
6.3: Acondicionamiento Operante
- Page ID
- 149213

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)| Acondicionamiento Clásico | Acondicionamiento Operante | |
|---|---|---|
| Enfoque de acondicionamiento | Un estímulo incondicionado (como la comida) se combina con un estímulo neutro (como una campana). El estímulo neutro finalmente se convierte en el estímulo condicionado, lo que provoca la respuesta condicionada (salivación). | El comportamiento objetivo es seguido de refuerzo o castigo para fortalecerlo o debilitarlo, de manera que el alumno tenga más probabilidades de exhibir el comportamiento deseado en el futuro. |
| Momento de estímulo | El estímulo ocurre inmediatamente antes de la respuesta. | El estímulo (ya sea refuerzo o castigo) ocurre poco después de la respuesta. |
El psicólogo B. F. Skinner vio que el condicionamiento clásico se limita a comportamientos existentes que se provocan reflexivamente, y no da cuenta de nuevos comportamientos como andar en bicicleta. Propuso una teoría sobre cómo se producen tales comportamientos. Skinner creía que el comportamiento está motivado por las consecuencias que recibimos por el comportamiento: los refuerzos y castigos. Su idea de que el aprendizaje es resultado de consecuencias se basa en la ley de efecto, la cual fue propuesta por primera vez por el psicólogo Edward Thorndike. De acuerdo con la ley del efecto, los comportamientos que van seguidos de consecuencias que son satisfactorias para el organismo tienen más probabilidades de repetirse, y los comportamientos que van seguidos de consecuencias desagradables tienen menos probabilidades de repetirse (Thorndike, 1911). Esencialmente, si un organismo hace algo que produce un resultado deseado, es más probable que el organismo vuelva a hacerlo. Si un organismo hace algo que no produce un resultado deseado, es menos probable que el organismo vuelva a hacerlo. Un ejemplo de la ley de efectos es en el empleo. Una de las razones (y muchas veces la razón principal) por las que nos presentamos al trabajo es porque nos pagan por hacerlo. Si dejamos de recibir pagos, es probable que dejemos de presentarnos, incluso si amamos nuestro trabajo.
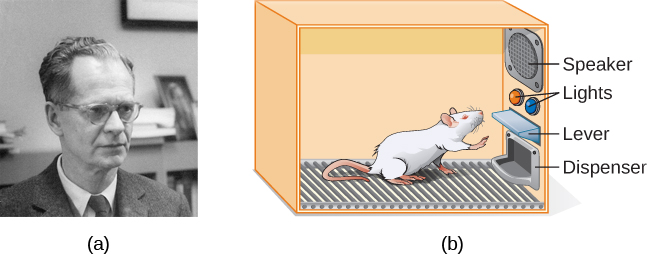
Trabajando con la ley de efecto de Thorndike como su fundamento, Skinner comenzó a realizar experimentos científicos en animales (principalmente ratas y palomas) para determinar cómo los organismos aprenden a través del condicionamiento operante (Skinner, 1938). Colocó a estos animales dentro de una cámara de acondicionamiento operante, la cual ha llegado a conocerse como “Caja Skinner” (Figura 6.10). Una caja de Skinner contiene una palanca (para ratas) o disco (para palomas) que el animal puede presionar o picotear para obtener una recompensa de comida a través del dispensador. Altavoces y luces pueden estar asociados con ciertos comportamientos. Un registrador cuenta el número de respuestas realizadas por el animal.
| Refuerzo y castigo positivo y negativo | ||
|---|---|---|
| Refuerzo | Castigo | |
| Positivo | Se agrega algo para aumentar la probabilidad de un comportamiento. | Se agrega algo para disminuir la probabilidad de un comportamiento. |
| Negativo | Algo se elimina para aumentar la probabilidad de un comportamiento. | Algo se elimina para disminuir la probabilidad de un comportamiento. |
Refuerzo
La forma más efectiva de enseñar a una persona o animal un nuevo comportamiento es con un refuerzo positivo. En refuerzo positivo, se agrega un estímulo deseable para incrementar un comportamiento.
