
5.3: El Teorema del Límite Central
- Page ID
- 69289

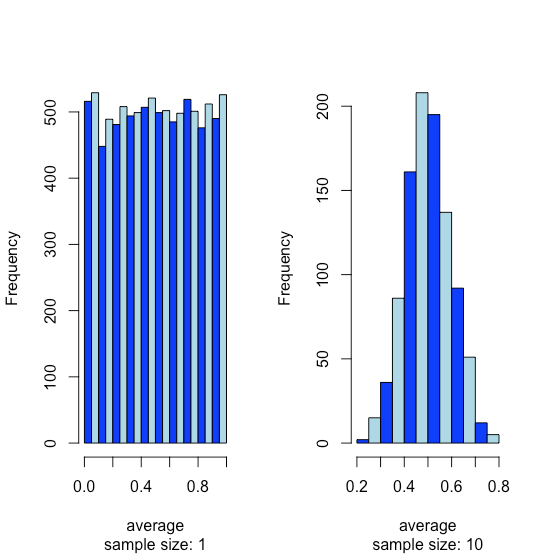
Supongamos que tenemos una población para la cual una de sus propiedades tiene una distribución uniforme donde cada resultado entre 0 y 1 es igualmente probable. Si analizamos 10,000 muestras no debemos sorprendernos al encontrar que la distribución de estos 10000 resultados se ve uniforme, como lo muestra el histograma del lado izquierdo de la Figura\(\PageIndex{1}\). Si recolectamos 1000 muestras agrupadas, cada una de las cuales consta de 10 muestras individuales para un total de 10,000 muestras individuales, y reportamos los resultados promedio para estas 1000 muestras agrupadas, vemos algo interesante ya que su distribución, como lo muestra el histograma de la derecha, se ve notablemente como una normal distribución. Cuando extraemos muestras individuales de una distribución uniforme, cada resultado posible es igualmente probable, por lo que vemos la distribución a la izquierda. Cuando dibujamos una muestra agrupada que consta de 10 muestras individuales, sin embargo, es más probable que los valores promedio estén cerca de la mitad del rango de la distribución, como vemos a la derecha, porque la muestra agrupada probablemente incluye valores extraídos tanto de la mitad inferior como de la mitad superior de la distribución uniforme .
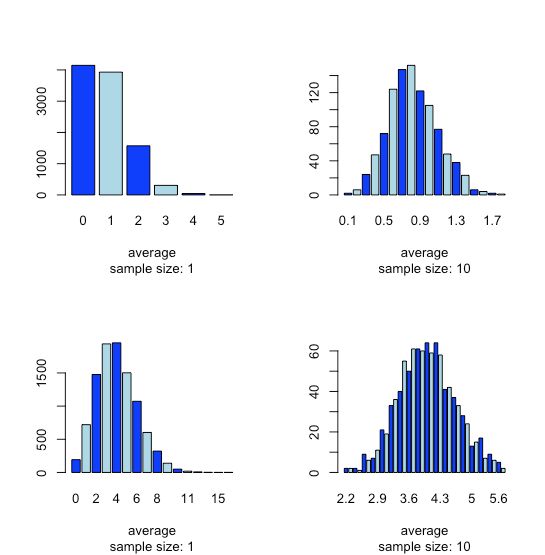
Esta tendencia a que surja una distribución normal cuando agrupamos muestras se conoce como el teorema del límite central. Como se muestra en la Figura\(\PageIndex{2}\), vemos un efecto similar con poblaciones que siguen una distribución binomial o una distribución de Poisson.
Podría preguntarse razonablemente si el teorema del límite central es importante ya que es poco probable que completemos 1000 análisis, cada uno de los cuales es el promedio de 10 ensayos individuales. Esto es engañoso. Cuando adquirimos una muestra de suelo, por ejemplo, consiste en muchas partículas individuales cada una de las cuales es una muestra individual del suelo. Nuestro análisis de esta muestra, por lo tanto, es la media para un gran número de partículas individuales de suelo. Debido a esto, el teorema del límite central es relevante.