
7.2: El teorema del límite central para las medias muestrales (promedios)
- Page ID
- 153439

Supongamos que\(X\) es una variable aleatoria con una distribución que puede ser conocida o desconocida (puede ser cualquier distribución). Usando un subíndice que coincida con la variable aleatoria, supongamos:
- \(\mu_{x} =\)la media de\(X\)
- \(\sigma_{x} =\)la desviación estándar de\(X\)
Si dibujas muestras aleatorias de tamaño\(n\), entonces a medida que\(n\) aumenta, la variable aleatoria\(\bar{X}\) que consiste en medias de muestra, tiende a distribuirse normalmente y
\[\bar{X} \sim N \left(\mu_{x}, \dfrac{\sigma_{x}}{\sqrt{n}}\right).\]
El teorema del límite central para las medias muestrales dice que si sigues dibujando muestras cada vez más grandes (como rodar uno, dos, cinco y finalmente, diez dados) y calculando sus medias, las medias muestrales forman su propia distribución normal (la distribución muestral). La distribución normal tiene la misma media que la distribución original y una varianza que equivale a la varianza original dividida por, el tamaño de la muestra. La variable\(n\) es el número de valores que se promedian juntos, no el número de veces que se realiza el experimento.
Para decirlo de manera más formal, si dibujas muestras aleatorias de tamaño\(n\), la distribución de la variable aleatoria\(\bar{X}\), que consiste en medias muestrales, se denomina distribución muestral de la media. La distribución muestral de la media se aproxima a una distribución normal a medida\(n\) que aumenta el tamaño de la muestra.
La variable aleatoria\(\bar{X}\) tiene una\(z\) puntuación diferente asociada a la misma de la variable aleatoria\(X\). La media\(\bar{x}\) es el valor de\(\bar{X}\) en una muestra.
\[z = \dfrac{\bar{x}-\mu_{x}}{\left(\dfrac{\sigma_{x}}{\sqrt{n}}\right)}\]
- \(\mu_{x}\)es el promedio de ambos\(X\) y\(\bar{X}\).
- \(\sigma \bar{x} = \dfrac{\sigma_{x}}{\sqrt{n}} = \)desviación estándar de\(\bar{X}\) y se llama el error estándar de la media.
Cómo: Encontrar probabilidades de medios en la calculadora
2 ° DISTR./
2:normalcdf
\(\text{normalcdf} \left(\text{lower value of the area, upper value of the area, mean}, \dfrac{\text{standard deviation}}{\sqrt{\text{sample size}}}\right)\)
donde:
- media es la media de la distribución original
- desviación estándar es la desviación estándar de la distribución original
- tamaño de la muestra\(= n\)
Ejemplo\(\PageIndex{1}\)
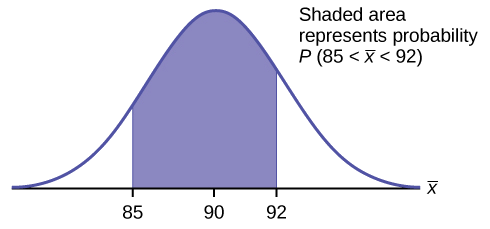
Una distribución desconocida tiene una media de 90 y una desviación estándar de 15. Las muestras de tamaño\(n = 25\) se extraen aleatoriamente de la población.
- Encuentra la probabilidad de que la media muestral esté entre 85 y 92.
- Encuentra el valor que está dos desviaciones estándar por encima del valor esperado, 90, de la media de la muestra.
Contestar
a.
Dejar\(X =\) un valor de la población desconocida original. La pregunta de probabilidad le pide encontrar una probabilidad para la media de la muestra.
Dejar\(\bar{X} =\) la media de una muestra de tamaño 25. Desde\(\mu_{x} = 90, \sigma_{x} = 15\), y\(n = 25\),
\[\bar{X} \sim N(90, \dfrac{15}{\sqrt{25}}). \nonumber\]
Encuentra\(P(85 < x < 92)\). Dibuja una gráfica.
\[P(85 < x < 92) = 0.6997 \nonumber\]
La probabilidad de que la media muestral esté entre 85 y 92 es de 0.6997.
normalcdf (valor inferior, valor superior, media, error estándar de la media)
La lista de parámetros se abrevia (valor inferior, valor superior,\(\mu\),\(\dfrac{\sigma}{\sqrt{n}}\))
normalcdf\((85,92,90,\dfrac{15}{\sqrt{25}}) = 0.6997\)
b.
