
4.10: Modelado de la señal de voz
- Page ID
- 85293

- Un modelo del tracto vocal humano.
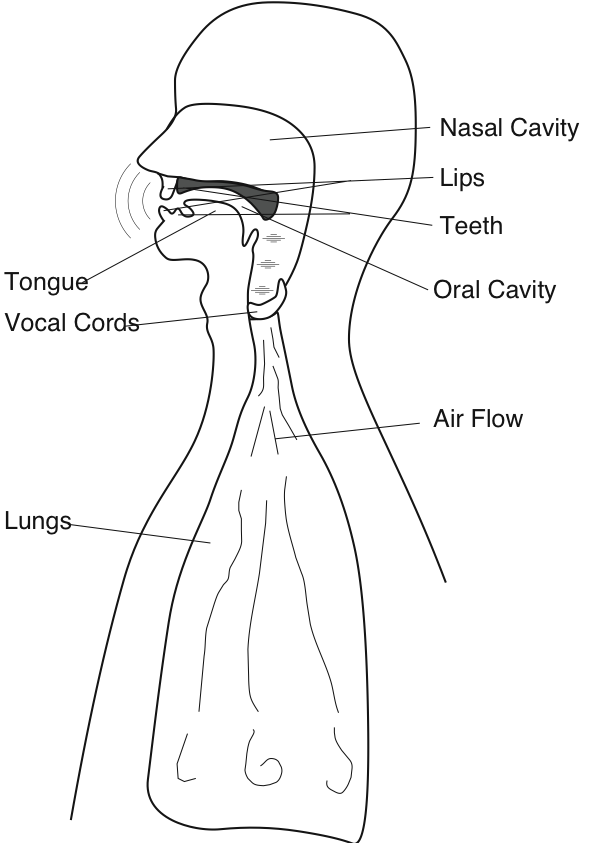
La información contenida en la palabra hablada es transmitida por la señal de voz. Debido a que analizaremos varios esquemas de transmisión y procesamiento de voz, necesitamos entender la estructura de la señal de voz —qué tiene de especial la señal de voz— y cómo podemos describir y modelar la producción de voz. Este esfuerzo de modelación consiste en encontrar la descripción de un sistema de cómo se da estructura a las señales relativamente desestructuradas, que surgen de fuentes simples, al pasarlas a través de una interconexión de sistemas para producir voz. Para el habla y para muchas otras situaciones, la elección del sistema se rige por la física subyacente al proceso de producción real. Debido a que la ecuación fundamental de la acústica —la ecuación de ondas— se aplica aquí y es lineal, podemos usar sistemas lineales en nuestro modelo con una buena precisión. La naturalidad de los modelos de sistemas lineales para el habla no se extiende a otras situaciones. En muchos casos, las matemáticas subyacentes gobernadas por la física, biología y/o química del problema son no lineales, dejando como aproximaciones los modelos de sistemas lineales. Los modelos no lineales son mucho más difíciles de entender en el estado actual del conocimiento, y los ingenieros de información frecuentemente prefieren los modelos lineales porque proporcionan un mayor nivel de comodidad, pero no necesariamente un nivel suficiente de precisión.
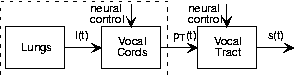
La Figura 4.10.1 muestra el sistema de producción de voz real y la Figura 4.10.2 muestra el sistema de producción de voz modelo. Las características del modelo dependen de si estás diciendo una vocal o una consonante. Nos concentramos primero en el mecanismo de producción de vocales. Cuando las cuerdas vocales son colocadas bajo tensión por la musculatura circundante, la presión del aire de los pulmones hace que las cuerdas vocales vibren. Para visualizar este efecto, toma una goma elástica y sosténgala frente a tus labios. Si se mantiene abierto al soplar a través de él, el aire pasa más o menos libremente; esta situación corresponde al “modo de respiración”. Si se mantienen tensos y juntos, soplar a través de la abertura hace que los lados de la banda de goma vibren. Este efecto funciona mejor con una banda de goma ancha. Se puede imaginar cómo es el flujo de aire en el lado opuesto de la goma elástica o las cuerdas vocales. Su poder pulmonar es la fuente simple a la que se hace referencia anteriormente; puede modelarse como un suministro constante de presión de aire. Las cuerdas vocales responden a esta entrada por vibración, lo que significa que la salida de este sistema es alguna función periódica.
Tenga en cuenta que el sistema de cuerdas vocales toma una entrada constante y produce un flujo de aire periódico que corresponde a su señal de salida. ¿Este sistema es lineal o no lineal? Justifica tu respuesta.
Solución
Si la glotis fuera lineal, una entrada constante (una sinusoide de frecuencia cero) debería producir una salida constante. La salida periódica indica un comportamiento no lineal.