Por ejemplo, le dices a tu hijo de cinco años, Jerome, que si limpia su habitación, obtendrá un juguete. Jerome limpia rápidamente su habitación porque quiere un nuevo set de arte. Hagamos una pausa por un momento. Algunas personas podrían decir: “¿Por qué debería recompensar a mi hijo por hacer lo que se espera?” Pero de hecho somos constantemente y consistentemente recompensados en nuestras vidas. Nuestros cheques de pago son recompensas, así como las calificaciones altas y la aceptación en nuestra escuela preferida. Ser elogiado por hacer un buen trabajo y por aprobar una prueba de manejo también es una recompensa. El refuerzo positivo como herramienta de aprendizaje es extremadamente efectivo. Se ha encontrado que una de las formas más efectivas de aumentar el rendimiento en distritos escolares con puntajes de lectura por debajo del promedio fue pagar a los niños para que lean. Específicamente, a los estudiantes de segundo grado en Dallas se les pagaba 2 dólares cada vez que leían un libro y pasaban un breve cuestionario sobre el libro. El resultado fue un incremento significativo en la comprensión lectora (Fryer, 2010). ¿Qué opinas de este programa? Si Skinner estuviera vivo hoy, probablemente pensaría que esta fue una gran idea. Fue un firme defensor del uso de principios de condicionamiento operante para influir en el comportamiento de los estudiantes en la escuela. De hecho, además de la caja de Skinner, también inventó lo que llamó una máquina de enseñanza que fue diseñada para recompensar pequeños pasos en el aprendizaje (Skinner, 1961) —un precursor temprano del aprendizaje asistido por computadora. Su máquina de enseñanza probó los conocimientos de los estudiantes mientras trabajaban en diversas materias escolares. Si los alumnos respondían correctamente las preguntas, recibían un refuerzo positivo inmediato y podían continuar; si respondían incorrectamente, no recibían ningún refuerzo. La idea era que los estudiantes dedicaran más tiempo a estudiar el material para aumentar sus posibilidades de ser reforzados la próxima vez (Skinner, 1961).
En el refuerzo negativo, se elimina un estímulo indeseable para aumentar un comportamiento. Por ejemplo, los fabricantes de automóviles utilizan los principios de refuerzo negativo en sus sistemas de cinturones de seguridad, que van “pitido, pitido, pitido” hasta que se abrocha el cinturón de seguridad. El molesto sonido se detiene cuando exhibes el comportamiento deseado, aumentando la probabilidad de que te abroches el cinturón en el futuro. El refuerzo negativo también se usa frecuentemente en el entrenamiento de caballos. Los jinetes aplican presión, tirando de las riendas o apretando sus piernas, y luego eliminan la presión cuando el caballo realiza el comportamiento deseado, como girar o acelerar. La presión es el estímulo negativo que el caballo quiere eliminar.
Castigo
Muchas personas confunden el refuerzo negativo con el castigo en el condicionamiento operante, pero son dos mecanismos muy diferentes. Recuerda que el refuerzo, incluso cuando es negativo, siempre aumenta un comportamiento. En contraste, el castigo siempre disminuye un comportamiento. En castigo positivo, se agrega un estímulo indeseable para disminuir un comportamiento. Un ejemplo de castigo positivo es regañar a un estudiante para que el estudiante deje de enviar mensajes de texto en clase. En este caso, se agrega un estímulo (la reprimenda) para disminuir el comportamiento (enviar mensajes de texto en clase). En castigo negativo, se quita un estímulo agradable para disminuir el comportamiento. Por ejemplo, cuando un niño se porta mal, un padre puede llevarse un juguete favorito. En este caso, se retira un estímulo (el juguete) para disminuir el comportamiento.