Para encontrar el valor que es dos desviaciones estándar por encima del valor esperado 90, utilice la fórmula:
\[ \begin{align*} \text{value} &= \mu_{x} + (\#\text{ofTSDEVs})\left(\dfrac{\sigma_{x}}{\sqrt{n}}\right) \\[5pt] &= 90 + 2 \left(\dfrac{15}{\sqrt{25}}\right) = 96 \end{align*}\]
El valor que está dos desviaciones estándar por encima del valor esperado es de 96.
El error estándar de la media es
\[\dfrac{\sigma_{x}}{\sqrt{n}} = \dfrac{15}{\sqrt{25}} = 3. \nonumber\]
Recordemos que el error estándar de la media es una descripción de qué tan lejos (en promedio) estará la media muestral de la media poblacional en muestras aleatorias simples repetidas de tamaño\(n\).
Ejercicio\(\PageIndex{1}\)
Una distribución desconocida tiene una media de 45 y una desviación estándar de ocho. Muestras de tamaño\(n\) = 30 se extraen aleatoriamente de la población. Encuentra la probabilidad de que la media muestral esté entre 42 y 50.
- Contestar
-
\(P(42 < \bar{x} < 50) = \left(42, 50, 45, \dfrac{8}{\sqrt{30}}\right) = 0.9797\)
Ejemplo\(\PageIndex{2}\)
El tiempo, en horas, que tarda un grupo de personas “más de 40" en jugar un partido de fútbol se distribuye normalmente con una media de dos horas y una desviación estándar de 0.5 horas. Se extrae aleatoriamente una muestra de tamaño\(n = 50\) de la población. Encuentra la probabilidad de que la media de la muestra esté entre 1.8 horas y 2.3 horas.
Contestar
Que\(X =\) el tiempo, en horas, se necesita para jugar un partido de futbol.
La pregunta de probabilidad te pide encontrar una probabilidad para el tiempo medio de la muestra, en horas, se necesita para jugar un partido de fútbol.
Que\(\bar{X} =\) el tiempo medio, en horas, se necesita para jugar un partido de futbol.
Si\(\mu_{x} =\) _________,\(\sigma_{x} =\) __________, y\(n =\) ___________, entonces\(X \sim N\) (______, ______) por el teorema del límite central para las medias.
\(\mu_{x} = 2, \sigma_{x} = 0.5, n = 50\), y\(X \sim N \left(2, \dfrac{0.5}{\sqrt{50}}\right)\)
Encuentra\(P(1.8 < \bar{x} < 2.3)\). Dibuja una gráfica.
\(P(1.8 < \bar{x} < 2.3) = 0.9977\)
normalcdf\(\left(1.8,2.3,2,\dfrac{.5}{\sqrt{50}}\right) = 0.9977\)
La probabilidad de que el tiempo medio esté entre 1.8 horas y 2.3 horas es 0.9977.
Ejercicio\(\PageIndex{2}\)
El tiempo empleado en el SAT para un grupo de estudiantes se distribuye normalmente con una media de 2.5 horas y una desviación estándar de 0.25 horas. Se extrae aleatoriamente\(n = 60\) un tamaño de muestra de la población. Encuentra la probabilidad de que la media de la muestra esté entre dos horas y tres horas.
- Contestar
-
\[P(2 < \bar{x} < 3) = \text{normalcdf}\left(2, 3, 2.5, \dfrac{0.25}{\sqrt{60}}\right) = 1 \nonumber\]
Calculadora Habilidades
Para encontrar percentiles para medias en la calculadora, siga estos pasos.
- 2 º Distr
- 3:InvNorm
\(k = \text{invNorm} \left(\text{area to the left of} k, \text{mean}, \dfrac{\text{standard deviation}}{\sqrt{sample size}}\right)\)
donde:
- \(k\)= el\(k\) percentil th
- media es la media de la distribución original
- desviación estándar es la desviación estándar de la distribución original
- tamaño de la muestra =\(n\)
Ejemplo\(\PageIndex{3}\)
En un estudio reciente reportado el 29 de octubre de 2012 en el Blog Flurry, la edad media de los usuarios de tabletas es de 34 años. Supongamos que la desviación estándar es de 15 años. Toma una muestra de tamaño\(n = 100\).