Los cantantes modifican la tensión de las cuerdas vocales para cambiar el tono y producir la nota musical deseada. La tensión de las cuerdas vocales se rige por una entrada de control a la musculatura; en los modelos del sistema representamos las entradas de control como señales que llegan a la parte superior o inferior del sistema. Ciertamente en el caso del habla y en muchos otros casos también, es la entrada de control la que lleva la información, impresionándola en la salida del sistema. El cambio de estructura de la señal resultante de la variación de la entrada de control permite que la información sea transportada por la señal, un proceso genéricamente conocido como modulación. En el canto, la musicalidad se transmite en gran medida por el tono; en el habla occidental, el tono es mucho menos importante. Una oración puede leerse de manera monótona sin destruir por completo la información expresada por la oración. Sin embargo, la diferencia entre una declaración y una pregunta se expresa frecuentemente por cambios de tono. Por ejemplo, fíjense las diferencias sonoras entre “Vamos al parque” y “¿Vamos al parque?”
Para algunas consonantes, las cuerdas vocales vibran igual que en las vocales. Por ejemplo, los llamados sonidos nasales “n” y “m” tienen esta propiedad. Para otros, las cuerdas vocales no producen una salida periódica. Volviendo al mecanismo, cuando se producen consonantes como “f”, las cuerdas vocales se colocan bajo mucha menos tensión, lo que resulta en un flujo turbulento. El flujo de aire de salida resultante es bastante errático, tanto es así que lo describimos como ruido. Definimos el ruido cuidadosamente más adelante cuando profundizamos en problemas de comunicación.
La salida periódica de las cuerdas vocales puede ser bien descrita por el tren de pulsos periódicos p T (t), como se muestra en la señal de pulso periódico, con T denotando el periodo de tono. El espectro de esta señal contiene armónicos de la frecuencia 1/T, lo que se conoce como la frecuencia de tono o la frecuencia fundamental F0. La principal diferencia entre el habla adulta masculina y femenina/prepubescente es el tono. Antes de la pubertad, la frecuencia de tono para el habla normal oscila entre 150-400 Hz tanto para hombres como para mujeres. Después de la pubertad, las cuerdas vocales de los machos sufren un cambio físico, lo que tiene el efecto de disminuir su frecuencia de tono al rango 80-160 Hz. Si pudiéramos examinar la salida de las cuerdas vocales, probablemente podríamos discernir si el hablante era masculino o femenino. Esta diferencia también es fácilmente evidente en la propia señal de voz.
Para simplificar nuestro esfuerzo de modelado de voz, asumiremos que el periodo de tono es constante. Con esta simplificación, colapsamos el sistema vocal-cord-pulmón como una fuente simple que produce la señal de pulso periódica (Figura 4.10.2). La señal de presión sonora así producida entra en la boca detrás de la lengua, crea perturbaciones acústicas, y sale principalmente a través de los labios y hasta cierto punto por la nariz. Los especialistas del habla suelen nombrar la boca, la lengua, los dientes, los labios y la cavidad nasal, el tracto vocal. La física que rige las perturbaciones sonoras producidas en el tracto vocal y las de una tubería de órgano son bastante similares. Mientras que el tubo de órgano tiene la estructura física simple de un tubo recto, la sección transversal del “tubo” del tracto vocal varía a lo largo de su longitud debido a las posiciones de la lengua, los dientes y los labios. Son estas posiciones las que son controladas por el cerebro para producir los sonidos vocales. Al extender los labios, juntar los dientes y acercar la lengua hacia la parte frontal del techo de la boca se produce el sonido “ee”. Redondear los labios, extender los dientes y colocar la lengua hacia la parte posterior de la cavidad oral produce el sonido “oh”. Estas variaciones dan como resultado un sistema lineal, invariable en el tiempo, que tiene una respuesta de frecuencia tipificada por varios picos, como se muestra en la Figura 4.10.3.
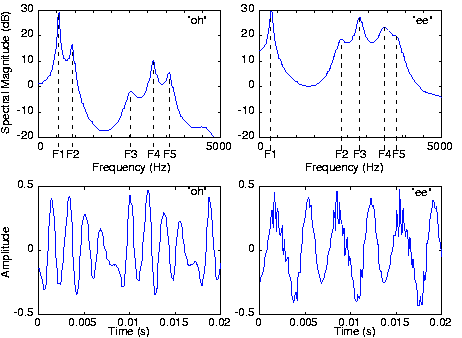
Estos picos se conocen como formantes. Así, los procesadores de señal de voz dirían que el sonido “oh” tiene una frecuencia de primer formante mayor que el sonido “ee”, siendo F2 mucho mayor durante “ee”. F2 y F3 (el segundo y tercer formantes) tienen más energía en “ee” que en “oh”. En lugar de servir como filtro, rechazando frecuencias altas o bajas, el tracto vocal sirve para dar forma al espectro de las cuerdas vocales. En el dominio del tiempo, tenemos una señal periódica, el tono, que sirve como entrada a un sistema lineal. Sabemos que la salida —la señal de voz que pronunciamos y que es escuchada por otros y por nosotros mismos— también será periódica. Ejemplo de señales de voz en el dominio del tiempo se muestran en la Figura 4.10.3 donde la periodicidad es bastante evidente.
