
5.6: Uso de Excel y R para una Regresión Lineal
- Page ID
- 75827

Si bien los cálculos de este capítulo son relativamente sencillos —consistentes, como lo hacen, principalmente en sumaciones— es tedioso resolver problemas usando nada más que una calculadora. Tanto Excel como R incluyen funciones para completar un análisis de regresión lineal y para evaluar visualmente el modelo resultante.
Excel
Usemos Excel para ajustar el siguiente modelo de línea recta a los datos del Ejemplo 5.4.1.
\[y = \beta_0 + \beta_1 x \nonumber\]
Ingresa los datos en una hoja de cálculo, como se muestra en la Figura 5.6.1 . Dependiendo de sus necesidades, hay muchas formas en las que puede usar Excel para completar un análisis de regresión lineal. Aquí consideraremos tres enfoques.
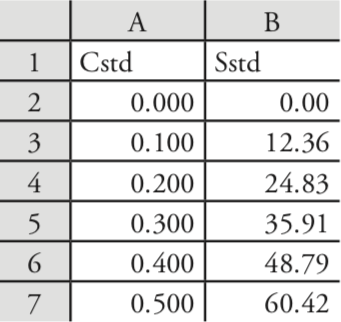
Uso de las funciones integradas de Excel
Si todo lo que necesitas son valores para la pendiente\(\beta_1\),, y la intersección y\(\beta_0\), puedes usar las siguientes funciones:
= intercept (conocido_y, conocido_x's)
= pendiente (conocido_y, conocido_x's)
donde conocido_y es el rango de celdas que contienen las señales (y), y conocido_x's es el rango de celdas que contienen las concentraciones (x). Por ejemplo, si hace clic en una celda vacía e ingresa
= pendiente (B2:B7, A2:A7)
Excel devuelve el cálculo exacto para la pendiente (120.705 714 3).
Uso de las herramientas de análisis de datos de Excel
Para obtener la pendiente y la intersección y, junto con detalles estadísticos adicionales, puede utilizar las herramientas de análisis de datos en la herramienta de análisis de datos. El ToolPak no es una parte estándar de la instilación de Excel. Para ver si tienes acceso a Analysis ToolPak en tu computadora, selecciona Herramientas en la barra de menús y busca el Análisis de Datos... opción. Si no ve Análisis de Datos... , seleccione Complementos... desde el menú Herramientas. Marque la casilla para el Análisis ToolPak y haga clic en Aceptar para instalarlos.
Seleccione Análisis de datos... desde el menú Herramientas, que abre la ventana Análisis de datos. Desplázate por la ventana, selecciona Regresión entre las opciones disponibles y presiona OK. Coloque el cursor en el cuadro de Rango Y de entrada y luego haga clic y arrastre sobre las celdas B1:B7. Coloque el cursor en el cuadro para Rango X de entrada y haga clic y arrastre sobre las celdas A1:A7. Debido a que las celdas A1 y B1 contienen etiquetas, marque la casilla de Etiquetas Adhesivas.
Incluir etiquetas es una buena idea. La salida de resumen de Excel utiliza la etiqueta del eje x para identificar la pendiente.
Seleccione el botón de radio para Rango de salida y haga clic en cualquier celda vacía; aquí es donde Excel colocará los resultados. Al hacer clic en Aceptar se genera la información que se muestra en la Figura 5.6.2 .
