8.1: Regresión lineal no ponderada con errores en y
- Page ID
- 69351
El método más común para completar una regresión lineal hace tres suposiciones:
- la diferencia entre nuestros datos experimentales y la línea de regresión calculada es el resultado de errores indeterminados que afectan a y
- cualquier error indeterminado que afecte y se distribuya normalmente
- que los errores indeterminados en y son independientes del valor de x
Debido a que asumimos que los errores indeterminados son los mismos para todos los estándares, cada estándar contribuye por igual en nuestra estimación de la pendiente y la intersección y. Por esta razón el resultado se considera una regresión lineal no ponderada.
El segundo supuesto generalmente es cierto debido al teorema del límite central, que consideramos en el Capítulo 5.3. La validez de los dos supuestos restantes es menos obvia y debes evaluarlos antes de aceptar los resultados de una regresión lineal. En particular la primera suposición siempre es sospechosa porque ciertamente hay algún error indeterminado en la medición de x. Cuando preparamos una curva de calibración, sin embargo, no es raro encontrar que la incertidumbre en la señal, S, es significativamente mayor que la incertidumbre en la concentración del analito,\(C_A\). En tales circunstancias el primer supuesto suele ser razonable.
Cómo funciona una regresión lineal
Para entender la lógica de una regresión lineal consideremos el ejemplo de la Figura\(\PageIndex{1}\), que muestra tres puntos de datos y dos posibles líneas rectas que podrían explicar razonablemente los datos. ¿Cómo decidimos qué tan bien estas líneas rectas se ajustan a los datos y cómo determinamos cuál, si alguna, es la mejor línea recta?
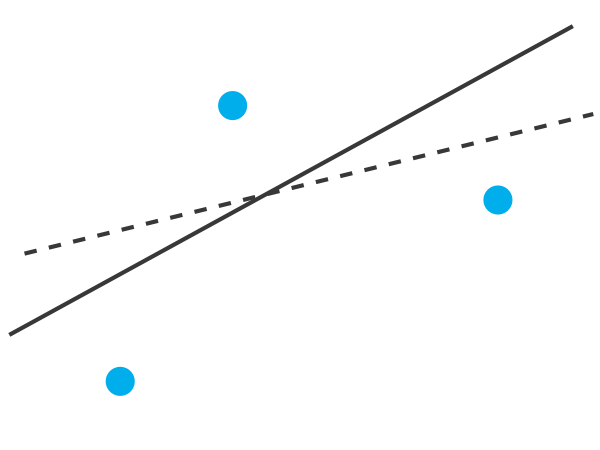
Centrémonos en la línea sólida de la Figura\(\PageIndex{1}\). La ecuación para esta línea es
\[\hat{y} = b_0 + b_1 x \nonumber \]
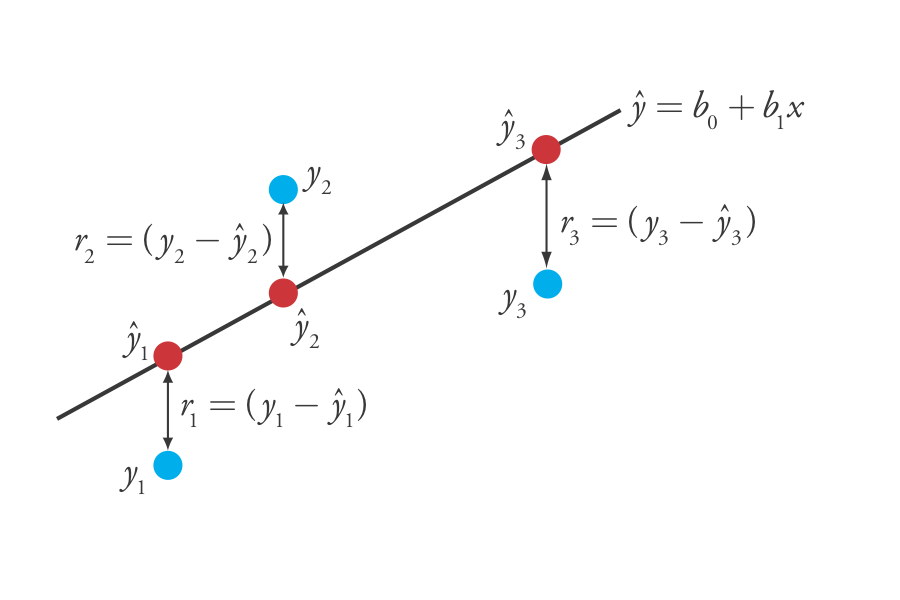
donde b 0 y b 1 son estimaciones para la intersección y y la pendiente, y\(\hat{y}\) es el valor predicho de y para cualquier valor de x. Porque suponemos que toda incertidumbre es el resultado de errores indeterminados en y, la diferencia entre y y\(\hat{y}\) para cada valor de x es el error residual, r, en nuestro modelo matemático.