A partir de las gráficas de forma de onda mostradas en la Figura 4.10.3, determinar el periodo de tono y la frecuencia de tono.
Solución
En el panel inferior izquierdo, el periodo es de aproximadamente 0.009 s, lo que equivale a una frecuencia de 111 Hz. El panel inferior derecho tiene un periodo de aproximadamente 0.0065 s, una frecuencia de 154 Hz.
Dado que las señales de voz son periódicas, la voz tiene una representación en serie de Fourier dada por la respuesta de un circuito lineal a una señal periódica. Debido a que la acústica del tracto vocal es lineal, sabemos que el espectro de la salida es igual al producto del espectro de la señal de tono y la respuesta de frecuencia del tracto vocal. Se obtiene así el modelo fundamental de producción de voz.
\[S(f)=P_{T}(f)H_{V}(f) \nonumber \]
Aquí, H V (f) es la función de transferencia del sistema del tracto vocal. La serie de Fourier para la salida de las cuerdas vocales, derivada en esta ecuación, es
\[c_{k}=Ae^{-\frac{i\pi k\Delta }{T}}\frac{\frac{\sin (\pi k\Delta )}{T}}{\pi k} \nonumber \]
y se representa en la parte superior en la Figura 4.10.4a. Si tuviéramos, por ejemplo, un hablante masculino con aproximadamente un tono de 110 Hz (T ~ 9.1ms) diciendo la vocal “oh”, el espectro de su discurso predicho por nuestro modelo se muestra en la Figura 4.10.1.
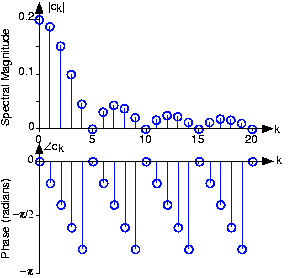
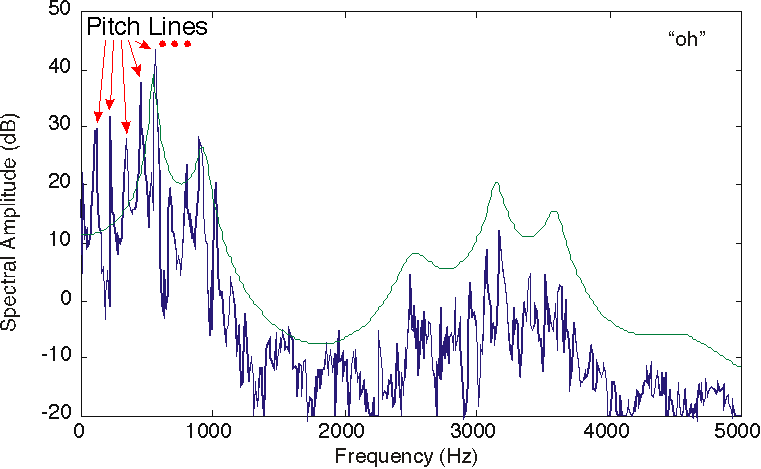
La función de transferencia del tracto vocal, mostrada como la línea delgada y suave, se superpone al espectro del habla masculina real correspondiente al sonido “oh”. Se indican las líneas de tono correspondientes a armónicos de la frecuencia de tono.
El espectro modelo idealiza el espectro medido y captura todas las características importantes. El espectro medido ciertamente demuestra lo que se conoce como líneas de tono, y nos damos cuenta a partir de nuestro modelo que se deben a la excitación periódica de las cuerdas vocales del tracto vocal. La conformación del espectro lineal del tracto vocal es claramente evidente, pero difícil de discernir exactamente, especialmente en las frecuencias más altas. La función de transferencia del modelo para el tracto vocal hace que los formantes sean mucho más evidentes.
Los coeficientes de la serie de Fourier para el habla están relacionados con la función de transferencia del tracto vocal solo en las frecuencias:\[\frac{k}{T},\; k\in \left \{ 1,2,... \right \} \nonumber \]
ver resultado anterior. ¿El habla masculina o femenina tendería a tener una estructura formante más claramente identificable cuando se computa su espectro? Consideremos, por ejemplo, ¿cómo cambiaría el espectro mostrado a la derecha en la Figura 4.10.4a si el tono fuera el doble de alto (≈ 300 Hz)?