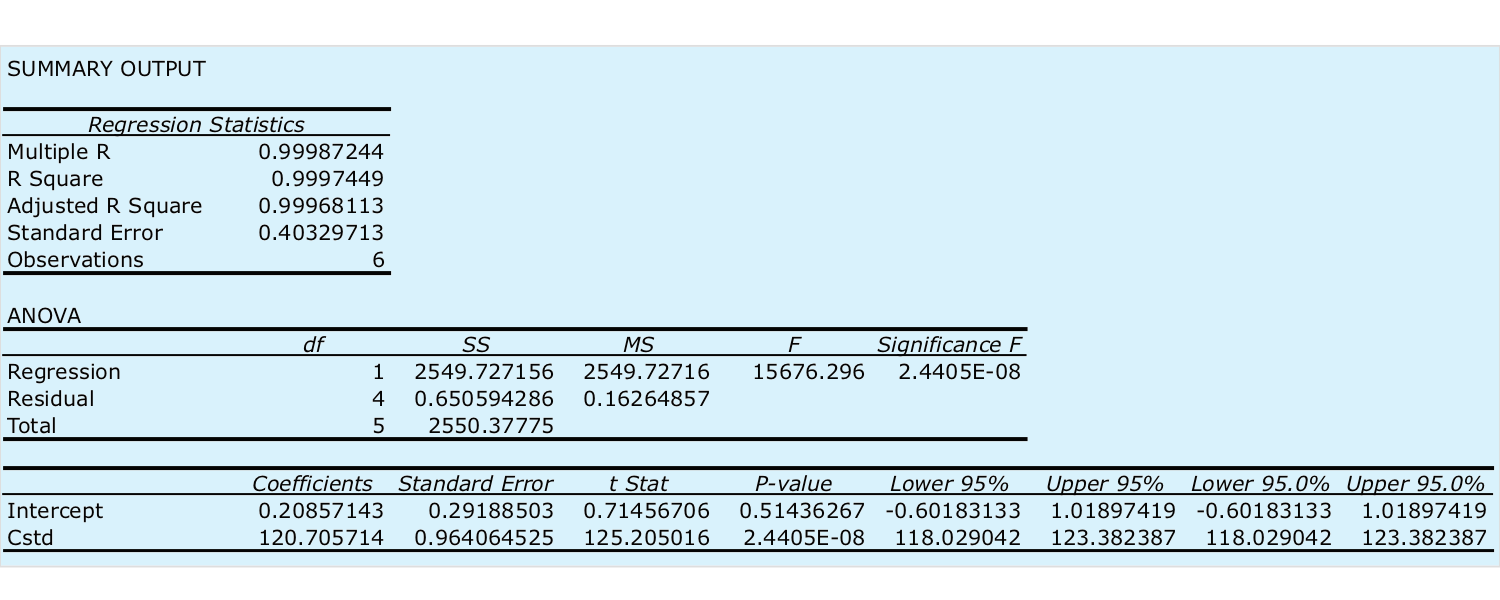
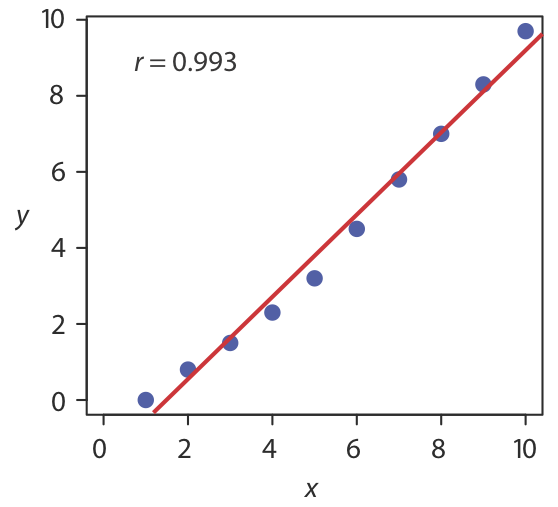
Hay tres partes en el resumen de Excel de un análisis de regresión. En la parte superior de la Figura 5.6.2 hay una tabla de Estadísticas de Regresión. El error estándar es la desviación estándar sobre la regresión, s r. También es de interés el valor para R múltiple, que es el coeficiente de correlación del modelo, r, un término con el que ya puede estar familiarizado. El coeficiente de correlación es una medida de la medida en que el modelo de regresión explica la variación en y. Los valores de r oscilan entre —1 y +1. Cuanto más cerca esté el coeficiente de correlación a ±1, mejor será el modelo para explicar los datos. Un coeficiente de correlación de 0 significa que no hay relación entre x e y. Al desarrollar los cálculos para regresión lineal, no se consideró el coeficiente de correlación. Hay una razón para ello. Para la mayoría de las curvas de calibración de línea recta el coeficiente de correlación es muy cercano a +1, típicamente 0.99 o mejor. Hay una tendencia, sin embargo, a poner demasiada fe en la significación del coeficiente de correlación, y a asumir que una r mayor a 0.99 significa que el modelo de regresión lineal es apropiado. La figura 5.6.3 proporciona un útil contraejemplo. Aunque la línea de regresión tiene un coeficiente de correlación de 0.993, los datos claramente son curvilíneos. La lección para llevar a casa aquí es simple: ¡no te enamores del coeficiente de correlación!
