
7.2: Visión
- Page ID
- 148159
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Visión
- Identificar las estructuras clave del ojo y el papel que desempeñan en la visión.
- Resuma cómo el ojo y la corteza visual trabajan juntos para detectar y percibir los estímulos visuales en el ambiente, incluyendo el procesamiento de colores, forma, profundidad y movimiento.
- Explique el beneficio de tener dos ojos.
- Comprender las diferencias en la visión del color.
- Comprender la percepción y visión de profundidad.
- Entender la detección de movimiento.
Los humanos dependen en gran medida de la visión y de ver el mundo que los rodea a través de La mayoría de los organismos no humanos dependen más de los otros sentidos para interpretar el mundo que los rodea. Las investigaciones indican que gran parte de la corteza cerebral en humanos está dedicada a la visión. A medida que la información llega a la corteza visual en el cerebro, múltiples neuronas identifican formas, colores y movimientos. Cuando la luz cae sobre los ojos, los receptores sensoriales inician el proceso de transducción. A medida que ocurre este proceso, los individuos comienzan a percibir el entorno que los rodea.
Piensa en entrar a un teatro o habitación oscura si has estado afuera en un día soleado; muchas veces lleva tiempo adaptarse al cambio de intensidad de la luz en el ambiente. Los músculos del iris del ojo se ajustan para permitir que entre más luz en la pupila (la abertura redonda en el centro del iris). El iris del ojo es la parte coloreada del ojo que contrae y dilata la pupila para ajustarla a diferentes intensidades de luz que podamos encontrar a lo largo del día. Los fotorreceptores ayudan a distinguir las diferentes características de los diferentes objetos. Los tipos de fotorreceptores en el ojo humano incluyen bastones y conos; los bastones suelen ser más prevalentes que los conos. Las varillas nos dan sensibilidad bajo condiciones de iluminación tenue y nos permiten ver por la noche. Los conos nos permiten ver detalles finos en luz brillante y nos dan la capacidad de distinguir el color. Los conos están apretados alrededor de la fóvea (la pequeña región central ubicada en la