- ¿Cuáles son la media y la desviación estándar para las edades medias de la muestra de los usuarios de tabletas?
- ¿Qué aspecto tiene la distribución?
- Encontrar la probabilidad de que la edad media de la muestra sea mayor a 30 años (la edad media reportada de los usuarios de tabletas en este estudio en particular).
- Encontrar el percentil 95 para la edad media de la muestra (a un decimal).
Contestar
- Dado que la media muestral tiende a apuntar a la media poblacional, tenemos\(\mu_{x} = \mu = 34\). La desviación estándar de la muestra viene dada por:\[\sigma_{x} = \dfrac{\sigma}{\sqrt{n}} = \dfrac{15}{\sqrt{100}} = \dfrac{15}{10} = 1.5 \nonumber\]
- El teorema del límite central establece que para tamaños de muestra grandes (\(n\)), la distribución muestral será aproximadamente normal.
- La probabilidad de que la edad media de la muestra sea mayor a 30 viene dada por:\[P(Χ > 30) = \text{normalcdf}(30,E99,34,1.5) = 0.9962 \nonumber\]
- Let\(k\) = el percentil 95. \[k = \text{invNorm}\left(0.95, 34, \dfrac{15}{\sqrt{100}}\right) = 36.5 \nonumber\]
Ejercicio\(\PageIndex{3}\)
En un artículo en Flurry Blog, se identifica una brecha de marketing de juegos para hombres entre las edades de 30 y 40 años. Estás investigando un juego de inicio dirigido al grupo demográfico de 35 años. Tu idea es desarrollar un juego de estrategia que pueda ser jugado por hombres desde finales de los 20 hasta finales de los 30. Con base en los datos del artículo, la investigación de la industria muestra que el jugador de estrategia promedio tiene 28 años con una desviación estándar de 4.8 años. Tomas una muestra de 100 jugadores seleccionados al azar. Si tu mercado objetivo es de 29 a 35 años, ¿deberías continuar con tu estrategia de desarrollo?
- Contestar
-
Es necesario determinar la probabilidad de que los hombres cuya edad media esté entre 29 y 35 años de edad quieran jugar un juego de estrategia.
\[P(29 < \bar{x} < 35) = \text{normalcdf} \left(29, 35, 28,\dfrac{4.8}{\sqrt{100}}\right) = 0.0186\]
Puedes concluir que hay aproximadamente un 1.9% de probabilidad de que tu juego sea jugado por hombres cuya edad media esté entre 29 y 35 años.
Ejemplo\(\PageIndex{4}\)
El número medio de minutos para la interacción de la aplicación por parte de un usuario de tableta es de 8.2 minutos. Supongamos que la desviación estándar es de un minuto. Toma una muestra de 60.
- ¿Cuáles son la media y la desviación estándar para la muestra del número medio de interacción de la aplicación por parte de un usuario de tableta?
- ¿Cuál es el error estándar de la media?
- Encuentre el percentil 90 para el tiempo medio de muestra para la interacción de la aplicación para un usuario de tableta. Interpretar este valor en una oración completa.
- Encuentra la probabilidad de que la media de la muestra esté entre ocho minutos y 8.5 minutos.
Contestar
- \(\mu = \mu = 8.2 \sigma_{\bar{x}} = \dfrac{\sigma}{\sqrt{n}} = \dfrac{1}{\sqrt{60}} = 0.13\)
- Esto nos permite calcular la probabilidad de medias muestrales de una distancia particular de la media, en muestras repetidas de tamaño 60.
- Let\(k\) = el percentil 90
\(k = \text{invNorm}\left(0.90, 8.2, \dfrac{1}{\sqrt{60}}\right) = 8.37\). Estos valores indican que el 90 por ciento del tiempo promedio de interacción de la aplicación para los usuarios de la mesa es inferior a 8.37 minutos. - \(P(8 < \bar{x} < 8.5) = \text{normalcdf}\left(8, 8.5, 8.2, \dfrac{1}{\sqrt{60}}\right) = 0.9293\)
Ejercicio\(\PageIndex{4}\)
Las latas de una bebida de cola afirman contener 16 onzas. Se miden las cantidades en una muestra y las estadísticas son\(n = 34\),\(\bar{x} = 16.01\) onzas. Si las latas se llenan para que\(\mu = 16.00\) onzas (como etiquetadas) y\(\sigma = 0.143\) onzas, encuentre la probabilidad de que una muestra de 34 latas tenga una cantidad promedio mayor a 16.01 onzas. ¿Los resultados sugieren que las latas se llenan con una cantidad mayor a 16 onzas?