El castigo, sobre todo cuando es inmediato, es una forma de disminuir el comportamiento indeseable. Por ejemplo, imagina que tu hijo de cuatro años, Brandon, golpeó a su hermano menor. Tienes a Brandon escribir 100 veces “No voy a golpear a mi hermano” (castigo positivo). Lo más probable es que no repita este comportamiento. Si bien estrategias como esta son comunes hoy en día, en el pasado los niños a menudo estaban sujetos a castigos físicos, como las nalgadas. Es importante estar al tanto de algunos de los inconvenientes en el uso del castigo físico a los niños. Primero, el castigo puede enseñar miedo. Brandon puede tener miedo de la calle, pero también puede tener miedo de la persona que entregó el castigo, usted, su padre. De igual manera, los niños que son castigados por los maestros pueden llegar a temer al maestro y tratar de evitar la escuela (Gershoff et al., 2010). En consecuencia, la mayoría de las escuelas en Estados Unidos han prohibido los castigos corporales. Segundo, el castigo puede hacer que los niños se vuelvan más agresivos y propensos a la conducta antisocial y la delincuencia (Gershoff, 2002). Ven que sus padres recurren a las nalgadas cuando se enojan y se frustran, por lo que, a su vez, pueden representar este mismo comportamiento cuando se enojan y se frustran. Por ejemplo, porque le das una paliza a Brenda cuando estás enfadada con ella por su mala conducta, podría empezar a golpear a sus amigas cuando no compartan sus juguetes.
Si bien el castigo positivo puede ser efectivo en algunos casos, Skinner sugirió que el uso del castigo debe sopesarse contra los posibles efectos negativos. Los psicólogos y expertos en crianza de los hijos de hoy favorecen el refuerzo sobre el castigo; recomiendan que atrapes a tu hijo haciendo algo bueno y recompensarlo por ello.
Dar forma
En sus experimentos de condicionamiento operante, Skinner solía utilizar un enfoque llamado conformación. En lugar de recompensar solo el comportamiento objetivo, en la conformación, recompensamos sucesivas aproximaciones de un comportamiento objetivo. ¿Por qué se necesita dar forma? Recuerda que para que el refuerzo funcione, el organismo primero debe mostrar el comportamiento. La conformación es necesaria porque es extremadamente improbable que un organismo muestre algo más que el más simple de los comportamientos de forma espontánea. En la conformación, los comportamientos se desglosan en muchos pasos pequeños y alcanzables. Los pasos específicos utilizados en el proceso son los siguientes:
La conformación se usa a menudo en la enseñanza de un comportamiento complejo o una cadena de comportamientos. Skinner solía modelar para enseñar a las palomas no solo comportamientos relativamente simples como picotear un disco en una caja de Skinner, sino también muchos comportamientos inusuales y entretenidos, como dar vueltas en círculos, caminar en figura ochos e incluso jugar al ping pong; la técnica es comúnmente utilizada por los entrenadores de animales hoy en día. Una parte importante de la conformación es la discriminación por estímulos. Recordemos a los perros de Pavlov, los entrenó para responder al tono de una campana, y no a tonos o sonidos similares. Esta discriminación también es importante en el condicionamiento operante y en la conformación del comportamiento.
Es fácil ver cómo la conformación es efectiva para enseñar comportamientos a los animales, pero ¿cómo funciona la conformación con los humanos? Consideremos a los padres cuyo objetivo es que su hijo aprenda a limpiar su habitación. Utilizan la conformación para ayudarle a dominar los pasos hacia la meta. En lugar de realizar toda la tarea, configuran estos pasos y refuerzan cada paso. Primero, limpia un juguete. Segundo, limpia cinco juguetes. Tercero, elige si recoger diez juguetes o guardar sus libros y ropa. Cuarto, limpia todo excepto dos juguetes. Por último, limpia toda su habitación.
Refuerzos Primarios y Secundarios
Recompensas como pegatinas, elogios, dinero, juguetes y más se pueden usar para reforzar el aprendizaje. Volvamos a las ratas de Skinner otra vez. ¿Cómo aprendieron las ratas a presionar la palanca en la caja de Skinner? Fueron recompensados con comida cada vez que presionaban la palanca. Para los animales, la comida sería un evidente reforzador.
