
3.4: Confiabilidad de una medición
- Page ID
- 70981

- Explicar la distinción entre el valor medio de una serie de mediciones y la media poblacional.
- ¿Qué cantidad además del valor medio necesitamos para evaluar la calidad de una serie de mediciones?
- Explicar el significado y significado de la dispersión de la media, y declarar qué factor la controla.
- Explicar la distinción entre error determinado e indeterminado.
- Describir el proceso de propósito del uso de una pieza en bruto y el valor de control al realizar una serie de mediciones. ¿Qué suposición principal debe hacerse al hacer esto?
En este día de medios generalizados, continuamente estamos siendo bombardeados con datos de todo tipo: encuestas de opinión pública, publicidad exagerada, informes gubernamentales y declaraciones de políticos. Muy a menudo, los proveedores de esta información esperan “vendernos” un producto, una idea o una forma de pensar en alguien o algo así, y al hacerlo, con demasiada frecuencia están dispuestos a aprovechar la incapacidad de la persona promedio para emitir juicios informados sobre la confiabilidad de los datos, especialmente cuando se presenta en un contexto particular (conocido popularmente como “spin”). En Ciencia, no tenemos esta opción: recolectamos datos y hacemos mediciones para acercarnos a cualquier “verdad” que estemos buscando, pero no es realmente “ciencia” hasta que otros puedan tener confianza en la confiabilidad de nuestras mediciones.
Atributos de una medición
Los tipos de mediciones que trataremos aquí son aquellas en las que se realizan una serie de observaciones separadas sobre muestras individuales tomadas de una población mayor.
Población, cuando se utiliza en un contexto estadístico, no necesariamente se refiere a las personas, sino más bien al conjunto de todos los miembros del grupo de objetos en consideración.
Por ejemplo, es posible que desee determinar la cantidad de nicotina en una serie de fabricación de un millón de cigarrillos. Debido a que no es probable que dos cigarrillos sean exactamente idénticos, e incluso si lo fueran, un error aleatorio provocaría que cada análisis arrojara un resultado diferente, lo mejor que puedes hacer sería probar una muestra representativa de, digamos, veinte a cien cigarrillos. Se toma el promedio (media) de estos valores, y luego se enfrenta a la necesidad de estimar qué tan cerca es probable que esta media de la muestra se aproxime a la media poblacional. Este último es el “valor verdadero” que nunca podremos conocer; lo que podemos hacer, sin embargo, es hacer una estimación razonable de la probabilidad de que la media muestral no difiera de la media poblacional en más de una cierta cantidad.
Los atributos que podemos asignar a un conjunto individual de medidas de alguna cantidad x dentro de una población se enumeran a continuación. Es importante que aprendas el significado de estos términos:
Número de medidas
Esta cantidad suele estar representada por n.
Media
El valor medio x m (comúnmente conocido como el promedio), definido como
Mediana
El valor mediano, del que no trataremos en esta breve presentación, es esencialmente el que se encuentra en medio de la lista resultante de escribir los valores individuales en orden de magnitud creciente o decreciente.
Rango
El rango es la diferencia entre el valor más grande y el más pequeño del conjunto.
Ejemplo de problema:
Encuentre el valor medio y el rango del conjunto de medidas que se muestran aquí.
Solución: Este conjunto contiene 8 medidas. El rango es
(10.7 — 10.3) = 0.4, y el valor medio es
6 Más de una respuesta: dispersión de la media
“Dispersión” significa “amplitud de salida”. Si haces algunas medidas y las promedias, obtienes un cierto valor para la media. Pero si haces otro conjunto de medidas, la media de estas probablemente será diferente. Cuanto mayor sea la diferencia entre las medias, mayor es su dispersión.
Supongamos que en lugar de tomar las cinco medidas como en el ejemplo anterior, solo habíamos hecho dos observaciones que, por casualidad, arrojaron los valores que aquí se resaltan. Esto daría como resultado una media muestral de 10.45. Por supuesto, cualquier número de otros pares de valores podría haberse observado igualmente bien, incluyendo múltiples ocurrencias de cualquier valor único, como 10.6.