parte posterior de la retina) y más escasamente en otros lugares. Las varillas pueblan la periferia (la región que rodea la fóvea) y están casi ausentes de la fóvea. A medida que los organismos se mueven por su entorno a lo largo del día, la información por la luz de objetos tanto cercanos como lejanos es codificada por el cerebro y se produce la identificación de colores, formas y movimiento (ver Figura\(\PageIndex{1}\)).
Anatomía del ojo humano
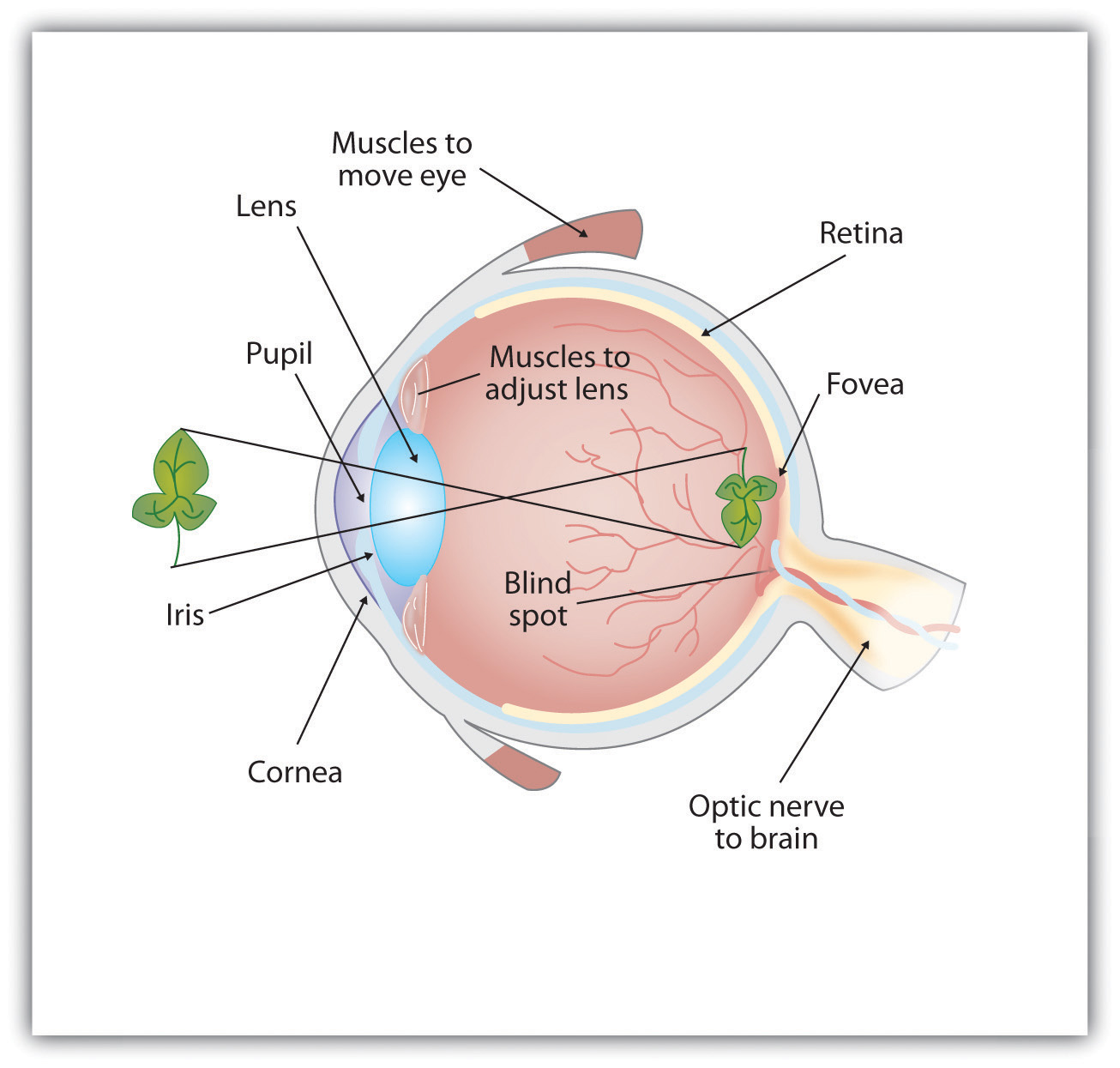
Figura\(\PageIndex{1}\): La luz ingresa al ojo a través de la córnea transparente, pasando por la pupila en el centro del iris. El lente se ajusta para enfocar la luz en la retina, donde aparece boca abajo y hacia atrás. Las células receptoras en la retina envían información a través del nervio óptico a la corteza visual. https://open.lib.umn.edu/intropsyc/c...04_s02_s01_f02
Figura de ojos normales, miopes y hipermetropía\(\PageIndex{2}\)

Figura\(\PageIndex{2}\) Para las personas con visión normal (izquierda), el cristalino enfoca adecuadamente la luz entrante en la retina. Para las personas miopes (centro), las imágenes de objetos lejanos se enfocan demasiado frente a la retina, mientras que para las personas con hipermetropía (derecha), las imágenes de objetos cercanos se enfocan demasiado detrás de la retina. Los anteojos resuelven el problema agregando una lente secundaria, correctiva. https://open.lib.umn.edu/intropsyc/chapter/4-2-seeing/#stangor-ch04_s02_s01_f02
La investigación indica que los humanos pueden distinguir entre millones de diferentes variaciones de color (Gerald, 1972). Aunque los humanos pueden distinguir entre una amplia variedad de variaciones, hay tres colores primarios que forman la base de estas variaciones; rojo, verde y azul. La capacidad de estos colores para formar estas variaciones se basa en el tono o sombra de los colores. El espectro electromagnético que se ilustra a continuación muestra que la luz visible para los humanos es solo una pequeña porción de todo el espectro, que incluye radiación que no podemos ver como luz porque está por debajo de la frecuencia de la luz roja visible y por encima de la frecuencia de la luz violeta visible.
