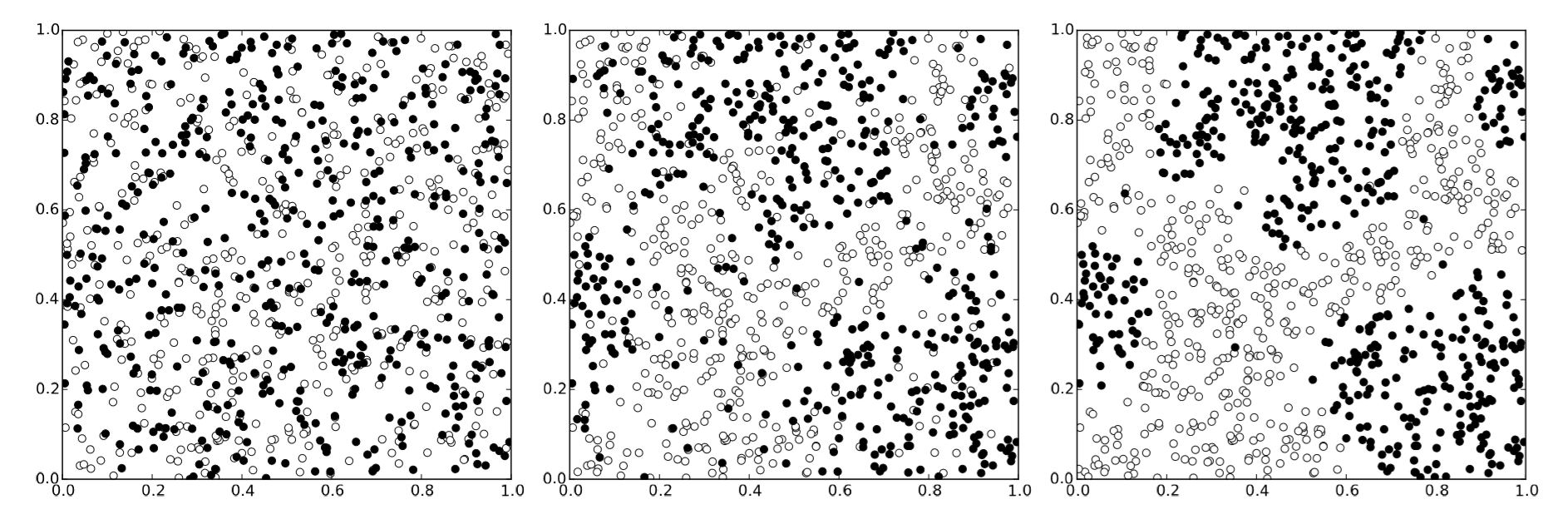
La Figura 19.2.1 muestra el resultado con el radio de vecindad r=0.1 y el umbral para mover th = 0.5. Se observa claramente que los agentes se autoorganizan desde una distribución inicialmente aleatoria hasta un patrón irregular donde los dos tipos están claramente segregados entre sí.
Realizar simulaciones del modelo de segregación de Schelling con th (umbral para movimiento), r (radio de vecindad) y/o n (tamaño de la población = densidad) variado sistemáticamente. Determinar la condición en la que se produce la segregación. ¿La transición es gradual o aguda?
Desarrollar una métrica que caracterice el nivel de segregación de las posiciones de los dos tipos de agentes. Luego grafica cómo cambia esta métrica a medida que se varían los valores de los parámetros.
Aquí hay algunos otros modelos conocidos que muestran patrones emergentes o comportamientos dinámicos bastante únicos. Se pueden implementar como ABM modificando el código para el modelo de segregación de Schelling. ¡Que te diviertas!
La agregación limitada por difusión (DLA) es un proceso de crecimiento de conglomerados de partículas agregadas impulsados por su difusión aleatoria. Hay dos tipos de partículas, como en el modelo de segregación de Schelling, pero sólo una de ellas puede moverse libremente. Las partículas móviles se difunden en un espacio 2-D por caminata aleatoria, mientras que las partículas inamovibles no hacen nada; simplemente permanecen donde están. Si una partícula móvil “choca” con una partícula inamovible (es decir, si se acercan lo suficiente entre sí), la partícula móvil se vuelve inamovible y permanece ahí para siempre. Esta es la única regla para la interacción de los agentes.
Implementar el código del simulador del modelo DLA. Realizar una simulación con todas las partículas inicialmente móviles, excepto una partícula inamovible de “semilla” colocada en el centro del espacio, y observar qué tipo de patrón espacial emerge. También realizar las simulaciones con múltiples semillas inamovibles colocadas aleatoriamente en el espacio, y observar cómo múltiples racimos interactúan entre sí a escalas macroscópicas.
Para su información, un código de simulador Python completo del modelo DLA está disponible en http://sourceforge.net/projects/pycx/files/, pero primero debe intentar implementar su propio código de simulador.