\[r_i = (y_i - \hat{y}_i) \nonumber\]
La figura\(\PageIndex{2}\) muestra los errores residuales para los tres puntos de datos. Cuanto menor sea el error residual total, R, que definimos como
\[R = \sum_{i = 1}^{n} (y_i - \hat{y}_i)^2 \nonumber \]
mejor es el ajuste entre la línea recta y los datos. En un análisis de regresión lineal, buscamos valores de b 0 y b 1 que den el menor error residual total.
La razón para cuadrar los errores residuales individuales es evitar que un error residual positivo cancele un error residual negativo. Esto lo ha visto antes en las ecuaciones para las desviaciones estándar muestrales y poblacionales introducidas en el Capítulo 4. También se puede ver a partir de esta ecuación por qué a una regresión lineal se le llama a veces el método de mínimos cuadrados.
Encontrar la pendiente y la intersección y para el modelo de regresión
Aunque no desarrollaremos formalmente las ecuaciones matemáticas para un análisis de regresión lineal, se pueden encontrar las derivaciones en muchos textos estadísticos estándar [Véase, por ejemplo, Draper, N. R.; Smith, H. Applied Regression Analysis, 3a ed.; Wiley: New York, 1998]. La ecuación resultante para la pendiente, b 1, es
\[b_1 = \frac {n \sum_{i = 1}^{n} x_i y_i - \sum_{i = 1}^{n} x_i \sum_{i = 1}^{n} y_i} {n \sum_{i = 1}^{n} x_i^2 - \left( \sum_{i = 1}^{n} x_i \right)^2} \nonumber \]
y la ecuación para la intersección y, b 0, es
\[b_0 = \frac {\sum_{i = 1}^{n} y_i - b_1 \sum_{i = 1}^{n} x_i} {n} \nonumber \]
Aunque estas ecuaciones parecen formidables, sólo es necesario evaluar las siguientes cuatro sumas
\[\sum_{i = 1}^{n} x_i \quad \sum_{i = 1}^{n} y_i \quad \sum_{i = 1}^{n} x_i y_i \quad \sum_{i = 1}^{n} x_i^2 \nonumber\]
Muchas calculadoras, hojas de cálculo y otros paquetes de software estadístico son capaces de realizar un análisis de regresión lineal basado en este modelo; consulte la Sección 8.5 para obtener detalles sobre cómo completar un análisis de regresión lineal usando R. Para fines ilustrativos, los cálculos necesarios se muestran en detalle en la siguiente ejemplo.
Utilizando los datos de calibración de la siguiente tabla, se determina la relación entre la señal\(y_i\), y la concentración del analito\(x_i\), utilizando una regresión lineal no ponderada.