Solución
Debido a que los machos tienen una frecuencia de tono más baja, el espaciado entre líneas espectrales es menor Este espaciamiento más cercano revela con mayor precisión la estructura del formante. Duplicar la frecuencia de tono a 300 Hz para la Figura 4.10.4a equivaldría a eliminar todas las demás líneas espectrales.
Cuando hablamos, el tono y la función de transferencia del tracto vocal no son estáticos; cambian según sus señales de control para producir voz. Los ingenieros suelen mostrar cómo cambia el espectro del habla con el tiempo con lo que se conoce como espectrograma. Véase la Figura 4.10.5 a continuación. Observe cómo el espectro de líneas, que indica cómo cambia el tono, es visible durante las vocales, pero no durante las consonantes (como el ce en “Rice”).
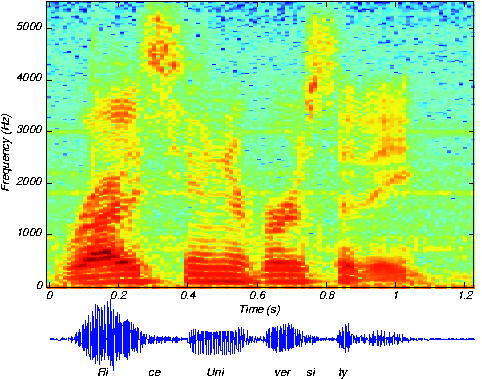
El modelo fundamental para el habla indica cómo los ingenieros utilizan la física subyacente al proceso de generación de señal y explotan su estructura para producir un modelo de sistemas que suprime la física al tiempo que enfatiza cómo se “construye” la señal. Desde la vida cotidiana, sabemos que el discurso contiene una gran cantidad de información. Queremos determinar cómo transmitirlo y recibirlo. La transmisión de voz eficiente y efectiva requiere que conozcamos las propiedades de la señal y su estructura (tal como lo expresa el modelo fundamental de producción de voz). Vemos en la Figura 4.10.5, por ejemplo, que el habla contiene energía significativa desde la frecuencia cero hasta alrededor de 5 kHz.
Los sistemas de transmisión de voz efectivos deben ser capaces de hacer frente a señales que tienen este ancho de banda. Es interesante que un sistema que no soporta este ancho de banda de 5 kHz es el teléfono: Los sistemas telefónicos actúan como un filtro de paso de banda que pasa energía entre aproximadamente 200 Hz y 3.2 kHz. La consecuencia más importante de este filtrado es la eliminación de energía de alta frecuencia. En nuestra enunciación de muestra, el sonido “ce” en “Rice"” contiene la mayor parte de su energía por encima de 3.2 kHz; este efecto de filtrado es por lo que es extremadamente difícil distinguir los sonidos “s” y “f” por teléfono. Inténtalo tú mismo: Llama a un amigo y determina si puede distinguir entre las palabras “seis” y “arreglar”. Si dices estas palabras aisladamente para que ningún contexto proporcione una pista sobre qué palabra estás diciendo, tu amigo no podrá distinguirlas. La radio sí admite este ancho de banda (vea más sobre los sistemas de radio AM y FM).
Los sistemas eficientes de transmisión de voz explotan la estructura especial de la señal de voz: ¿Qué hace que el habla Se pueden conjurar muchas señales que abarcan las mismas frecuencias que el habla —sonidos de motor de automóviles, música de violín, cortezas de perro— pero no suenan en absoluto como el habla. Más adelante aprenderemos que la transmisión de cualquier señal de ancho de banda de 5 kHz requiere aproximadamente 80 kbps (miles de bits por segundo) para transmitir digitalmente. Las señales de voz se pueden transmitir usando menos de 1 kbps debido a su estructura especial. Reducir el “ancho de banda digital” de manera tan drástica significa que los ingenieros dedicaron muchos años a desarrollar métodos de procesamiento y codificación de señales que pudieran capturar las características especiales del habla sin destruir cómo suena. Si usabas un sistema de transmisión de voz para enviar un sonido de violín, llegaría horriblemente distorsionado; el habla transmitida de la misma manera sonaría bien.
La explotación de la estructura especial del habla requiere ir más allá de las capacidades de los sistemas de procesamiento de señales analógicas. Muchos sistemas de transmisión de voz funcionan encontrando el tono del hablante y las frecuencias formantes. Fundamentalmente, necesitamos hacer más que filtrar para determinar la estructura de la señal de voz; necesitamos manipular las señales de más formas de las que son posibles con los sistemas analógicos. Dicha flexibilidad es alcanzable (pero no sin alguna pérdida) con sistemas digitales programables.