La segunda tabla de la Figura 5.6.2 se titula ANOVA, que significa análisis de varianza. Vamos a echar un vistazo más de cerca al ANOVA en el Capítulo 14. Por ahora, es suficiente entender que esta parte del resumen de Excel proporciona información sobre si el modelo de regresión lineal explica una parte significativa de la variación en los valores de y. El valor para F es el resultado de una prueba F de las siguientes hipótesis nulas y alternativas.
H 0: el modelo de regresión no explica la variación en y
H A: el modelo de regresión explica la variación en y
El valor en la columna para Significancia F es la probabilidad de retener la hipótesis nula. En este ejemplo, la probabilidad es\(2.5 \times 10^{-6}\%\), lo que es una fuerte evidencia para aceptar el modelo de regresión. Como es el caso del coeficiente de correlación, un valor pequeño para la probabilidad es un resultado probable para cualquier curva de calibración, incluso cuando el modelo es inapropiado. La probabilidad de retener la hipótesis nula para los datos de la Figura 5.6.3 , por ejemplo, es\(9.0 \times 10^{-7}\%\).
Consulte el Capítulo 4.6 para una revisión de la prueba F.
La tercera tabla en la Figura 5.6.2 proporciona un resumen del modelo en sí. Los valores de los coeficientes del modelo, la pendiente\(\beta_1\), y la intersección y,\(\beta_0\) se identifican como intercepción y con su etiqueta para los datos del eje x, que en este ejemplo es C std. Las desviaciones estándar para los coeficientes,\(s_{b_0}\) y\(s_{b_1}\), están en la columna etiquetada Error estándar. La columna t Stat y el valor P de la columna son para las siguientes pruebas t.
pendiente:\(H_0 \text{: } \beta_1 = 0 \quad H_A \text{: } \beta_1 \neq 0\)
y -interceptar:\(H_0 \text{: } \beta_0 = 0 \quad H_A \text{: } \beta_0 \neq 0\)
Los resultados de estas pruebas t proporcionan evidencia convincente de que la pendiente no es cero, pero no hay evidencia de que la intersección y difiera significativamente de cero. También se muestran los intervalos de confianza de 95% para la pendiente y la intersección y (inferior 95% y superior 95%).
Consulte el Capítulo 4.6 para una revisión de la prueba t.
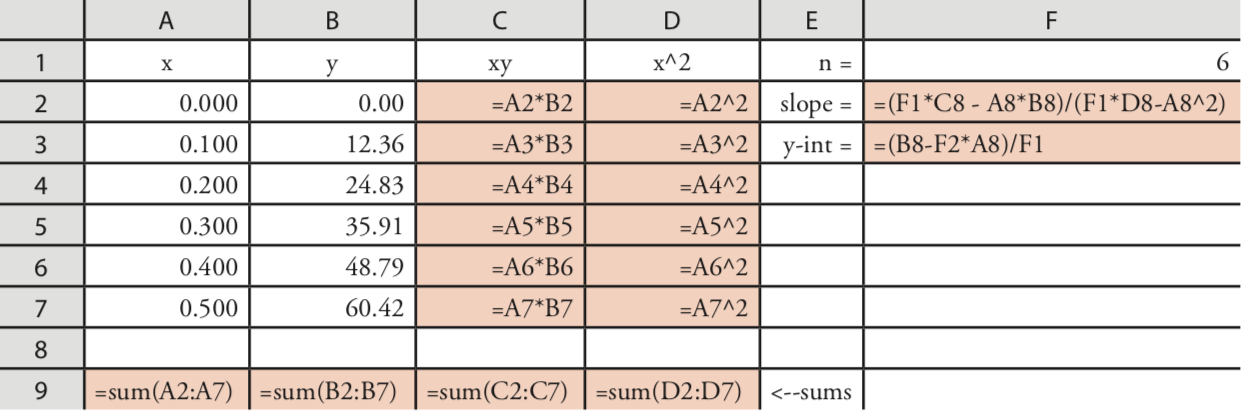
Programando las Fórmulas Usted
Un tercer enfoque para completar un análisis de regresión es programar una hoja de cálculo utilizando la fórmula incorporada de Excel para una suma
=sum (primera celda: última celda)
y su capacidad para analizar ecuaciones matemáticas. La hoja de cálculo resultante se muestra en la Figura 5.6.4 .
