
14.3: Encontrar conjuntos de equivalencia
- Page ID
- 115252
Con datos binarios, se utilizan algoritmos numéricos para buscar clases de actores que satisfagan las definiciones matemáticas de equivalencia automórfica. Básicamente, se intercambian los nodos de una gráfica, y las distancias entre todos los pares de actores en la nueva gráfica se comparan con la gráfica original. Cuando la nueva gráfica y la gráfica antigua tienen las mismas distancias entre los nodos, las gráficas son isomórficas, y el “intercambio” que se realizó identifica las subgráficas isomórficas.
Un enfoque para los datos binarios, “todas las permutaciones”, ( Redes>Roles y Posiciones>Automorficía>Todas las Permutaciones ) compara literalmente cada posible intercambio de nodos para encontrar gráficas isomórficas. Incluso con una pequeña gráfica, hay un número muy grande de tales alternativas, y el cálculo es extenso. Un enfoque alternativo con la misma intención (“optimización por búsqueda tabú”) (Network>Roles y posiciones> Exact>Optimization ) puede ordenar nodos mucho más rápidamente en un número definido por el usuario de particiones de tal manera que maximizar la equivalencia automórfica. No hay garantía, sin embargo, de que el número de particiones (clases de equivalencia) elegidas sea “correcto”, o que los automorfismos identificados sean “exactos”. Para conjuntos de datos más grandes, y donde estamos dispuestos a entretener la idea de que dos subestructuras pueden ser “casi” equivalentes, la optimización es un método muy útil.
Cuando tenemos medidas de la fuerza, costo o probabilidad de relaciones entre nodos (es decir, datos valorados), la equivalencia automórfica exacta es mucho menos probable. Sin embargo, es posible identificar clases de actores aproximadamente equivalentes en función de su perfil de distancia con todos los demás actores. El método de “equivalencia de distancias” (Network>Roles y posiciones>Automorphic>MaxSim ) produce medidas del grado de equivalencia automórfica para cada par de nodos, que pueden examinarse agrupando y métodos de escalado para identificar clases aproximadas. Este método también se puede aplicar a datos binarios convirtiendo primero la adyacencia binaria en alguna medida de la distancia gráfica (generalmente, distancia geodésica).
Veamos estos con un poco más de detalle, con algunos ejemplos.
Todas las permutaciones (es decir, fuerza bruta)
Los automorfismos en una gráfica pueden ser identificados por el método de fuerza bruta de examinar cada posible permutación de la gráfica. Con una pequeña gráfica, y una computadora rápida, esto es algo útil de hacer. Básicamente, se examina cada posible permutación de la gráfica para ver si tiene la misma estructura de empate que la gráfica original. Para las gráficas de más de unos pocos actores, el número de permutaciones que deben compararse se vuelve extremadamente grande.
Vamos a usar Redes>Roles y Posiciones>Automorficía>Todas las Permutaciones para buscar en la red Wasserman-Faust que se muestra en la Figura 14.1.
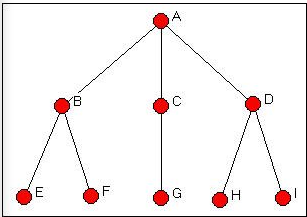
Figura 14.1: Red Wasserman-Fausto
Los resultados de Redes>Roles y Posiciones>Automorficía>Todas las Permutaciones para esta gráfica se muestran en la Figura 14.2.

Figura 14.2: Equivalencias automórficas por todas las permutaciones para la red Wasserman-Faust
El algoritmo examinó más de trescientas sesenta y dos mil posibles permutaciones de la gráfica. Las clases de isomorfismo que localizó se llaman “órbitas”. Y, los resultados corresponden a nuestro análisis lógico (capítulo 12). Hay cinco “tipos” de actores que están incrustados a distancias iguales de otros conjuntos de actores: el actor A (órbita 1), el actor C (órbita 3) y el actor G (órbita 7) son únicos. Los actores B y D forman una clase de actores que pueden intercambiarse si también se intercambian miembros de otras clases; los actores E, F, H e I (5, 6, 8 y 9) también forman una clase de actores intercambiables.
Nótese que las clases de automorfismo identifican grupos de actores que tienen el mismo patrón de distancia de otros actores, en lugar de las “subestructuras” mismas (en este caso, las dos ramas del árbol.