Solución
Comenzamos configurando una tabla que nos ayude a organizar el cálculo.
| \(x_i\) | \(y_i\) | \(x_i y_i\) | \(x_i^2\) |
|---|---|---|---|
| \ (x_i\) ">0.000 | \ (y_i\) ">0.00 | \ (x_i y_i\) ">0.000 | \ (x_i^2\) ">0.000 |
| \ (x_i\) ">0.100 | \ (y_i\) ">12.36 | \ (x_i y_i\) ">1.236 | \ (x_i^2\) ">0.010 |
| \ (x_i\) ">0.200 | \ (y_i\) ">24.83 | \ (x_i y_i\) ">4.966 | \ (x_i^2\) ">0.040 |
| \ (x_i\) ">0.300 | \ (y_i\) ">35.91 | \ (x_i y_i\) ">10.773 | \ (x_i^2\) ">0.090 |
| \ (x_i\) ">0.400 | \ (y_i\) ">48.79 | \ (x_i y_i\) ">19.516 | \ (x_i^2\) ">0.160 |
| \ (x_i\) ">0.500 | \ (y_i\) ">60.42 | \ (x_i y_i\) ">30.210 | \ (x_i^2\) ">0.250 |
Sumando los valores en cada columna da
\[\sum_{i = 1}^{n} x_i = 1.500 \quad \sum_{i = 1}^{n} y_i = 182.31 \quad \sum_{i = 1}^{n} x_i y_i = 66.701 \quad \sum_{i = 1}^{n} x_i^2 = 0.550 \nonumber\]
Sustituyendo estos valores en las ecuaciones para la pendiente y la intersección y da
\[b_1 = \frac {(6 \times 66.701) - (1.500 \times 182.31)} {(6 \times 0.550) - (1.500)^2} = 120.706 \approx 120.71 \nonumber\]
\[b_0 = \frac {182.31 - (120.706 \times 1.500)} {6} = 0.209 \approx 0.21 \nonumber\]
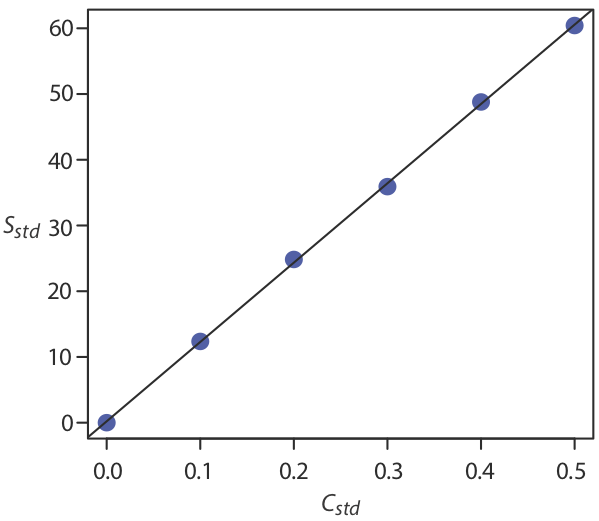
La relación entre la señal,\(S\), y la concentración del analito\(C_A\), por lo tanto, es
\[S = 120.71 \times C_A + 0.21 \nonumber\]
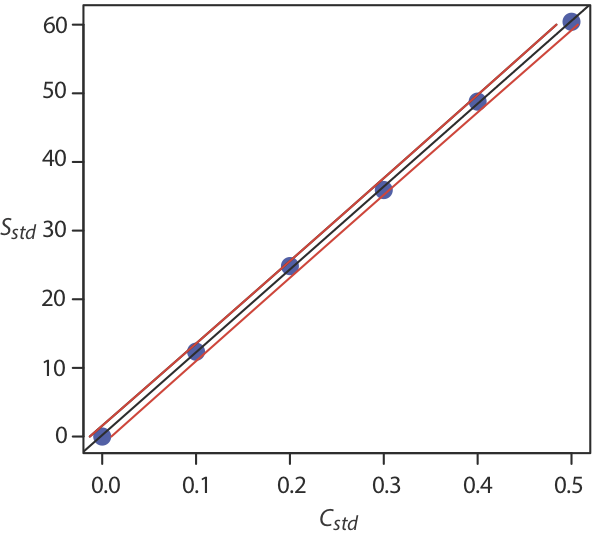
Por ahora mantenemos dos decimales para que coincidan con el número de decimales en la señal. La curva de calibración resultante se muestra en la Figura\(\PageIndex{3}\).