Este es un ejercicio bastante avanzado y desafiante sobre el comportamiento colectivo de grupos de animales, como flojos de aves, escuelas de peces y enjambres de insectos, que es un tema de investigación popular que ha sido ampliamente modelado y estudiado con ABM. Uno de los primeros modelos computacionales de tales comportamientos colectivos fue propuesto por el científico informático Craig Reynolds a fines de la década de 1980 [86]. A Reynolds se le ocurrió un conjunto de reglas de comportamiento simples para los agentes que se mueven en un espacio continuo que puede reproducir un comportamiento de flock increíblemente natural de las aves. Su modelo se llamaba aves-oides, o “Boids” para abreviar. Los algoritmos utilizados en Boids se han utilizado ampliamente en la industria de los gráficos por computadora para generar automáticamente animaciones de movimientos naturales de animales en flocks (por ejemplo, murciélagos en las películas de Batman). La dinámica de los Boids es generada por las siguientes tres reglas de comportamiento esenciales (Fig. 19.2.1):
- Los agentes de cohesión tienden a orientarse hacia el centro de masa de los vecinos locales.
- Los agentes de alineación tienden a orientarse para alinear sus direcciones con la velocidad promedio de los vecinos locales.
- Agentes de Separación tratan de evitar colisiones con vecinos locales.
Diseñar un ABM de comportamiento colectivo con estas tres reglas, e implementar su código de simulador. Realice simulaciones variando sistemáticamente las fortalezas relativas de las tres reglas anteriores, y vea cómo cambia el comportamiento colectivo.
También se puede simular el comportamiento colectivo de una población en la que se mezclan múltiples tipos de agentes. Se sabe que las interacciones entre tipos cinéticamente distintos de agentes de enjambre pueden producir diversos patrones dinámicos no triviales [87].
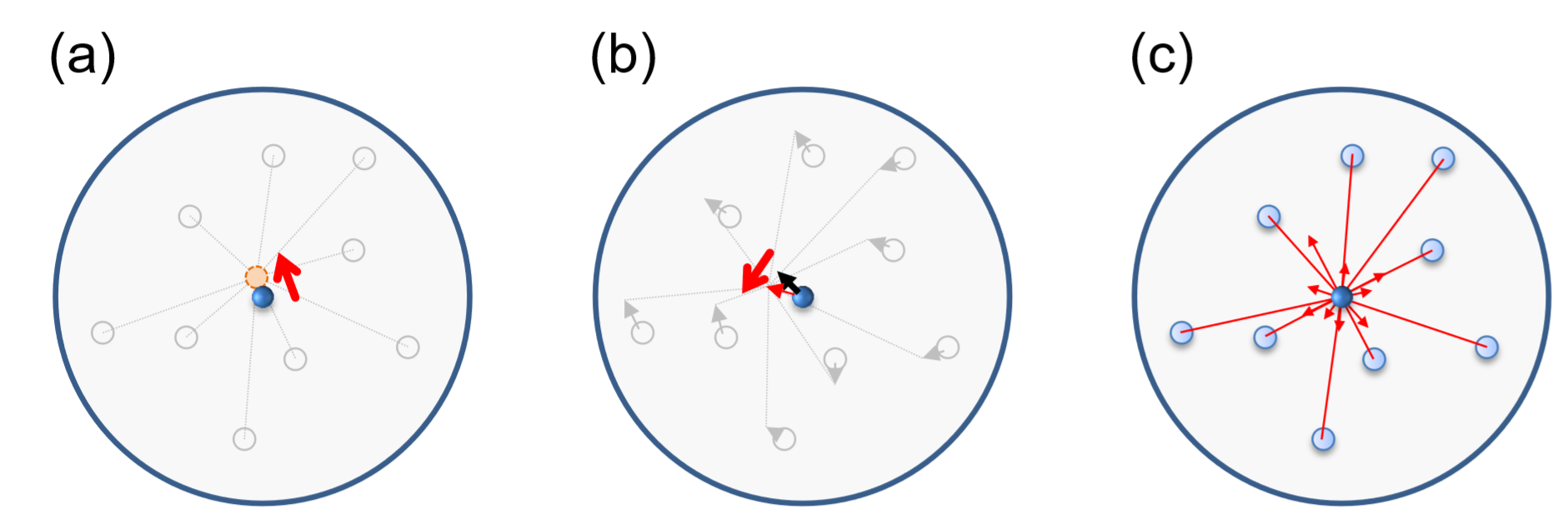 Figura19.2.2 Tres reglas conductuales esenciales de Boids. a) Cohesión. b) Alineación. c) Separación.
Figura19.2.2 Tres reglas conductuales esenciales de Boids. a) Cohesión. b) Alineación. c) Separación.