
16.A: Matemáticas
- Page ID
- 129688
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Conceptos básicos de vectores
La mecánica clásica describe el movimiento de los cuerpos a medida que se mueven por el espacio. Para describir un movimiento en el espacio no es suficiente dar una posición y una velocidad: también se necesita una dirección. Por lo tanto, trabajamos con vectores: objetos matemáticos que tienen tanto una magnitud como una dirección. Si me dices que te estás moviendo, sé algo, pero no mucho; sabré más si me dices que te estás moviendo a velocidad de marcha, y tienes información completa de tu velocidad una vez que me digas que te estás moviendo a velocidad caminando hacia la máquina de café. Aunque en principio podríamos conformarnos con especificar una magnitud y dirección de cada vector de esta manera, muchas veces es más conveniente expresar nuestros vectores en una base. Para ello, elegimos un origen (arbitrario), y tantos vectores base como tengamos dimensiones espaciales, de tal manera que no sean paralelos entre sí, y generalmente mutuamente perpendiculares (ortogonales) y de longitud unitaria (ortonormal). Luego descomponemos nuestro vector dando sus componentes a lo largo de cada uno de los vectores base. La opción más común es usar una base cartesiana, de dos o tres (dependiendo de la dimensión espacial) vectores base de longitud unitaria apuntando en las direcciones estándar x, y y z, e indicados como\(\hat{\boldsymbol{x}}, \hat{\boldsymbol{y}}\) y\(\hat{\boldsymbol{z}}\), o (más bien molesto) a veces como\(\boldsymbol{i}, \boldsymbol{j}\) y\(\boldsymbol{k}\), este último especialmente en Libros de texto americanos. Otros sistemas que se encuentran a menudo son las coordenadas polares (2D) y las coordenadas cilíndricas y esféricas (3D), consulte el apéndice matemático para obtener más antecedentes sobre esos. Para escribir nuestros vectores, ahora especificamos los componentes en cada dirección, escribiendo por ejemplo\(\boldsymbol{v}=3 \hat{\boldsymbol{x}}+3 \hat{\boldsymbol{y}}\) para un vector (en negrilla) que representa una velocidad de\(3 \sqrt{2}\) y una dirección haciendo un ángulo de\(45^{\circ}\) con la horizontal.
Los vectores se pueden sumar y restar al igual que los escalares, simplemente sumarlos y restarlos por componente. Gráficamente, agregas dos vectores poniéndolos de cabeza a cola: puedes encontrar la suma de dos vectores\(\boldsymbol{v}\) y\(\boldsymbol{w}\) poniendo el inicio de\(\boldsymbol{w}\) al final de\(\boldsymbol{v}\), la suma\(\boldsymbol{v} + \boldsymbol{w}\) luego apunta desde el inicio\(\boldsymbol{v}\) hasta el final de\(\boldsymbol{w}\). También se puede multiplicar un vector por un escalar, multiplicando cada componente del vector con ese escalar. Gráficamente, esto significa que extiendes la longitud del vector con el factor escalar con el que acabas de multiplicar.