¿Cuál sería un buen reforzador para los humanos? Para tu hijo Chris, era la promesa de un juguete cuando limpiaban su habitación. ¿Qué tal Sydney, el futbolista? Si le diste un caramelo a Sydney cada vez que Sydney anotaba un gol, estarías usando un reforzador primario. Los refuerzos primarios son refuerzos que tienen cualidades de refuerzo innatas. Este tipo de refuerzos no se aprenden. El agua, la comida, el sueño, el refugio, el sexo y el tacto, entre otros, son los principales reforzadores. El placer también es un reforzador principal. Los organismos no pierden su impulso por estas cosas. Para la mayoría de la gente, saltar en un lago fresco en un día muy caluroso sería reforzar y el lago fresco se reforzaría de manera innata: el agua enfriaría a la persona (una necesidad física), además de brindar placer.
Un reforzador secundario no tiene valor inherente y solo tiene cualidades de refuerzo cuando se vincula con un reforzador primario. La alabanza, ligada al afecto, es un ejemplo de un reforzador secundario, como cuando gritabas “¡Gran tiro!” cada vez que Sydney hacía un gol. Otro ejemplo, el dinero, solo vale algo cuando puedes usarlo para comprar otras cosas—ya sea cosas que satisfagan necesidades básicas (comida, agua, refugio— todos los refuerzos primarios) u otros reforzadores secundarios. Si estuvieras en una isla remota en medio del Océano Pacífico y tuvieras pilas de dinero, el dinero no sería útil si no pudieras gastarlo. ¿Qué pasa con las pegatinas en la tabla de comportamiento? También son reforzadores secundarios.
A veces, en lugar de pegatinas en una tabla de pegatinas, se usa una ficha. Los tokens, que también son reforzadores secundarios, se pueden canjear por recompensas y premios. Los sistemas completos de gestión del comportamiento, conocidos como economías de tokens, se construyen en torno al uso de este tipo de refuerzos de tokens. Se ha encontrado que las economías simbólicas son muy efectivas para modificar el comportamiento en una variedad de entornos como escuelas, prisiones y hospitales psiquiátricos. Por ejemplo, un estudio de Cangi y Daly (2013) encontró que el uso de una economía simbólica incrementó los comportamientos sociales apropiados y redujo los comportamientos inapropiados en un grupo de escolares autistas. Los niños autistas tienden a exhibir comportamientos disruptivos como pellizcar y golpear. Cuando los niños en el estudio exhibieron un comportamiento apropiado (no golpear ni pellizcar), recibieron una ficha de “manos tranquilas”. Cuando golpearon o pellizcaron, perdieron una ficha. Los niños podrían entonces intercambiar cantidades específicas de fichas por minutos de tiempo de juego.

El tiempo de espera es otra técnica popular utilizada en la modificación del comportamiento con niños. Opera bajo el principio de castigo negativo. Cuando un niño demuestra un comportamiento indeseable, se le retira de la actividad deseable que tiene a mano (Figura 6.12). Por ejemplo, decir que Sophia y su hermano Mario están jugando con bloques de construcción. Sophia le tira unos bloqueos a su hermano, así que le das una advertencia de que irá a tiempo muerto si lo vuelve a hacer. A los pocos minutos, le lanza más bloqueos a Mario. Quitas a Sophia de la habitación por unos minutos. Cuando regresa, no tira bloques.
Hay varios puntos importantes que debes conocer si planeas implementar el tiempo de espera como técnica de modificación de comportamiento. Primero, asegúrese de que el niño esté siendo retirado de una actividad deseable y colocado en un lugar menos deseable. Si la actividad es algo indeseable para el niño, esta técnica será contraproducente porque es más agradable que el niño sea removido de la actividad. En segundo lugar, la duración del tiempo de espera es importante. La regla general es de un minuto por cada año de la edad del niño. Sophia tiene cinco años; por lo tanto, se sienta en un tiempo de espera durante cinco minutos. Configurar un temporizador ayuda a los niños a saber cuánto tiempo tienen que sentarse en el tiempo de espera. Finalmente, como cuidador, tenga en cuenta varias pautas en el transcurso de un tiempo de descanso: mantenga la calma al dirigir a su hijo al tiempo de descanso; ignore a su hijo durante el tiempo de descanso (porque la atención del cuidador puede reforzar el mal comportamiento); y darle al niño un abrazo o una palabra amable cuando termine el tiempo muerto.