Incertidumbre en el modelo de regresión
Como vemos en la Figura\(\PageIndex{3}\), debido a errores indeterminados en la señal, la línea de regresión no pasa por el centro exacto de cada punto de datos. La desviación acumulada de nuestros datos de la línea de regresión —el error residual total— es proporcional a la incertidumbre en la regresión. Llamamos a esta incertidumbre la desviación estándar sobre la regresión, s r, que es igual a
\[s_r = \sqrt{\frac {\sum_{i = 1}^{n} \left( y_i - \hat{y}_i \right)^2} {n - 2}} \nonumber \]
donde y i es el i-ésimo valor experimental, y\(\hat{y}_i\) es el valor correspondiente predicho por la ecuación de regresión\(\hat{y} = b_0 + b_1 x\). Tenga en cuenta que el denominador indica que nuestro análisis de regresión tiene n — 2 grados de libertad — perdemos dos grados de libertad porque utilizamos dos parámetros, la pendiente y la intersección y, para calcular\(\hat{y}_i\).
Una representación más útil de la incertidumbre en nuestro análisis de regresión es considerar el efecto de errores indeterminados en la pendiente, b 1, y la intersección y, b 0, que expresamos como desviaciones estándar.
\[s_{b_1} = \sqrt{\frac {n s_r^2} {n \sum_{i = 1}^{n} x_i^2 - \left( \sum_{i = 1}^{n} x_i \right)^2}} = \sqrt{\frac {s_r^2} {\sum_{i = 1}^{n} \left( x_i - \overline{x} \right)^2}} \nonumber \]
\[s_{b_0} = \sqrt{\frac {s_r^2 \sum_{i = 1}^{n} x_i^2} {n \sum_{i = 1}^{n} x_i^2 - \left( \sum_{i = 1}^{n} x_i \right)^2}} = \sqrt{\frac {s_r^2 \sum_{i = 1}^{n} x_i^2} {n \sum_{i = 1}^{n} \left( x_i - \overline{x} \right)^2}} \nonumber \]
Utilizamos estas desviaciones estándar para establecer intervalos de confianza para la pendiente esperada\(\beta_1\), y la intersección y esperada,\(\beta_0\)
\[\beta_1 = b_1 \pm t s_{b_1} \nonumber \]
\[\beta_0 = b_0 \pm t s_{b_0} \nonumber \]
donde seleccionamos t para un nivel de significancia de\(\alpha\) y para n — 2 grados de libertad. Tenga en cuenta que estas ecuaciones no contienen el factor de\((\sqrt{n})^{-1}\) visto en los intervalos de confianza para\(\mu\) en el Capítulo 6.2; esto se debe a que el intervalo de confianza aquí se basa en una sola línea de regresión.
Calcular los intervalos de confianza del 95% para la pendiente y -intercepción a partir del Ejemplo\(\PageIndex{1}\).
Solución
Comenzamos calculando la desviación estándar sobre la regresión. Para ello debemos calcular las señales predichas,\(\hat{y}_i\), utilizando la pendiente y la intersección y del Ejemplo\(\PageIndex{1}\), y los cuadrados del error residual,\((y_i - \hat{y}_i)^2\). Usando el último estándar como ejemplo, encontramos que la señal predicha es
\[\hat{y}_6 = b_0 + b_1 x_6 = 0.209 + (120.706 \times 0.500) = 60.562 \nonumber\]
y que el cuadrado del error residual es
\[(y_i - \hat{y}_i)^2 = (60.42 - 60.562)^2 = 0.2016 \approx 0.202 \nonumber\]
En la siguiente tabla se muestran los resultados de las seis soluciones.