Uso de Excel para visualizar el modelo de regresión
Puedes usar Excel para examinar tus datos y la línea de regresión. Comience por trazar los datos. Organiza tus datos en dos columnas, colocando los valores x en la columna más a la izquierda. Haga clic y arrastre sobre los datos y seleccione Gráficos en la cinta. Seleccione Dispersión, eligiendo la opción sin líneas que conecten los puntos. Para agregar una línea de regresión al gráfico, haga clic en los datos del gráfico y seleccione Gráfico: Agregar Línea de tendencia... de los hombres principales. Elija el modelo de línea recta y haga clic en Aceptar para agregar la línea a su gráfico. Por defecto, Excel muestra la línea de regresión desde su primer punto hasta su último punto. La Figura 5.6.5 muestra el resultado para los datos de la Figura 5.6.1 .
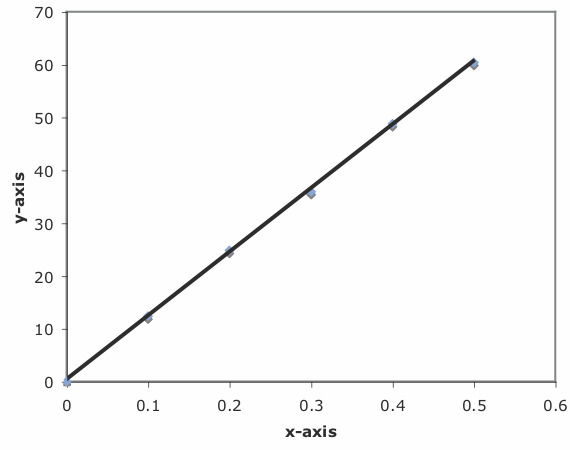
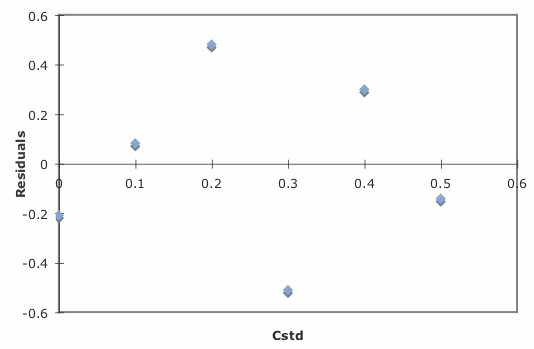
Excel también creará una gráfica de los errores residuales del modelo de regresión. Para crear la gráfica, construya el modelo de regresión utilizando la herramienta Analysis ToolPak, como se describió anteriormente. Al hacer clic en la opción de Gráficas residuales se crea la gráfica que se muestra en la Figura 5.6.6 .
Limitaciones al Uso de Excel para un Análisis de Regresión
La mayor limitación de Excel para un análisis de regresión es que no proporciona una función para calcular la incertidumbre al predecir valores de x. En términos de este capítulo, Excel no puede calcular la incertidumbre para la concentración del analito, C A, dada la señal para una muestra, S samp. Otra limitación es que Excel no tiene una función incorporada para una regresión lineal ponderada. Sin embargo, puede programar una hoja de cálculo para manejar estos cálculos.
Utilice Excel para completar el análisis de regresión en el Ejercicio 5.4.1.
- Contestar
-
Comience ingresando los datos en una hoja de cálculo Excel, siguiendo el formato que se muestra en la Figura 5.6.1 . Debido a que las herramientas de Análisis de Datos de Excel proporcionan la mayor parte de la información que necesitamos, la usaremos aquí. La salida resultante, que se muestra a continuación, proporciona la pendiente y la intersección y, junto con sus respectivos intervalos de confianza del 95%.