Horarios de Refuerzo
Recuerda, la mejor manera de enseñarle a una persona o animal un comportamiento es usar el refuerzo positivo. Por ejemplo, Skinner usó refuerzo positivo para enseñar a las ratas a presionar una palanca en una caja de Skinner. Al principio, la rata podría golpear aleatoriamente la palanca mientras exploraba la caja, y saldría una bolita de comida. Después de comerse el pellet, ¿qué crees que hizo después la rata hambrienta? Volvió a golpear la palanca, y recibió otra bolita de comida. Cada vez que la rata golpeaba la palanca, salía una bolita de comida. Cuando un organismo recibe un reforzador cada vez que muestra un comportamiento, se le llama refuerzo continuo. Este horario de refuerzo es la forma más rápida de enseñar a alguien un comportamiento, y es especialmente efectivo en el entrenamiento de una nueva conducta. Echemos un vistazo al perro que estaba aprendiendo a sentarse antes en el capítulo. Ahora, cada vez que se sienta, le das una golosina. El tiempo es importante aquí: tendrás más éxito si presentas al reforzador inmediatamente después de que se siente, para que pueda hacer una asociación entre el comportamiento objetivo (sentado) y la consecuencia (recibir un regalo).
| Horarios de Refuerzo | |||
|---|---|---|---|
| Horario de Refuerzo | Descripción | Resultado | Ejemplo |
| Intervalo fijo | El refuerzo se entrega a intervalos de tiempo predecibles (por ejemplo, después de 5, 10, 15 y 20 minutos). | Tasa de respuesta moderada con pausas significativas después del refuerzo | Paciente hospitalario utiliza alivio del dolor controlado por el paciente y programado por el médico |
| Intervalo variable | El refuerzo se entrega a intervalos de tiempo impredecibles (por ejemplo, después de 5, 7, 10 y 20 minutos). | Tasa de respuesta moderada pero constante | Comprobando Facebook |
| Relación fija | El refuerzo se entrega después de un número predecible de respuestas (por ejemplo, después de 2, 4, 6 y 8 respuestas). | Alta tasa de respuesta con pausas después del refuerzo | Trabajo a destajo: trabajador de fábrica que recibe el pago por cada x número de artículos fabricados |
| Relación variable | El refuerzo se entrega después de un número impredecible de respuestas (por ejemplo, después de 1, 4, 5 y 9 respuestas). | Tasa de respuesta alta y constante | Juegos de azar |
Ahora vamos a combinar estos cuatro términos. Un programa de refuerzo de intervalo fijo es cuando el comportamiento se recompensa después de una cantidad de tiempo establecida. Por ejemplo, June se somete a una cirugía mayor en un hospital. Durante la recuperación, se espera que experimente dolor y requerirá medicamentos recetados para aliviar el dolor. A junio se le administra un goteo intravenoso con un analgésico controlado por el paciente. Su médico establece un límite: una dosis por hora. June presiona un botón cuando el dolor se vuelve difícil, y recibe una dosis de medicamento. Dado que la recompensa (alivio del dolor) solo ocurre en un intervalo fijo, no tiene sentido exhibir el comportamiento cuando no será recompensado.
Con un horario de refuerzo de intervalo variable, la persona o animal obtiene el refuerzo en función de diferentes cantidades de tiempo, que son impredecibles. Digamos que Manuel es el encargado de un restaurante de comida rápida. De vez en cuando alguien de la división de control de calidad viene al restaurante de Manuel. Si el restaurante está limpio y el servicio es rápido, todos en ese turno ganan un bono de 20 dólares. Manuel nunca sabe cuándo aparecerá la persona de control de calidad, por lo que siempre trata de mantener limpio el restaurante y se asegura de que sus empleados brinden un servicio rápido y cortés. Su productividad en cuanto a un servicio rápido y mantener un restaurante limpio es constante porque quiere que su tripulación gane el bono.