| \(x_i\) | \(y_i\) | \(\hat{y}_i\) |
\(\left( y_i - \hat{y}_i \right)^2\) |
|---|---|---|---|
| \ (x_i\) ">0.000 | \ (y_i\) ">0.00 | \ (\ hat {y} _i\) ">0.209 | \ (\ izquierda (y_i -\ hat {y} _i\ derecha) ^2\) ">0.0437 |
| \ (x_i\) ">0.100 | \ (y_i\) ">12.36 | \ (\ hat {y} _i\) ">12.280 | \ (\ izquierda (y_i -\ hat {y} _i\ derecha) ^2\) ">0.0064 |
| \ (x_i\) ">0.200 | \ (y_i\) ">24.83 | \ (\ hat {y} _i\) ">24.350 | \ (\ izquierda (y_i -\ hat {y} _i\ derecha) ^2\) ">0.2304 |
| \ (x_i\) ">0.300 | \ (y_i\) ">35.91 | \ (\ hat {y} _i\) ">36.421 | \ (\ izquierda (y_i -\ hat {y} _i\ derecha) ^2\) ">0.2611 |
| \ (x_i\) ">0.400 | \ (y_i\) ">48.79 | \ (\ hat {y} _i\) ">48.491 | \ (\ izquierda (y_i -\ hat {y} _i\ derecha) ^2\) ">0.0894 |
| \ (x_i\) ">0.500 | \ (y_i\) ">60.42 | \ (\ hat {y} _i\) ">60.562 | \ (\ izquierda (y_i -\ hat {y} _i\ derecha) ^2\) ">0.0202 |
Al sumar los datos de la última columna se obtiene el numerador en la ecuación para la desviación estándar sobre la regresión; así
\[s_r = \sqrt{\frac {0.6512} {6 - 2}} = 0.4035 \nonumber\]
A continuación calculamos las desviaciones estándar para la pendiente y la intersección y. Los valores para los términos de suma son de Ejemplo\(\PageIndex{1}\).
\[s_{b_1} = \sqrt{\frac {6 \times (0.4035)^2} {(6 \times 0.550) - (1.500)^2}} = 0.965 \nonumber\]
\[s_{b_0} = \sqrt{\frac {(0.4035)^2 \times 0.550} {(6 \times 0.550) - (1.500)^2}} = 0.292 \nonumber\]
Finalmente, los intervalos de confianza del 95% (\(\alpha = 0.05\), 4 grados de libertad) para la pendiente y la intersección y son
\[\beta_1 = b_1 \pm ts_{b_1} = 120.706 \pm (2.78 \times 0.965) = 120.7 \pm 2.7 \nonumber\]
\[\beta_0 = b_0 \pm ts_{b_0} = 0.209 \pm (2.78 \times 0.292) = 0.2 \pm 0.80 \nonumber\]
donde t (0.05, 4) del Apéndice 2 es 2.78. La desviación estándar sobre la regresión, s r, sugiere que la señal, S std, es precisa a un lugar decimal. Por esta razón reportamos la pendiente y la intersección y a un solo decimal.
Uso del modelo de regresión para determinar un valor para x Dado un valor para y
Una vez que tenemos nuestra ecuación de regresión, es fácil determinar la concentración de analito en una muestra. Cuando usamos una curva de calibración normal, por ejemplo, medimos la señal para nuestra muestra, S samp, y calculamos la concentración del analito, C A, usando la ecuación de regresión.