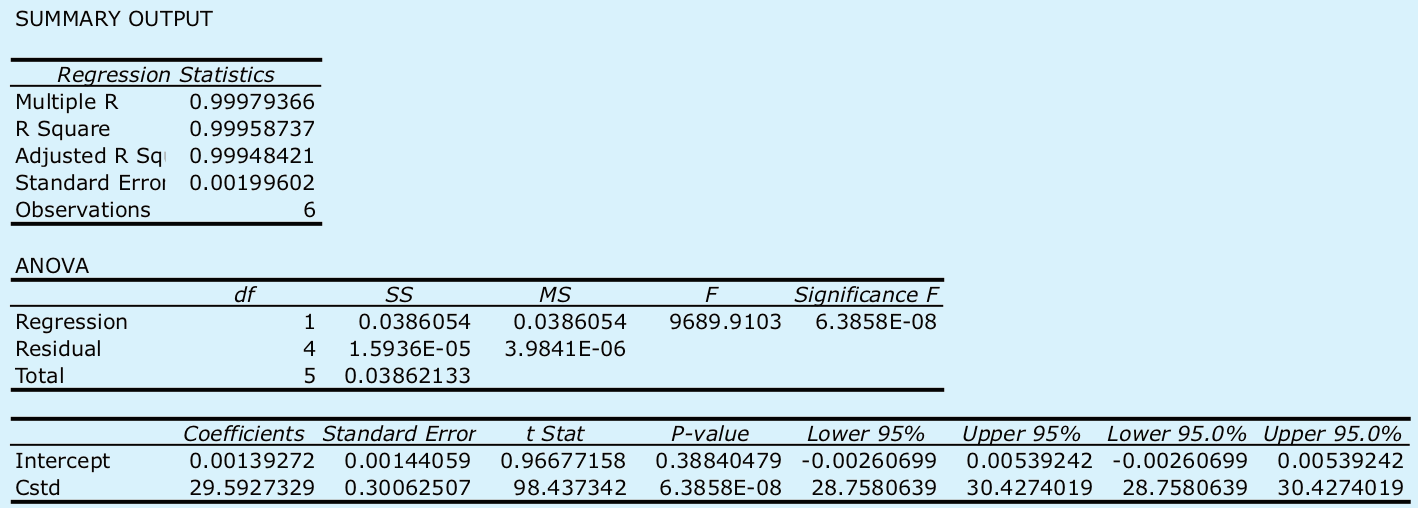
Excel no proporciona una función para calcular la incertidumbre en la concentración del analito, C A, dada la señal para una muestra, S samp. Debes completar estos cálculos a mano. Con una muestra S de 0.114, encontramos que C A es
\[C_A = \frac {S_{samp} - b_0} {b_1} = \frac {0.114 - 0.0014} {29.59 \text{ M}^{-1}} = 3.80 \times 10^{-3} \text{ M} \nonumber\]
La desviación estándar en C A es
\[s_{C_A} = \frac {1.996 \times 10^{-3}} {29.59} \sqrt{\frac {1} {3} + \frac {1} {6} + \frac {(0.114 - 0.1183)^2} {(29.59)^2 \times 4.408 \times 10^{-5})}} = 4.772 \times 10^{-5} \nonumber\]
y el intervalo de confianza del 95% es
\[\mu = C_A \pm ts_{C_A} = 3.80 \times 10^{-3} \pm \{2.78 \times (4.772 \times 10^{-5}) \} \nonumber\]
\[\mu = 3.80 \times 10^{-3} \text{ M} \pm 0.13 \times 10^{-3} \text{ M} \nonumber\]
R
Usemos R para ajustar el siguiente modelo de línea recta a los datos del Ejemplo 5.4.1.
\[y = \beta_0 + \beta_1 x \nonumber\]
Introducción de datos y creación del modelo de regresión
Para comenzar, cree objetos que contengan la concentración de los estándares y sus señales correspondientes.
> conc = c (0, 0.1, 0.2, 0.3, 0.4, 0.5)
> señal = c (0, 12.36, 24.83, 35.91, 48.79, 60.42)
El comando para un modelo de regresión lineal lineal es
lm (y ~ x)
donde y y x son los objetos los objetos nuestros datos. Para acceder a los resultados del análisis de regresión, los asignamos a un objeto usando el siguiente comando
> modelo = lm (señal ~ conc)
donde model es el nombre que asignamos al objeto.
Como se puede adivinar, lm es la abreviatura de modelo lineal.
Puede elegir cualquier nombre para el objeto que contenga los resultados del análisis de regresión.