La figura del espectro electromagnético\(\PageIndex{3}\)
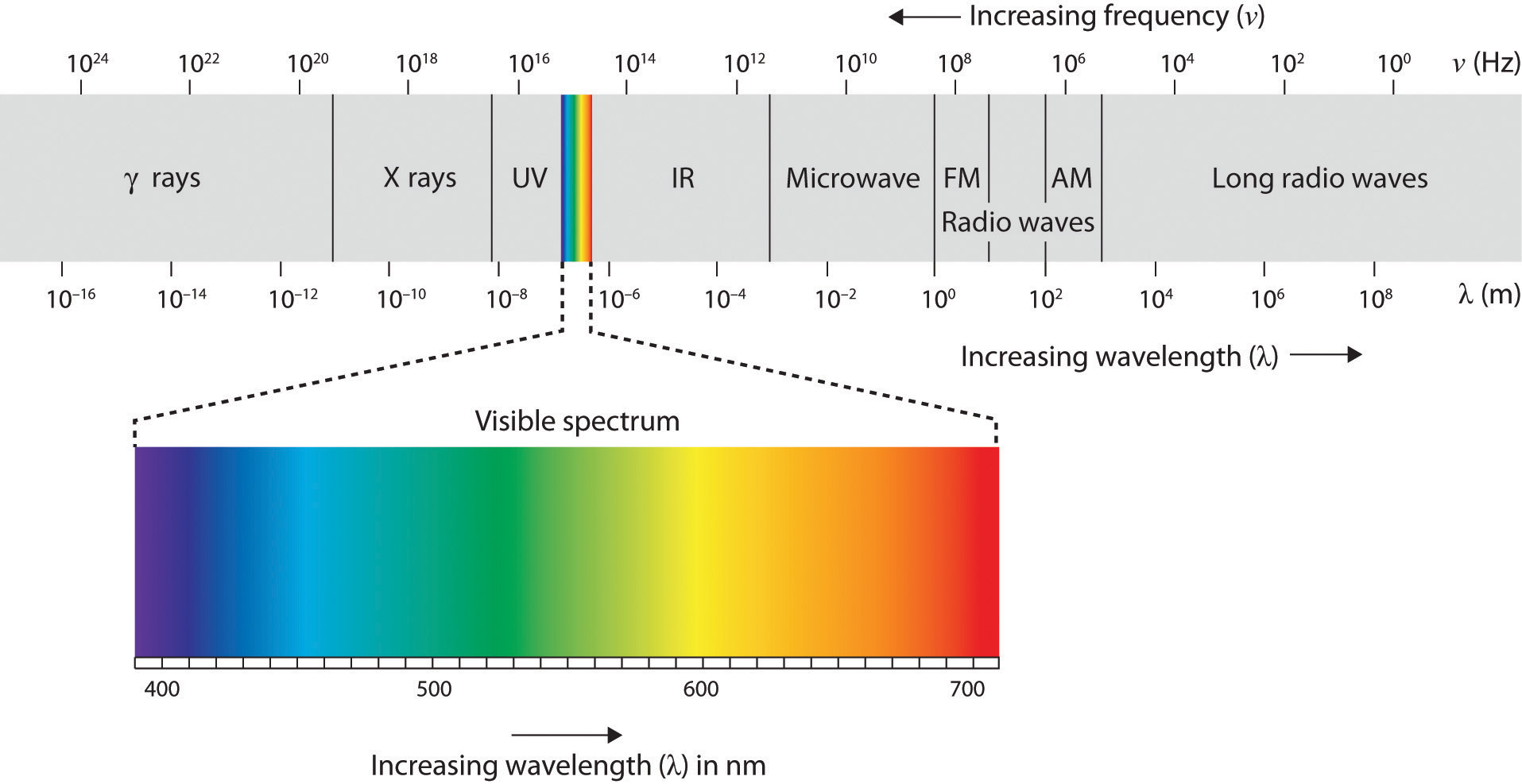
Figura\(\PageIndex{3}\): Solo una pequeña fracción de la energía electromagnética que nos rodea (el espectro visible) es detectable por el ojo humano.