Con un cronograma de refuerzo de ratio fijo, hay un número determinado de respuestas que deben ocurrir antes de que el comportamiento sea recompensado. Carla vende gafas en una tienda de anteojos, y gana una comisión cada vez que vende un par de gafas. Siempre trata de venderle a la gente más pares de anteojos, incluyendo gafas graduadas o un par de respaldo, para que pueda aumentar su comisión. A ella no le importa si la persona realmente necesita las gafas de sol recetadas, Carla solo quiere su bono. La calidad de lo que Carla vende no importa porque su comisión no se basa en la calidad; solo se basa en el número de pares vendidos. Esta distinción en la calidad del desempeño puede ayudar a determinar qué método de refuerzo es el más apropiado para una situación particular. Las relaciones fijas son más adecuadas para optimizar la cantidad de salida, mientras que un intervalo fijo, en el que la recompensa no se basa en la cantidad, puede conducir a una mayor calidad de salida.
En un programa de refuerzo de relación variable, el número de respuestas necesarias para una recompensa varía. Este es el horario de refuerzo parcial más potente. Un ejemplo del horario de refuerzo de relación variable es el juego. Imagínese que Sarah, generalmente una mujer inteligente y ahorradora, visita Las Vegas por primera vez. Ella no es jugadora, pero por curiosidad pone un cuarto en la máquina tragaperras, y luego otro, y otro. No pasa nada. Dos dólares en trimestres después, su curiosidad se desvanece, y está a punto de renunciar. Pero entonces, la máquina se enciende, se apagan las campanas y Sarah le devuelve 50 cuartos. ¡Eso es más parecido! Sarah vuelve a insertar cuartos con interés renovado, y unos minutos después ha agotado todas sus ganancias y está 10 dólares en el hoyo. Ahora podría ser un momento sensato para dejar de fumar. Y sin embargo, sigue poniendo dinero en la máquina tragaperras porque nunca sabe cuándo viene el siguiente refuerzo. Ella sigue pensando que con el próximo trimestre podría ganar $50, o $100, o incluso más. Debido a que el horario de refuerzo en la mayoría de los tipos de juego tiene un horario de proporción variable, la gente sigue intentándolo y esperando que la próxima vez gane a lo grande. Esta es una de las razones por las que el juego es tan adictivo y tan resistente a la extinción.
En el condicionamiento operante, la extinción de un comportamiento reforzado ocurre en algún momento después de que el refuerzo se detiene, y la velocidad a la que esto ocurre depende del programa de refuerzo. En un horario de relación variable, el punto de extinción llega muy lentamente, como se describió anteriormente. Pero en los otros horarios de refuerzo, la extinción puede llegar rápidamente. Por ejemplo, si June presiona el botón para el medicamento para el alivio del dolor antes del tiempo asignado que su médico haya aprobado, no se administra ningún medicamento. Ella está en un horario de refuerzo de intervalo fijo (dosificado por hora), por lo que la extinción ocurre rápidamente cuando el refuerzo no llega en el momento esperado. Entre los programas de refuerzo, la relación variable es la más productiva y la más resistente a la extinción. El intervalo fijo es el menos productivo y el más fácil de extinguir (Figura 6.13).
Skinner (1953) declaró: “Si el establecimiento de juego no puede persuadir a un patrón para que entregue dinero sin devolución, puede lograr el mismo efecto devolviendo parte del dinero del patrón en un horario de proporción variable” (p. 397).