Evaluación del Modelo de Regresión Lineal
Para evaluar los resultados de una regresión lineal necesitamos examinar los datos y la línea de regresión, y revisar un resumen estadístico del modelo. Para examinar nuestros datos y la línea de regresión, utilizamos el comando plot, que toma la siguiente forma general
plot (x, y, argumentos opcionales para controlar el estilo)
donde x e y son los objetos que contienen nuestros datos, y el comando abline
abline (objeto, argumentos opcionales para controlar el estilo)
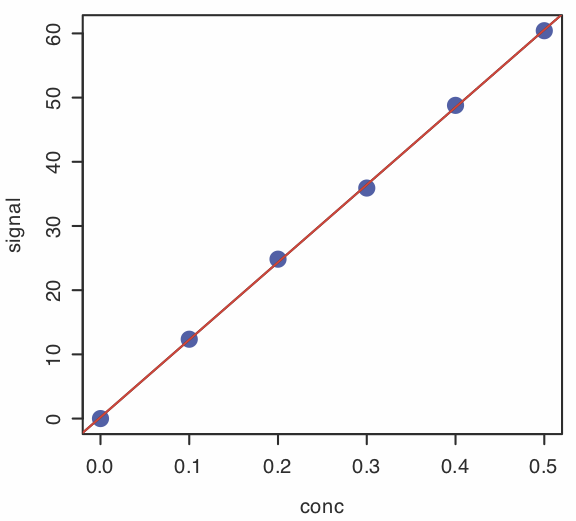
donde object es el objeto que contiene los resultados de la regresión lineal. Ingresando los comandos
> parcela (conc, señal, pch = 19, col = “azul”, cex = 2)
> abline (modelo, col = “rojo”)
crea la gráfica mostrada en la Figura 5.6.7 .
Para revisar un resumen estadístico del modelo de regresión, utilizamos el comando summary.
> resumen (modelo)
La salida resultante, mostrada en la Figura 5.6.8 , contiene tres secciones.

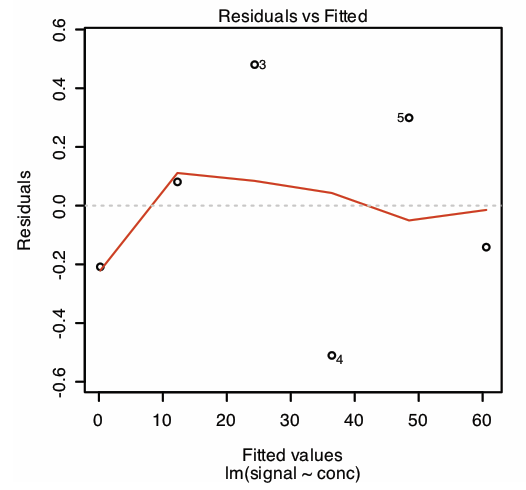
La primera sección del resumen de R del modelo de regresión enumera los errores residuales. Para examinar una gráfica de los errores residuales, utilice el comando
> plot (modelo, que = 1)
que produce el resultado mostrado en la Figura 5.6.9 . Tenga en cuenta que R traza los residuos contra los valores predichos (ajustados) de y en lugar de contra los valores conocidos de x. La elección de cómo trazar los residuos no es crítica, como se puede ver comparando la Figura 5.6.9 con la Figura 5.6.6 . La línea en la Figura 5.6.9 es un ajuste suavizado de los residuos.
La razón para incluir el argumento que = 1 no es inmediatamente evidente. Cuando se utiliza el comando de trazado de R en un objeto creado por el comando lm, el valor predeterminado es crear cuatro gráficos que resuman la idoneidad del modelo. La primera de estas gráficas es la gráfica residual; así, que = 1 limita la salida a esta gráfica.
La segunda sección de la Figura 5.6.8 proporciona los coeficientes del modelo, la pendiente\(\beta_1\), y la intersección y,\(\beta_0\) junto con sus respectivas desviaciones estándar (Std. Error). El valor de la columna t y la columna Pr (>|t|) son para las siguientes pruebas t.
pendiente:\(H_0 \text{: } \beta_1 = 0 \quad H_A \text{: } \beta_1 \neq 0\)
y -interceptar:\(H_0 \text{: } \beta_0 = 0 \quad H_A \text{: } \beta_0 \neq 0\)
Los resultados de estas pruebas t proporcionan evidencia convincente de que la pendiente no es cero, pero ninguna evidencia de que la intersección y difiera significativamente de cero.