En su importante investigación sobre la visión del color, Hermann von Helmholtz teorizó que el color se percibe porque los conos en la retina vienen en tres tipos. Un tipo de cono reacciona principalmente a la luz azul (longitudes de onda cortas), otro reacciona principalmente a la luz verde (longitudes de onda medias) y un tercero reacciona principalmente a la luz roja (longitudes de onda largas). La corteza visual luego detecta y compara la fuerza de las señales de cada uno de los tres tipos de conos, creando la experiencia del color. De acuerdo con esta teoría tricromática del color Young-Helmholtz, qué color vemos depende de la mezcla de las señales de los tres tipos de conos. Si el cerebro está recibiendo principalmente señales rojas y azules, por ejemplo, percibirá el púrpura; si está recibiendo principalmente señales rojas y verdes percibirá el amarillo; y si está recibiendo mensajes de los tres tipos de conos percibirá el blanco.
Las diferentes funciones de los tres tipos de conos son evidentes en personas que experimentan daltonismo. El daltonismo se puede definir como tener menor capacidad para ver el color o distinguir diferencias entre colores. El daltonismo rojo-verde es la forma más común, seguido del daltonismo azul-amarillo y el daltonismo total. El daltonismo rojo-verde afecta hasta 8% de los machos y 0.5% de las hembras de ascendencia del norte de Europa. El daltonismo rojo-verde es el resultado de la ausencia de conos de longitud de onda larga o media o de la producción de pigmentos de opsina anormales en estos conos que afectan la visión del color rojo-verde (ver Figura\(\PageIndex{4}\)).

Figura\(\PageIndex{4}\): Las personas con visión cromática normal pueden ver el número 42 en la primera imagen y el número 12 en la segunda (son vagos pero aparentes). No obstante, las personas daltónicas no pueden ver los números en absoluto. Wikimedia Commons.
Una aproximación alternativa a la teoría Young-Helmholtz, conocida como la teoría del color del proceso oponente, propone que analicemos la información sensorial no en términos de tres colores sino en tres conjuntos de “colores del oponente”: rojo-verde, amarillo-azul y blanco-negro. La evidencia para la teoría del proceso oponente proviene del hecho de que algunas neuronas en la retina y en la corteza visual están excitadas por un color (por ejemplo, rojo) pero inhibidas por otro color (por ejemplo, verde).
Un ejemplo de procesamiento oponente ocurre en la experiencia de una imagen residual. Si miras la bandera de la izquierda durante unos 30 segundos (cuanto más te veas, mejor será el efecto), y luego mueves tus ojos hacia el área en blanco a la derecha de la misma, verás la imagen secundaria. Cuando miramos fijamente las franjas verdes, nuestros receptores verdes se habituan y comienzan a procesarse con menos fuerza, mientras que los receptores rojos permanecen en plena potencia. Cuando cambiamos de mirada, vemos principalmente la parte roja del proceso oponente. Procesos similares crean el azul después del amarillo y el blanco después del negro (ver Figura\(\PageIndex{5}\)).

Figura\(\PageIndex{5}\): Bandera de Estados Unidos. La presencia de una imagen residual se explica mejor por la teoría del proceso oponente de la percepción del color. Mira la bandera durante unos segundos, y luego mueve tu mirada hacia el espacio en blanco que está junto a ella. ¿Ves la imagen secundaria? Mike Swanson — Bandera de Estados Unidos (invertida) — dominio público.
Percepción de profundidad
La percepción de profundidad es la capacidad de percibir el espacio tridimensional y juzgar con precisión la distancia. Sin percepción de profundidad, no podríamos conducir un automóvil, enhebrar una aguja o simplemente navegar por el supermercado (Howard & Rogers, 2001). La investigación ha encontrado que la percepción de profundidad se basa en parte en capacidades innatas y en parte aprendida a través de la experiencia (Witherington, 2005).