Optimización por Tabu Search
Para gráficas más grandes, la búsqueda directa de todas las equivalencias no es práctica tanto porque es computacionalmente intensiva como porque es probable que actores exactamente equivalentes sean raros.
Redes>Roles y Posiciones>Exacto>Optimización proporciona una herramienta numérica para encontrar las mejores aproximaciones a un número seleccionado por el usuario de clases de automorfismo. Al usar este método, es importante explorar un rango de posibles números de particiones (a menos que uno tenga una teoría previa al respecto), para determinar cuántas particiones son útiles. Habiendo seleccionado varias particiones, es útil volver a ejecutar el algoritmo varias veces para asegurar que se ha encontrado un mínimo global, en lugar de local.
El método comienza asignando aleatoriamente nodos a particiones. Se construye una medida de maldad de ajuste calculando las sumas de cuadrados para cada fila y cada columna dentro de cada bloque, y calculando la varianza de estas sumas de cuadrados. Estas varianzas se suman luego a través de los bloques para construir una medida de maldad de ajuste. La búsqueda continúa encontrando una asignación de actores a particiones que minimice esta estadística de maldad de ajuste.
Lo que se está minimizando es una función de la disimilitud de la varianza de puntuaciones dentro de las particiones. Es decir, el algoritmo busca agrupar actores que tengan cantidades similares de variabilidad en sus puntuaciones de fila y columna dentro de bloques. Los actores que tienen variabilidad similar probablemente tengan perfiles similares de vínculos enviados y recibidos dentro, y a través de bloques —aunque no necesariamente tienen los mismos vínculos con los mismos otros actores, es probable que tengan vínculos de la misma distancia con actores de otras clases.
Examinemos nuevamente la red de intercambio de información de las burocracias Knoke, esta vez buscando automorfismos. En los datos de información de Knoke no hay automorfismos exactos. Esto no es realmente sorprendente, dada la complejidad del patrón (y particularmente si distinguimos los in-ties de los out-ties) de las conexiones.
Ejecutamos la rutina varias veces, solicitando particiones en diferentes números de clases. La Figura 14.3 resume la “maldad de ajuste” de los modelos.
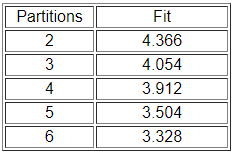
Figura 14.3: Ajuste de modelos de equivalencia automórfica a la red de información Knoke
No hay una respuesta “correcta” sobre cuántas clases hay. Hay dos respuestas triviales: las que agrupan todos los casos en una partición y las que separan cada caso en su propia partición. En el medio, uno podría querer seguir la lógica de la gráfica “scree” a partir del análisis factorial para seleccionar un número significativo de particiones. Observa primero los resultados de tres particiones (Figura 14.4).

Figura 14.4: Solución de equivalencia automórfica de 3 clases para la red de información Knoke
En este nivel de equivalencia aproximada, hay tres clases: dos individuos y un grupo grande. El periódico (actor 7) tiene bajas tasas de envío (fila) y altas tasas de recepción (columna); el alcalde (actor 5) tiene altas tasas de envío y altas tasas de recepción. Con sólo tres clases, el resto de los actores se agrupan en una clase aproximada con variabilidad aproximadamente igual (y mayor) tanto de envío como de recepción.
Debido a que la equivalencia automórfica opera realmente sobre el perfil de distancias de actores, tiende a identificar agrupaciones de actores que tienen patrones similares de entrada y salida grado. Esto va más allá de la equivalencia estructural (que enfatiza los vínculos con exactamente los mismos otros actores) a una idea más general y difusa de que dos actores son equivalentes si están embebidos de manera similar. El énfasis pasa de la posición individual, al papel de la posición en la estructura de toda la gráfica.