\[C_A = \frac {S_{samp} - b_0} {b_1} \nonumber \]
Lo menos obvio es cómo reportar un intervalo de confianza para C A que exprese la incertidumbre en nuestro análisis. Para calcular un intervalo de confianza necesitamos conocer la desviación estándar en la concentración del analito\(s_{C_A}\), que viene dada por la siguiente ecuación
\[s_{C_A} = \frac {s_r} {b_1} \sqrt{\frac {1} {m} + \frac {1} {n} + \frac {\left( \overline{S}_{samp} - \overline{S}_{std} \right)^2} {(b_1)^2 \sum_{i = 1}^{n} \left( C_{std_i} - \overline{C}_{std} \right)^2}} \nonumber\]
donde m es el número de réplicas que utilizamos para establecer la señal promedio de la muestra, S samp, n es el número de estándares de calibración, S std es la señal promedio para la calibración estándares, y\(C_{std_i}\) y\(\overline{C}_{std}\) son las concentraciones individuales y medias para los estándares de calibración. Conociendo el valor de\(s_{C_A}\), el intervalo de confianza para la concentración del analito es
\[\mu_{C_A} = C_A \pm t s_{C_A} \nonumber\]
donde\(\mu_{C_A}\) está el valor esperado de C A en ausencia de errores determinados, y con el valor de t se basa en el nivel de confianza deseado y n — 2 grados de libertad.
Un examen minucioso de estas ecuaciones debería convencerle de que podemos disminuir la incertidumbre en la concentración predicha de analito,\(C_A\) si aumentamos el número de estándares\(n\),, aumentar el número de muestras replicadas que analizamos,\(m\), y si la señal promedio de la muestra, \(\overline{S}_{samp}\), es igual a la señal promedio para los estándares,\(\overline{S}_{std}\). Cuando sea práctico, debe planificar su curva de calibración para que S samp caiga en el medio de la curva de calibración. Para mayor información sobre estas ecuaciones de regresión ver (a) Miller, J. N. Analyst 1991, 116, 3—14; (b) Sharaf, M. A.; Illman, D. L.; Kowalski, B. R. Chemometrics, Wiley-Interscience: New York, 1986, pp. 126-127; (c) Analytical Methods Committee” Incertidumbres en las concentraciones estimadas a partir de experimentos de calibración”, Informe Técnico de AMC, marzo de 2006.
La ecuación para la desviación estándar en la concentración del analito se escribe en términos de un experimento de calibración. Aquí se da una forma más general de la ecuación, escrita en términos de x e y.
\[s_{x} = \frac {s_r} {b_1} \sqrt{\frac {1} {m} + \frac {1} {n} + \frac {\left( \overline{Y} - \overline{y} \right)^2} {(b_1)^2 \sum_{i = 1}^{n} \left( x_i - \overline{x} \right)^2}} \nonumber\]
Tres análisis replicados para una muestra que contiene una concentración desconocida de analito, arroja valores para S samp de 29.32, 29.16 y 29.51 (unidades arbitrarias). Usando los resultados de Ejemplo\(\PageIndex{1}\) y Ejemplo\(\PageIndex{2}\), determinar la concentración del analito, C A, y su intervalo de confianza del 95%.
Solución
La señal promedio,\(\overline{S}_{samp}\), es 29.33, que, usando la pendiente y la intersección y del Ejemplo\(\PageIndex{1}\), da la concentración del analito como
\[C_A = \frac {\overline{S}_{samp} - b_0} {b_1} = \frac {29.33 - 0.209} {120.706} = 0.241 \nonumber\]
Para calcular la desviación estándar para la concentración del analito debemos determinar los valores para\(\overline{S}_{std}\) y para\(\sum_{i = 1}^{2} (C_{std_i} - \overline{C}_{std})^2\). El primero es solo la señal promedio para los estándares de calibración, que, utilizando los datos de la Tabla\(\PageIndex{1}\), es de 30.385. El cálculo\(\sum_{i = 1}^{2} (C_{std_i} - \overline{C}_{std})^2\) parece formidable, pero podemos simplificar su cálculo reconociendo que esta suma de cuadrados es el numerador en una ecuación de desviación estándar; así,
\[\sum_{i = 1}^{n} (C_{std_i} - \overline{C}_{std})^2 = (s_{C_{std}})^2 \times (n - 1) \nonumber\]
donde\(s_{C_{std}}\) está la desviación estándar para la concentración de analito en los estándares de calibración. Usando los datos de la Tabla\(\PageIndex{1}\) encontramos que\(s_{C_{std}}\) es 0.1871 y
\[\sum_{i = 1}^{n} (C_{std_i} - \overline{C}_{std})^2 = (0.1872)^2 \times (6 - 1) = 0.175 \nonumber\]
Sustituir valores conocidos en la ecuación para\(s_{C_A}\) da
\[s_{C_A} = \frac {0.4035} {120.706} \sqrt{\frac {1} {3} + \frac {1} {6} + \frac {(29.33 - 30.385)^2} {(120.706)^2 \times 0.175}} = 0.0024 \nonumber\]
Finalmente, el intervalo de confianza del 95% para 4 grados de libertad es
\[\mu_{C_A} = C_A \pm ts_{C_A} = 0.241 \pm (2.78 \times 0.0024) = 0.241 \pm 0.007 \nonumber\]
En la figura se\(\PageIndex{4}\) muestra la curva de calibración con curvas que muestran el intervalo de confianza del 95% para C A.