La última sección del resumen de regresión proporciona la desviación estándar sobre la regresión (error estándar residual), el cuadrado del coeficiente de correlación (R-cuadrado múltiple) y el resultado de una prueba F sobre la capacidad del modelo para explicar la variación en el y valores. Para una discusión sobre el coeficiente de correlación y la prueba F de un modelo de regresión, así como sus limitaciones, consulte la sección sobre el uso de las herramientas de análisis de datos de Excel.
Predecir la incertidumbre en\(C_A\) Given\(S_{samp}\)
A diferencia de Excel, R incluye un comando para predecir la incertidumbre en la concentración de un analito, C A, dada la señal para una muestra, S samp. Este comando no forma parte de la instalación estándar de R. Para usar el comando es necesario instalar el paquete “ChemCal” ingresando el siguiente comando (nota: necesitará una conexión a internet para descargar el paquete).
> instalar.paquetes (“ChemCal”)
Después de instalar el paquete, debe cargar las funciones en R usando el siguiente comando. (nota: deberá realizar este paso cada vez que inicie una nueva sesión R ya que el paquete no se carga automáticamente cuando inicia R).
> biblioteca (“ChemCal”)
Necesitas instalar un paquete una vez, pero debes cargarlo cada vez que planeas usarlo. Hay formas de configurar R para que cargue automáticamente ciertos paquetes; consulte Una introducción a R para obtener más información (haga clic aquí para ver una versión PDF de este documento).
El comando para predecir la incertidumbre en C A es inverse.predict, que toma la siguiente forma para una regresión lineal no ponderada
inverse.predict (objeto, newdata, alfa = valor)
donde object es el objeto que contiene los resultados del modelo de regresión, new-data es un objeto que contiene valores para S samp y value es el valor numérico para el nivel de significancia. Usemos este comando para completar el Ejemplo 5.4.3. Primero, creamos un objeto que contiene los valores de S samp
> muestra = c (29.32, 29.16, 29.51)
y luego completamos el cómputo usando el siguiente comando
> inverse.predict (modelo, muestra, alfa = 0.05)
produciendo el resultado mostrado en la Figura 5.6.10 . La concentración del analito, C A, viene dada por el valor $Predicción, y su desviación estándar,\(s_{C_A}\), se muestra como $`Error estándar`. El valor para $Confidence es el intervalo de confianza\(\pm t s_{C_A}\),, para la concentración del analito, y $`Confidence Limits` proporciona el límite inferior y el límite superior para el intervalo de confianza para C A.
Uso de R para una regresión lineal ponderada
El comando de R para una regresión lineal no ponderada también permite una regresión lineal ponderada si incluimos un argumento adicional, pesos, cuyo valor es un objeto que contiene los pesos.
lm (y ~ x, pesos = objeto)
Usemos este comando para completar el Ejemplo 5.4.4. Primero, necesitamos crear un objeto que contenga los pesos, que en R son los recíprocos de las desviaciones estándar en y,\((s_{y_i})^{-2}\). Usando los datos del Ejemplo 5.4.4, ingresamos
> syi=c (0.02, 0.02, 0.07, 0.13, 0.22, 0.33)
> w=1/syi^2
para crear el objeto que contiene los pesos. Los comandos
> modelw= lm (señal ~ conc, pesos = w)
> resumen (modelw)
generar la salida mostrada en la Figura 5.6.11 . Cualquier diferencia entre los resultados mostrados aquí y los resultados mostrados en el Ejemplo 5.4.4 son el resultado de errores de redondeo en nuestros cálculos anteriores.
Es posible que hayas notado que esta forma de definir pesos es diferente a la que se muestra en la Ecuación 5.4.15. Al derivar ecuaciones para una regresión lineal ponderada, puede optar por normalizar la suma de los pesos para igualar el número de puntos, o puede elegir no hacerlo; el algoritmo en R no normaliza los pesos.

Utilice R para completar el análisis de regresión en el Ejercicio 5.4.1.
- Contestar
-
La siguiente figura muestra la sesión R para este problema, incluida la carga del paquete ChemCal, la creación de objetos para contener los valores de C std, S std y S samp. Tenga en cuenta que para S samp, no tenemos los valores reales para las tres mediciones replicadas. En lugar de las mediciones reales, solo ingresamos la señal promedio tres veces. Esto está bien porque el cálculo depende de la señal promedio y del número de réplicas, y no de las mediciones individuales.