No puedes tomar el producto de dos vectores como lo harías con dos escalares. Sin embargo, hay dos operaciones vectoriales que se asemejan mucho al producto, conocidas como producto interno (o punto) y externo (o cruzado), ver Figura 16.A.1. El producto de punto representa la longitud de la proyección de un vector sobre otro (y así da un escalar); es cero para vectores perpendiculares, y el producto de punto de un vector consigo mismo da el cuadrado de su longitud. Para calcular el producto puntual de dos vectores, suma los productos de sus componentes: si\(\boldsymbol{v}=v_{x} \hat{\boldsymbol{x}}+v_{y} \hat{\boldsymbol{y}}\) y\(\boldsymbol{w}=w_{x} \hat{\boldsymbol{x}}+w_{y} \hat{y}\), entonces\(\boldsymbol{v} \cdot \boldsymbol{w}=v_{x} w_{x}+v_{y} w_{y}\). Puede usar el producto punto para encontrar el ángulo entre dos vectores, usando geometría estándar, lo que da
\[\cos \theta=\frac{\boldsymbol{v} \cdot \boldsymbol{w}}{|\boldsymbol{v}||\boldsymbol{w}|}=\frac{v_{x} w_{x}+v_{y} w_{y}}{|\boldsymbol{v}||\boldsymbol{w}|}\]
donde\(|\boldsymbol{v}|\) y\(|\boldsymbol{w}|\) son las longitudes de los vectores\(\boldsymbol{v}\) y\(\boldsymbol{w}\), respectivamente. El producto cruzado solo se define para vectores tridimensionales, digamos\(\boldsymbol{v}=v_{x} \hat{\boldsymbol{x}}+v_{y} \hat{\boldsymbol{y}}+v_{z} \hat{\boldsymbol{z}}\) y\(\boldsymbol{w}=w_{x} \hat{\boldsymbol{x}}+w_{y} \hat{\boldsymbol{y}}+w_{z} \hat{z}\). El resultado es otro vector, con una dirección perpendicular al plano abarcado por\(\boldsymbol{v}\) y\(\boldsymbol{w}\), y una magnitud igual al área del paralelogramo delimitado por ellos. El producto cruzado se expresa más fácilmente en forma de vector de columna:
\ [\ boldsymbol {v}\ times\ negridsymbol {w} =\ left (\ begin {array} {c}
{v_ {x}}\\
{v_ {y}}\\
{v_ {z}}
\ end {array}\ derecha)\ veces\ left (\ begin {array} {c}
{w_ {x}}\\\
{w_ {y}\
{w_ {z}}
\ end {array}\ derecha) =\ izquierda (\ begin {array} {c}
{v_ {y} w_ {z} -v_ {z} w_ {y}}\\
{v_ {z} w_ {x} -v_ {x} w_ {z}}\\
{v_ {x} w_ {y} -v_ {y} w_ {x}}
\ end {array}\ derecha)\]
El producto cruzado de un vector consigo mismo es cero.
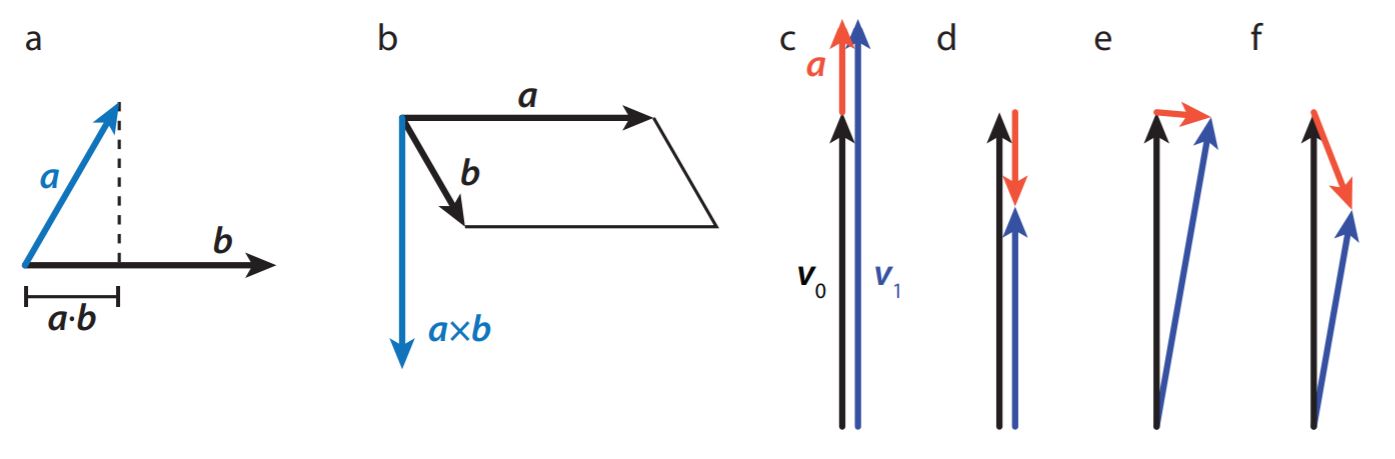
Los vectores pueden ser funciones, al igual que las cantidades escalares: pueden depender de uno o más parámetros, como la posición o el tiempo. Además, nuevamente al igual que las funciones escalares, puedes calcular una tasa de cambio de la función vectorial a medida que te mueves por los valores de los parámetros, por ejemplo preguntando cómo cambia la velocidad de un auto en función del tiempo. Una tasa instantánea de cambio es simplemente una derivada, que se calcula exactamente de la misma manera que la derivada de una función escalar. Por ejemplo, la tasa de cambio de la velocidad, conocida como aceleración\(\boldsymbol{a}\), se define como:
\[\boldsymbol{a}=\lim _{\Delta t \rightarrow 0} \frac{\boldsymbol{v}(t+\Delta t)-\boldsymbol{v}}{\Delta t}\]