- Contestar
-
Tenemos\(P(\bar{x} > 16.01) = \text{normalcdf} \left(16.01,E99,16, \dfrac{0.143}{\sqrt{34}}\right) = 0.3417\). Dado que existe una probabilidad de 34.17% de que el peso promedio de la muestra sea mayor a 16.01 onzas, debemos ser escépticos sobre el volumen reclamado por la compañía. Si soy consumidor, debería alegrarme de que probablemente esté recibiendo cola gratis. Si soy el fabricante, necesito determinar si mis procesos de embotellado están fuera de los límites aceptables.
Resumen
En una población cuya distribución puede ser conocida o desconocida, si el tamaño (\(n\)) de las muestras es suficientemente grande, la distribución de las medias muestrales será aproximadamente normal. La media de las medias de la muestra será igual a la media poblacional. La desviación estándar de la distribución de las medias muestrales, denominada error estándar de la media, es igual a la desviación estándar poblacional dividida por la raíz cuadrada del tamaño muestral (\(n\)).
Revisión de Fórmula
- El teorema del límite central para las medias de la muestra:\[\bar{X} \sim N\left(\mu_{x}, \dfrac{\sigma_{x}}{\sqrt{n}}\right) \nonumber\]
- La Media\(\bar{X}: \sigma_{x}\)
- Teorema del límite central para las medias muestrales z-score y error estándar de la media:\[z = \dfrac{\bar{x}-\mu_{x}}{\left(\dfrac{\sigma_{x}}{\sqrt{n}}\right)} \nonumber\]
- Error estándar de la media (desviación estándar (\(\bar{X}\))):\[\dfrac{\sigma_{x}}{\sqrt{n}} \nonumber\]
Glosario
- Promedio
- un número que describe la tendencia central de los datos; hay una serie de promedios especializados, incluyendo la media aritmética, la media ponderada, la mediana, el modo y la media geométrica.
- Teorema de Límite Central
- Dada una variable aleatoria (RV) con media conocida\(\mu\) y desviación estándar conocida,\(\sigma\), estamos muestreando con tamaño\(n\), y estamos interesados en dos nuevas RV: la media de la muestra,\(\bar{X}\), y la suma de la muestra,\(\sum X\). Si el tamaño (\(n\)) de la muestra es suficientemente grande, entonces\(\bar{X} \sim N\left(\mu, \dfrac{\sigma}{\sqrt{n}}\right)\) y\(\sum X \sim N(n\mu, (\sqrt{n})(\sigma))\). Si el tamaño (\(n\)) de la muestra es suficientemente grande, entonces la distribución de las medias muestrales y la distribución de las sumas muestrales se aproximarán a distribuciones normales independientemente de la forma de la población. La media de las medias de la muestra será igual a la media de la población, y la media de las sumas de la muestra será igual a\(n\) veces la media de la población. La desviación estándar de la distribución de las medias muestrales\(\dfrac{\sigma}{\sqrt{n}}\),, se denomina error estándar de la media.
- Distribución Normal
- una variable aleatoria continua (RV) con pdf\(f(x) = \dfrac{1}{\sigma \sqrt{2 \pi}}e^{\dfrac{-(x-\mu)^{2}}{2 \sigma^{2}}}\), donde\(\mu\) es la media de la distribución y\(\sigma\) es la desviación estándar; notación:\(X \sim N(\mu, \sigma)\). Si\(\mu = 0\) y\(\sigma = 1\), el RV se denomina distribución normal estándar.
- Error estándar de la media
- la desviación estándar de la distribución de las medias de la muestra, o\(\dfrac{\sigma}{\sqrt{n}}\).
Referencias
- Baran, Daya. “El 20 por ciento de los estadounidenses nunca han usado el correo electrónico”. WebGuild, 2010. Disponible en línea en www.webguild.org/20080519/20-... ver-usado-correo electrónico (consultado el 17 de mayo de 2013).
- Datos de The Flurry Blog, 2013. Disponible en línea en blog.flurry.com (consultado el 17 de mayo de 2013).
- Datos del Departamento de Agricultura de los Estados Unidos.