Skinner utiliza el juego como ejemplo de la potencia del programa de refuerzo de relación variable para mantener el comportamiento incluso durante largos períodos sin ningún refuerzo. De hecho, Skinner tenía tanta confianza en su conocimiento de la adicción al juego que incluso afirmó que podía convertir a una paloma en un jugador patológico (“La utopía de Skinner”, 1971). De hecho, es cierto que los horarios de relación variable mantienen el comportamiento bastante persistente, solo imagínese la frecuencia de las rabietas de un niño si un padre cede incluso una vez al comportamiento. La recompensa ocasional hace casi imposible detener el comportamiento.
Investigaciones recientes en ratas no han apoyado la idea de Skinner de que el entrenamiento solo en horarios de relación variable causa juego patológico (Laskowski et al., 2019). Sin embargo, otras investigaciones sugieren que el juego parece funcionar en el cerebro de la misma manera que la mayoría de las drogas adictivas, por lo que puede haber alguna combinación de química cerebral y horario de refuerzo que podría conducir a problemas de juego (Figura 6.14). Específicamente, la investigación moderna muestra la conexión entre el juego y la activación de los centros de recompensa del cerebro que utilizan el neurotransmisor (químico cerebral) dopamina (Murch & Clark, 2016). Curiosamente, los jugadores ni siquiera tienen que ganar para experimentar la “fiebre” de la dopamina en el cerebro. “Casi fallas”, o casi ganando pero en realidad no ganando, también se ha demostrado que aumentan la actividad en el estriado ventral y otros centros de recompensa cerebral que usan dopamina (Chase & Clark, 2010). Estos efectos cerebrales son casi idénticos a los que producen las drogas adictivas como la cocaína y la heroína (Murch & Clark, 2016). Con base en la evidencia neurocientífica que muestra estas similitudes, el DSM-5 ahora considera al juego una adicción, mientras que versiones anteriores del DSM clasificaban el juego como un trastorno de control de impulsos.
Además de la dopamina, el juego también parece involucrar a otros neurotransmisores, entre ellos la norepinefrina y la serotonina (Potenza, 2013). La norepinefrina se secreta cuando una persona siente estrés, excitación o emoción. Puede ser que los jugadores patológicos utilicen el juego de azar para aumentar sus niveles de este neurotransmisor. Las deficiencias en la serotonina también podrían contribuir al comportamiento compulsivo, incluida la adicción al juego (Potenza, 2013).
Puede ser que los cerebros de los jugadores patológicos sean diferentes a los de otras personas, y tal vez esta diferencia de alguna manera pueda haber llevado a su adicción al juego, como parecen sugerir estos estudios. No obstante, es muy difícil determinar la causa porque es imposible realizar un verdadero experimento (no sería ético tratar de convertir a los participantes asignados aleatoriamente en jugadores problemáticos). Por lo tanto, puede ser que la causalidad realmente se mueva en la dirección opuesta, tal vez el acto de apostar cambie de alguna manera los niveles de neurotransmisores en el cerebro de algunos jugadores. También es posible que algún factor pasado por alto, o variable confusa, haya jugado un papel tanto en la adicción al juego como en las diferencias en la química cerebral.
Cognición y aprendizaje latente
Conductistas estrictos como Watson y Skinner se centraron exclusivamente en estudiar el comportamiento más que la cognición (como pensamientos y expectativas). De hecho, Skinner era un creyente tan acérrimo que la cognición no importaba que sus ideas fueran consideradas conductismo radical. Skinner consideraba a la mente una “caja negra” —algo completamente incognoscible— y, por tanto, algo que no debía estudiarse. Sin embargo, otro conductista, Edward C. Tolman, tenía una opinión diferente. Los experimentos de Tolman con ratas demostraron que los organismos pueden aprender aunque no reciban refuerzo inmediato (Tolman & Honzik, 1930; Tolman, Ritchie, & Kalish, 1946). Este hallazgo estaba en conflicto con la idea predominante en ese momento de que el refuerzo debe ser inmediato para que se produzca el aprendizaje, sugiriendo así un aspecto cognitivo al aprendizaje.