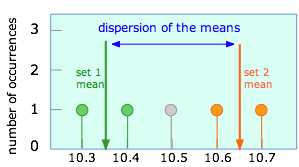 A la izquierda se muestran los resultados de dos posibles pares de observaciones, cada una dando lugar a su propia media muestral. Suponiendo que todas las observaciones están sujetas solo a errores aleatorios, es fácil ver que pares sucesivos de experimentos podrían producir muchas otras medias de muestra. El rango de posibles medias de muestra se conoce como dispersión de la media.
A la izquierda se muestran los resultados de dos posibles pares de observaciones, cada una dando lugar a su propia media muestral. Suponiendo que todas las observaciones están sujetas solo a errores aleatorios, es fácil ver que pares sucesivos de experimentos podrían producir muchas otras medias de muestra. El rango de posibles medias de muestra se conoce como dispersión de la media.
Es evidente que ambas medias muestrales no pueden corresponder a la media poblacional, cuyo valor realmente estamos tratando de descubrir. De hecho, es muy probable que ninguna de las medias muestrales sea la “correcta” en este sentido. Es un principio fundamental de la estadística, sin embargo, que cuantas más observaciones hagamos para obtener una media muestral, menor será la dispersión de las medias muestrales que resultan de conjuntos repetidos del mismo número de observaciones. (Esto es importante; ¡por favor lea la oración anterior al menos tres veces para asegurarse de que la entiende!)
Cómo depende la dispersión de la media del número de observaciones
La diferencia entre la media muestral (azul) y la media poblacional (el “valor verdadero”, verde) es el error de la medición. Es claro que este error disminuye a medida que se hace mayor el número de observaciones.
Lo que se ha dicho anteriormente es solo otra forma de decir lo que probablemente ya sepa: muestras más grandes producen resultados más confiables. Este es el mismo principio que nos dice que voltear una moneda 100 veces será más probable que arroje una relación 50:50 de cabeza a cola de lo que se encontrará si solo se hacen diez volteretas (observaciones).
La razón de esta relación inversa entre el tamaño de la muestra y la dispersión de la media es que si los factores que dan lugar a los diferentes valores observados son verdaderamente aleatorios, entonces cuantas más muestras observemos, más probablemente se cancelen estos errores. Resulta que si los errores son verdaderamente aleatorios, entonces a medida que traza el número de ocurrencias de cada valor, los resultados comienzan a trazar un tipo de curva muy especial.
La significación de esto es mucho mayor de lo que se podría pensar al principio, porque la curva G aussiana tiene propiedades matemáticas especiales que podemos explotar, a través de los métodos de la estadística, para obtener alguna información muy útil sobre la confiabilidad de nuestros datos. Este será el tema principal de la siguiente lección en este conjunto.
Por ahora, sin embargo, necesitamos establecer algunos principios importantes con respecto al error de medición.
7 Error sistemático
La dispersión en los resultados medidos que hemos estado discutiendo surge de variaciones aleatorias en la miríada de eventos que afectan el valor observado, y sobre los cuales el experimentador no tiene o solo tiene un control limitado. Si estamos tratando de determinar las propiedades de una colección de objetos (el contenido de nicotina de los cigarrillos o la vida útil de las bombillas de las lámparas), entonces las variaciones aleatorias entre miembros individuales de la población son un factor siempre presente. Este tipo de error se denomina error aleatorio o indeterminado, y es el único tipo con el que podemos tratar directamente por medio de estadísticas.
Sin embargo, existe otro tipo de error que puede afectar al proceso de medición. Se le conoce como error sistemático o determinado, y su efecto es desplazar un conjunto completo de puntos de datos en una cantidad constante. El error sistemático, a diferencia del error aleatorio, no es aparente en los datos en sí, y debe buscarse explícitamente en el diseño del experimento.
Una fuente común de error sistemático es no utilizar una escala de medición confiable o malinterpretar una escala. Por ejemplo, podrías estar midiendo la longitud de un objeto con una regla cuyo extremo izquierdo está desgastado, o podrías malleer el volumen de líquido en una bureta mirando la parte superior del menisco en lugar de en su parte inferior, o no tener el nivel de los ojos con el objeto que se ve contra la escala, introduciendo así error de paralaje.