Los psicólogos Eleanor Gibson y Richard Walk (1960) probaron la capacidad de percibir la profundidad en bebés de 6 a 14 meses colocándolos en un acantilado visual, un mecanismo que da la percepción de una caída peligrosa, en la que los bebés pueden ser probados de manera segura para determinar su percepción de profundidad (ver Figura\(\PageIndex{6}\)). Los infantes fueron colocados a un lado del “acantilado”, mientras que sus madres los llamaban desde el otro lado. Gibson y Walk encontraron que la mayoría de los infantes o bien se arrastraban lejos del acantilado o permanecían en la pizarra y lloraban porque querían ir con sus madres, pero los infantes percibieron un abismo que instintivamente no podían cruzar. Investigaciones adicionales han encontrado que incluso los niños muy pequeños que aún no pueden gatear tienen miedo de las alturas (Campos, Langer, & Krowitz, 1970). Por otro lado, estudios también han encontrado que los infantes mejoran su coordinación mano-ojo a medida que aprenden a agarrar mejor los objetos y a medida que adquieren más experiencia en el rastreo, lo que indica que también se aprende la percepción de profundidad (Adolph, 2000).

La percepción de profundidad es el resultado de nuestro uso de señales de profundidad, mensajes de nuestro cuerpo y del entorno externo que nos proporcionan información sobre el espacio y la distancia. Las señales de profundidad binocular son señales de profundidad creadas por la disparidad de la imagen retiniana, es decir, el espacio entre nuestros ojos y, por lo tanto, que requieren la coordinación de ambos ojos. Un resultado de la disparidad retiniana es que las imágenes proyectadas en cada ojo son ligeramente diferentes entre sí. La corteza visual fusiona automáticamente las dos imágenes en una sola, lo que nos permite percibir la profundidad. Las películas tridimensionales hacen uso de la disparidad retiniana mediante el uso de gafas 3-D que el espectador usa para crear una imagen diferente en cada ojo. El sistema perceptual convierte rápida, fácil e inconscientemente la disparidad en 3-D.
Una señal de profundidad binocular importante es la convergencia, el giro hacia adentro de nuestros ojos que se requiere para enfocarnos en objetos que están a menos de unos 50 pies de distancia de nosotros. La corteza visual utiliza el tamaño del ángulo de convergencia entre los ojos para juzgar la distancia del objeto. Podrás sentir tus ojos convergiendo si lentamente acercas un dedo a tu nariz mientras continúas enfocándote en ella. Cuando cierras un ojo, ya no sientes la tensión; la convergencia es una señal de profundidad binocular que requiere que ambos ojos funcionen.
El sistema visual también utiliza acomodación para ayudar a determinar la profundidad. A medida que la lente cambia su curvatura para enfocarse en objetos distantes o cercanos, la información transmitida desde los músculos unidos a la lente nos ayuda a determinar la distancia de un objeto. El alojamiento solo es efectivo a distancias de visión cortas, sin embargo, por lo que si bien es útil al enhebrar una aguja o atar cordones de los zapatos, es mucho menos efectivo al conducir o practicar deportes.
Aunque las mejores señales de profundidad ocurren cuando ambos ojos trabajan juntos, somos capaces de ver la profundidad incluso con un ojo cerrado. Las señales de profundidad monocular son señales de profundidad que nos ayudan a percibir la profundidad usando un solo ojo (Sekuler y Blake, 2006). Algunos de los más importantes se resumen en la Tabla\(\PageIndex{1}\) “Señales de profundidad monocular que nos ayudan a juzgar la profundidad a distancia”.