En los experimentos, Tolman colocó ratas hambrientas en un laberinto sin recompensa por encontrar su camino a través de él. También estudió un grupo de comparación que fue recompensado con comida al final del laberinto. A medida que las ratas no reforzadas exploraban el laberinto, desarrollaron un mapa cognitivo: una imagen mental del trazado del laberinto (Figura 6.15). Después de 10 sesiones en el laberinto sin refuerzo, la comida se colocó en una caja de portería al final del laberinto. Tan pronto como las ratas se dieron cuenta de la comida, pudieron encontrar su camino a través del laberinto rápidamente, tan rápido como el grupo de comparación, que había sido recompensado con comida todo el tiempo. Esto se conoce como aprendizaje latente: aprendizaje que ocurre pero no es observable en el comportamiento hasta que hay una razón para demostrarlo.
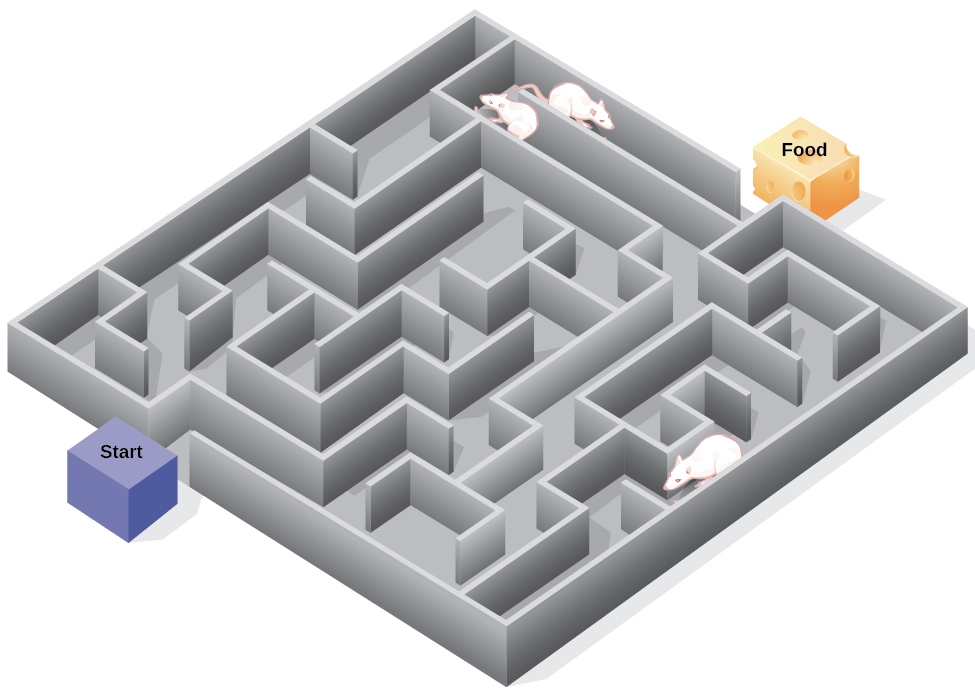
¿Alguna vez te has perdido en un edificio y no has podido encontrar el camino de regreso? Si bien eso puede ser frustrante, no estás solo. En un momento u otro, todos nos hemos perdido en lugares como un museo, hospital o biblioteca universitaria. Cada vez que vamos a algún lugar nuevo, construimos una representación mental, o un mapa cognitivo, de la ubicación, ya que las ratas de Tolman construyeron un mapa cognitivo de su laberinto. Sin embargo, algunos edificios son confusos porque incluyen muchas áreas que se parecen o tienen líneas de visión cortas. Debido a esto, a menudo es difícil predecir lo que hay a la vuelta de una esquina o decidir si girar a la izquierda o a la derecha para salir de un edificio. La psicóloga Laura Carlson (2010) sugiere que lo que colocamos en nuestro mapa cognitivo puede impactar nuestro éxito en la navegación por el medio ambiente. Ella sugiere que prestar atención a características específicas al ingresar a un edificio, como una imagen en la pared, una fuente, una estatua o una escalera mecánica, agrega información a nuestro mapa cognitivo que puede usarse más adelante para ayudar a encontrar nuestra salida del edificio.