Evaluación de un modelo de regresión
Nunca se debe aceptar el resultado de un análisis de regresión lineal sin evaluar la validez del modelo. Quizás la forma más sencilla de evaluar un análisis de regresión es examinar los errores residuales. Como vimos anteriormente, el error residual para un único estándar de calibración, r i, es
\[r_i = (y_i - \hat{y}_i) \nonumber\]
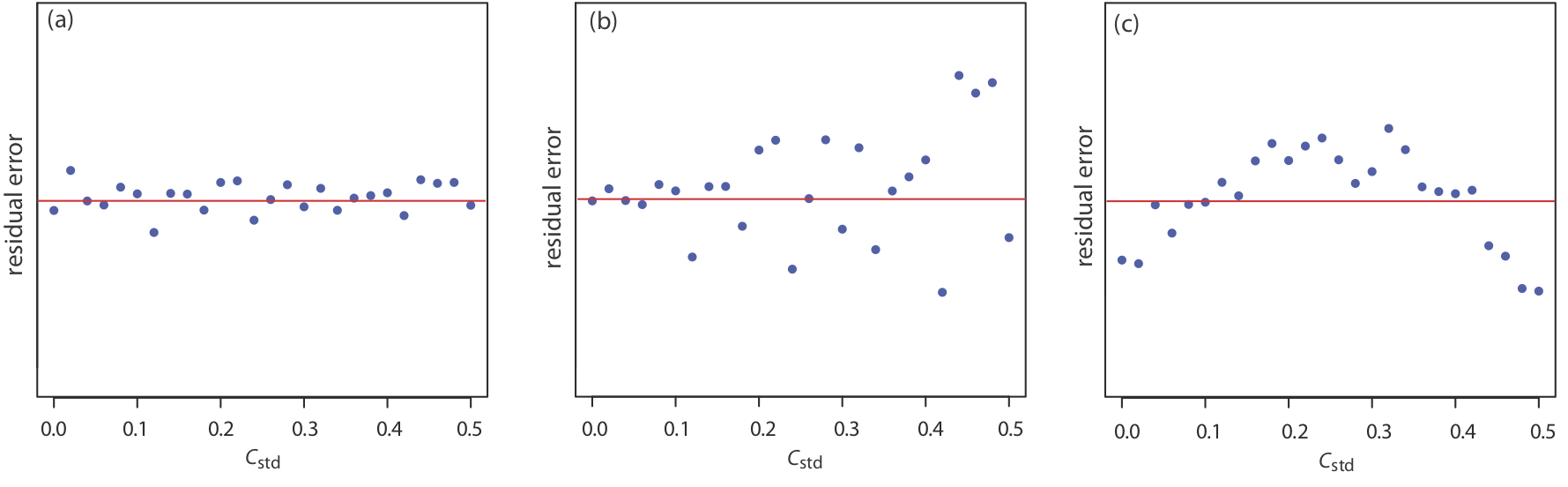
Si el modelo de regresión es válido, entonces los errores residuales deben distribuirse aleatoriamente alrededor de un error residual promedio de cero, sin tendencia aparente hacia errores residuales menores o mayores (Figura\(\PageIndex{5a}\)). Tendencias como las de Figura\(\PageIndex{5b}\) y Figura\(\PageIndex{5c}\) proporcionan evidencia de que al menos uno de los supuestos del modelo es incorrecto. Por ejemplo, una tendencia hacia errores residuales mayores a concentraciones más altas, Figura\(\PageIndex{5b}\), sugiere que los errores indeterminados que afectan a la señal no son independientes de la concentración del analito. En la Figura\(\PageIndex{5c}\), los errores residuales no son aleatorios, lo que sugiere que no podemos modelar los datos usando una relación de línea recta. Los métodos de regresión para estos dos últimos casos se discuten en las siguientes secciones.