Equivalencia de distancias (MaxSim)
Cuando tenemos información sobre la fuerza, costo o probabilidad de relaciones (es decir, datos valorados), se podría esperar que la equivalencia automórfica exacta sea extremadamente rara. Pero, dado que la equivalencia automórfica enfatiza la similitud en el perfil de distancias de actores de otros, la idea de equivalencia aproximada puede aplicarse a los datos valorados. Redes>Roles y posiciones>Automorficía>MaxSim genera una matriz de “similitud” entre forma de las distribuciones de lazos de actores que se pueden agrupar agrupando y escalando en clases aproximadas. El enfoque también se puede aplicar a los datos binarios, si primero convertimos la matriz de adyacencia en una matriz de cercanía geodésica (que puede tratarse como una medida valorada de la fuerza de los lazos).
El algoritmo comienza con una distancia (recíproca de) o fuerza de la matriz de unión. Las distancias de cada actor se reorganizaron en una lista ordenada de baja a alta, y la distancia euclidiana se utiliza para calcular la disimilitud entre los perfiles de distancia de cada par de actores. El algoritmo califica a los actores que tienen perfiles de distancia similares como más equivalentes automorficamente. Nuevamente, la atención se centra en si el actor u tiene un conjunto similar de distancias, independientemente de qué distancias, a actor v. Una vez más, el escalado dimensional o el agrupamiento de las distancias se pueden utilizar para identificar conjuntos de actores aproximadamente automorficamente equivalentes.
Apliquemos esta idea a dos ejemplos, uno simple y abstracto, el otro más realista. Primero, veamos la red de “línea” (Figura 14.5).

Figura 14.5: Red de líneas
La Figura 14.6 muestra los resultados de analizar esta red con Redes>Roles y posiciones>Automorficía>MaxSim.
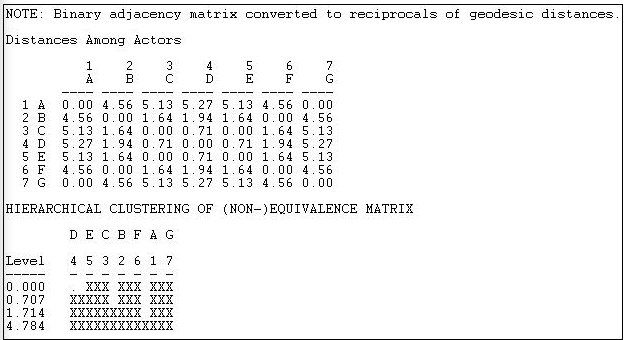
Figura 14.6: Equivalencia automórfica de distancias geodésicas en la red lineal
El primer paso es convertir la matriz de adyacencia en una matriz de distancia geodésica. Después se toma el recíproco de la distancia, y se produce un vector de las entradas de filas concatenadas con las entradas de columna para cada actor. Las distancias euclidianas entre estas listas se crean entonces como una medida de la equivalencia no automórfica, y se aplica la agrupación jerárquica.
Vemos que los actores 3 y 5 (C y E) forman una clase; los actores 2 y 6 (B y F) forman una clase; los actores 1 y 7 (A y G) forman una clase, y el actor 4 (D) es una clase. Matemáticamente, este es un resultado sensato; pueden ocurrir intercambios de etiquetas de actores dentro de estos conjuntos y todavía producir una matriz de distancia isomórfica. El resultado también tiene sentido sustantivo —y es bastante así para la red Wasserman-Fausto.
Este método de aproximación también se puede aplicar donde se valoran los datos. Si miramos nuestros datos sobre donantes a campañas políticas de California, tenemos medidas de la fuerza de los lazos entre los actores que son el número de posiciones en campañas que tienen en común cuando cualquiera de ellos contribuyó. La Figura 14.7 muestra parte de la salida de Redes>Roles y posiciones>Automorficía>MaxSIM .

Figura 14.7: Equivalencia automórfica aproximada de donantes políticos de California (truncada)
Esta pequeña parte de una gran pieza de producción (hay 100 donantes en la red) muestra que varios casinos no indios y pistas de carreras se agrupan, y separadamente de algunos otros donantes que se ocupan principalmente de temas educativos y ecológicos.
La identificación de clases de equivalencia aproximada en datos valorados puede ser útil para localizar grupos de actores que tienen una ubicación similar en la estructura de la gráfico en su conjunto. Al enfatizar los perfiles de distancia, sin embargo, es posible encontrar clases de actores que incluyen nodos que están bastante distantes entre sí, pero a una distancia similar a todos los demás actores. Es decir, actores que tienen posiciones similares en la red en su conjunto.