Señales de profundidad\(\PageIndex{1}\) monocular de mesa que nos ayudan a juzgar la profundidad a distancia
| Nombre | Descripción | Ejemplo | Imagen |
|---|---|---|---|
| Posición | Tendemos a ver objetos más arriba en nuestro campo de visión como más lejos. | Los postes de la cerca a la derecha aparecen más lejos no sólo porque se hacen más pequeños sino también porque aparecen más arriba en la imagen. |
Figura
|
| Tamaño relativo | Suponiendo que los objetos en una escena son del mismo tamaño, los objetos más pequeños se perciben como más alejados. | A la derecha, los autos en la distancia parecen más pequeños que los más cercanos a nosotros. |
Figura
|
| Perspectiva lineal | Las líneas paralelas parecen converger a distancia. | Sabemos que las pistas a la derecha son paralelas. Cuando aparecen más cerca, determinamos que están más lejos. |
Figura
|
| Luz y sombra | El ojo recibe más luz reflejada de los objetos que están más cerca de nosotros. Normalmente, la luz viene de arriba, por lo que las imágenes más oscuras están en la sombra. | Vemos las imágenes a la derecha como extendidas y sangradas según su sombreado. Si invertimos la imagen, las imágenes invertirán. |
Figura
|
| Interposición | Cuando un objeto se superpone a otro objeto, lo vemos como más cercano. | A la derecha, debido a que la estrella azul cubre la barra rosa, se ve como más cerca que la luna amarilla. |
Figura
|
| Perspectiva aérea | Los objetos que parecen nebulosos, o que están cubiertos de smog o polvo, aparecen más lejos. | El artista que pintó el cuadro de la derecha utilizó la perspectiva aérea para hacer que las colinas distantes fueran más nebulosas y así aparecieran más alejadas. |
Figura
|






Motion
Muchos animales, entre ellos los seres humanos, tienen habilidades perceptuales muy sofisticadas que les permiten coordinar su propio movimiento con el movimiento de los objetos en movimiento para crear una colisión con ese objeto. Los murciélagos y aves utilizan este mecanismo para ponerse al día con sus presas, los perros lo usan para atrapar un Frisbee y los humanos lo usan para atrapar un balón de fútbol en movimiento. El cerebro detecta movimiento en parte por el tamaño cambiante de una imagen en la retina (los objetos que se ven más grandes suelen estar más cerca de nosotros) y en parte por el brillo relativo de los objetos.
También experimentamos movimiento cuando los objetos cercanos unos a otros cambian su apariencia. El efecto beta se refiere a la percepción de movimiento que se produce cuando diferentes imágenes se presentan una junto a la otra en sucesión (ver Nota “Efecto Beta y Fenómeno Phi”). La corteza visual llena la parte faltante del movimiento y vemos al objeto moviéndose. El efecto beta se utiliza en películas para crear la experiencia del movimiento. Un efecto relacionado es el fenómeno phi, en el que percibimos una sensación de movimiento causada por la aparición y desaparición de objetos que están cerca unos de otros. El fenómeno phi parece una zona móvil o una nube de color de fondo que rodea los objetos parpadeantes. El efecto beta y el fenómeno phi son otros ejemplos de la importancia de lo gestalt, nuestra tendencia a “ver más que la suma de las partes”.
Efecto Beta y Fenómeno Phi
En el efecto beta, nuestros ojos detectan movimiento a partir de una serie de imágenes fijas, cada una con el objeto en un lugar diferente. Este es el mecanismo fundamental de las películas (películas). En el fenómeno phi, la percepción del movimiento se basa en la ocultación momentánea de una imagen.
Fenómeno Phi: http://upload.wikimedia.org/Wikipedia/commons/6/6e/Lilac-Chaser.gif
Efecto beta: http://upload.wikimedia.org/Wikipedia/commons/0/09/Phi_phenomenom_no_watermark.gif
Atribución
- Secciones de visión adaptadas por Isaías Hernández de “Noba-visión”; https://nobaproject.com/modules/vision
- Secciones de visión adaptadas por Isaías Hernández de “Psicología-Penn State”; https://psu.pb.unizin.org/intropsych...eption-vision/
- Secciones de visión adaptadas por Isaías Hernández de “Introducción a la Psicología-Universidad de Minnesota”; https://open.lib.umn.edu/intropsyc/c...04_s02_s01_f02