Dado que la velocidad en sí es la derivada de la posición\(\boldsymbol{x}(t)\), la aceleración es también la segunda derivada de la posición. Las derivadas del tiempo ocurren con tanta frecuencia en la mecánica clásica que usamos una notación especial para ellas: una primera derivada se indica con un punto encima de la cantidad, y una segunda derivada por un punto doble, así que tenemos\(\boldsymbol{a}=\boldsymbol{\dot { x }}=\ddot{\boldsymbol{x}}\).
Las derivadas de vectores son algo más ricas que las de las funciones escalares, ya que hay más formas en que un vector puede cambiar. Al igual que una función escalar, la magnitud de un vector puede aumentar o disminuir. Además, su dirección también puede cambiar, lo que también significa que tiene una derivada distinta de cero, y por supuesto, se puede tener una combinación de un cambio de magnitud y un cambio de dirección, ver Figura 16.A.1.
Las funciones (escalares o vectoriales) que se definen en cada punto del espacio a veces se denominan campos. Ejemplos son la temperatura (escalar) y el viento (vector) en cada punto del planeta, ver Figura 16.A.2. Así como puedes calcular la tasa de cambio de una función en el tiempo, también puedes considerar cómo cambia una función en el espacio. Para una función escalar, esta cantidad es un vector, conocido como el gradiente, definido como el vector de derivadas parciales. Para una función f (x, y, z), tenemos:
\ [\ negridsymbol {\ nabla} f=\ frac {\ parcial f} {\ parcial x}\ sombrero {\ negridsymbol {x}} +\ frac {\ parcial f} {\ parcial y}\ hat {\ negridsymbol {y}} +\ frac {\ parcial f} {\ parcial z}\ sombrero {\ negritasímbolo {z}} =\ izquierda (\ comienzo array} {c}
{\ parcial f/\ parcial x}\\
{\ parcial f/\ parcial y}\\
{\ parcial f /\ z parcial}
\ end {array}\ derecha)\]
La dirección de\(\boldsymbol{\nabla} f\) es la dirección del cambio máximo, y su magnitud te indica la rapidez con la que cambia la función en esa dirección. Para un campo vectorial\(\boldsymbol{v}\), no podemos tomar el gradiente, pero podemos usar el 'vector'\(\boldsymbol{\nabla}\) de derivadas parciales combinadas ya sea con el punto o producto cruzado. La primera opción se conoce como la divergencia de\(\boldsymbol{v}\), y te dice qué tan rápido\(\boldsymbol{v}\) se extiende; la segunda es el rizo de\(\boldsymbol{v}\) y te dice cuánto\(\boldsymbol{v}\) gira:
\ [\ begin {align}
\ nombreoperador {div} (\ boldsymbol {v}) &=\ negridsymbol {\ nabla}\ cdot\ negritas {v} =\ frac {\ parcial v_ {x}} {\ parcial x} +\ frac {\ parcial v_ {y}} {\ parcial y} +\ frac {\ parcial v_ {z}}\ z parcial}\\
\ nombreoperador {curl} (\ negridsymbol {v}) &=\ negridsymbol {\ nabla}\ veces\ negridsymbol { v} =\ left (\ begin {array} {c}
{\ parcial_ {y} v_ {z} -\ parcial_ {z} v_ {y}}\\
{\ parcial_ {z} v_ {x} -\ parcial_ {x} v_ {z}}\\
{\ parcial_ {x} v_ {y} -\ parcial_ {y} _ {x}}
\ end {array}\ derecha)
\ end {align}\]
dónde\(\partial_{x}= \frac{\partial}{\partial x}\), y así sucesivamente.