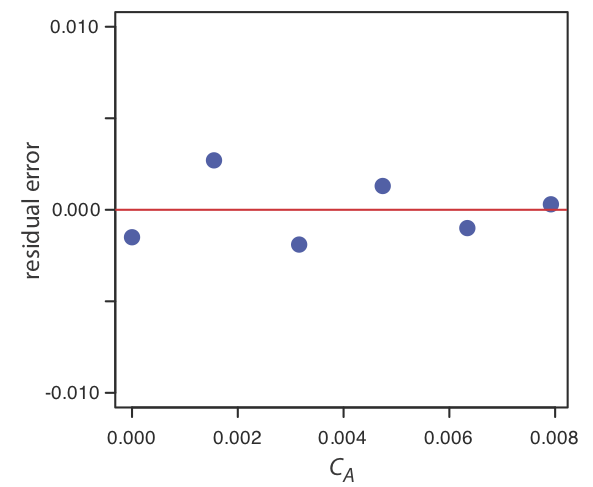
Usa tus resultados de Ejercicio\(\PageIndex{1}\) para construir una parcela residual y explicar su significado.
Solución
Para crear una gráfica residual, necesitamos calcular el error residual para cada estándar. La siguiente tabla contiene la información relevante.
| \(x_i\) | \(y_i\) | \(\hat{y}_i\) | \(y_i - \hat{y}_i\) |
|---|---|---|---|
| \ (x_i\) ">0.000 | \ (y_i\) ">0.000 | \ (\ hat {y} _i\) ">0.0015 | \ (y_i -\ hat {y} _i\) ">—0.0015 |
| \ (x_i\) ">\(1.55 \times 10^{-3}\) | \ (y_i\) ">0.050 | \ (\ hat {y} _i\) ">0.0473 | \ (y_i -\ hat {y} _i\) ">0.0027 |
| \ (x_i\) ">\(3.16 \times 10^{-3}\) | \ (y_i\) ">0.093 | \ (\ hat {y} _i\) ">0.0949 | \ (y_i -\ hat {y} _i\) ">—0.0019 |
| \ (x_i\) ">\(4.74 \times 10^{-3}\) | \ (y_i\) ">0.143 | \ (\ hat {y} _i\) ">0.1417 | \ (y_i -\ hat {y} _i\) ">0.0013 |
| \ (x_i\) ">\(6.34 \times 10^{-3}\) | \ (y_i\) ">0.188 | \ (\ hat {y} _i\) ">0.1890 | \ (y_i -\ hat {y} _i\) ">—0.0010 |
| \ (x_i\) ">\(7.92 \times 10^{-3}\) | \ (y_i\) ">0.236 | \ (\ hat {y} _i\) ">0.2357 | \ (y_i -\ hat {y} _i\) ">0.0003 |
La siguiente figura muestra una gráfica de los errores residuales resultantes. Los errores residuales aparecen aleatorios, aunque sí alternan en signo, y no muestran ninguna dependencia significativa de la concentración del analito. En conjunto, estas observaciones sugieren que nuestro modelo de regresión es apropiado.