8 Blanks y controles
Muchos tipos de mediciones son realizadas por dispositivos que producen una respuesta de algún tipo (a menudo una corriente eléctrica) que es directamente proporcional a la cantidad que se mide. Por ejemplo, podrías determinar la cantidad de hierro disuelto en una solución agregando un reactivo que reaccione con el hierro para darle un color rojo, el cual mide observando la intensidad de la luz verde que pasa por un grosor fijo de la solución. En un caso como este, es una práctica común realizar dos tipos adicionales de mediciones:
Una medición se realiza en una solución lo más similar posible a las incógnitas excepto que no contiene hierro en absoluto. Esta muestra se llama el blanco. Ajusta un control en el fotómetro para establecer su lectura en cero al examinar el espacio en blanco.
La otra medición se realiza en una muestra que contiene una concentración conocida de hierro; esto generalmente se llama el control. Ajusta la sensibilidad del fotómetro para producir una lectura de algún valor arbitrario (50, digamos) con la solución de control. Suponiendo que la lectura del fotómetro es directamente proporcional a la concentración de hierro en la muestra (esto también podría tener que verificarse, en cuyo caso se debe construir una curva de calibración), la lectura del fotómetro puede convertirse entonces en concentración de hierro por simple proporción.
9 La desviación estándar
Considera los dos pares de observaciones aquí representados:
Observe que los medios de muestra pasan a tener el mismo valor de “40” (¡pura suerte!) , pero la diferencia en las precisiones de las dos mediciones hace evidente que el conjunto mostrado a la derecha es más confiable. ¿Cómo podemos expresar este hecho de manera sucinta? Podríamos decir que un experimento arroja un valor de 40 ±20, y el otro 40 ±5. Si bien esta información podría ser útil para algunos fines, es incapaz de dar respuesta a preguntas como “¿qué probabilidad tendría otro conjunto independiente de mediciones arrojar un valor medio dentro de un cierto rango de valores?” La respuesta a esta pregunta es quizás la forma más significativa de evaluar la “calidad” o confiabilidad de los datos experimentales, pero obtener tal respuesta requiere que empleemos algunas estadísticas formales.
Desviaciones de la media
Comenzamos por observar las diferencias entre la media de la muestra y los valores de datos individuales utilizados para calcular la media. Estas diferencias se conocen como desviaciones de la media, x i — x m. Estos valores se representan a continuación; tenga en cuenta que la única diferencia con respecto a las gráficas anteriores es la colocación del valor medio en 0 en el eje horizontal.
La varianza y su raíz cuadrada
A continuación, necesitamos encontrar el promedio de estas desviaciones. Tomando un promedio simple, sin embargo, no distinguirá entre estos dos conjuntos particulares de datos, porque ambas desviaciones promedian a cero. Por lo tanto, tomamos el promedio de los cuadrados de las desviaciones (la cuadratura hace desaparecer los signos de las desviaciones para que no puedan cancelar). Además, calculamos el promedio dividiendo por uno menos que el número de mediciones, es decir, por n —1 en lugar de por n. El resultado, generalmente denotado por S 2, se conoce como la varianza:
Finalmente, tomamos la raíz cuadrada de la varianza para obtener la desviación estándar S:
Ejemplo de problema: Calcular la varianza y desviación estándar para cada uno de los dos conjuntos de datos mostrados anteriormente.
Solución: La sustitución en las dos fórmulas produce los siguientes resultados:
| valores de datos | 20, 60 | 35,45 |
| media de la muestra | 40 | 40 |
| varianza S 2 | ||
| desviación estándar | 28 | 7.1 |
Comentario: Observe cómo los valores contrastantes de S reflejan la diferencia en las precisiones de los dos conjuntos de datos, algo que se pierde por completo si solo se consideran las dos medias.
Ahora que hemos desarrollado el importantísimo concepto de desviación estándar, podemos emplearlo en la siguiente sección para responder preguntas prácticas sobre cómo interpretar los resultados de una medición.