Coordenadas polares
Puede especificar cualquier punto en el plano especificando su proyección en dos ejes perpendiculares; normalmente los llamamos los ejes x e y y las coordenadas x e y y. En este sistema cartesiano (llamado así por Descartes), identificamos vectores unitarios\(\hat{\boldsymbol{x}}\) y\(\hat{\boldsymbol{y}}\), apuntando a lo largo de sus respectivos ejes, y siendo de longitud unitaria. Una posición\(\boldsymbol{r}\) puede entonces descomponerse en las dos direcciones:\(\boldsymbol{r}=r_{x} \hat{\boldsymbol{x}}+r_{y} \hat{\boldsymbol{y}}\), con\(r_{x}=\boldsymbol{r} \cdot \hat{\boldsymbol{x}}\) y\(r_{y}=\boldsymbol{r} \cdot \hat{\boldsymbol{y}}\). Alternativamente, podemos escribir\ (\ hat {\ boldsymbol {x}} =\ left (\ begin {array} {l}
{1}\\
{0}
\ end {array}\ right)\) y\ (\ hat {\ boldsymbol {y}} =\ left (\ begin {array} {l}
{0}\\
{1}
\ end {array}\ right)\), que da para\(\boldsymbol{r}\):
\ [\ boldsymbol {r} =r_ {x}\ hat {\ boldsymbol {x}} +r_ {y}\ hat {\ boldsymbol {y}} =\ left (\ begin {array} {l}
{r_ {x}}\\
{r_ {y}}
\ end {array}\ derecha)\]
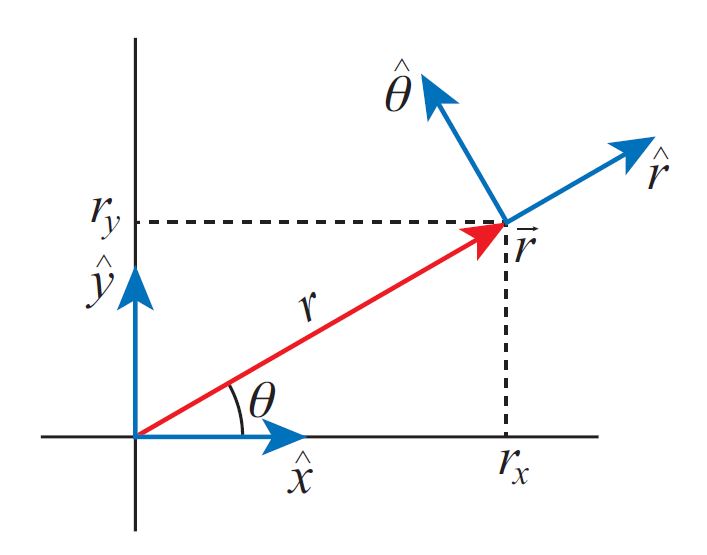
En lugar de especificar las coordenadas x e y de nuestra posición, también podríamos identificarla de manera única dando dos números diferentes: su distancia al origen r, y el ángulo que\(\theta\) la línea al origen hace con un eje de referencia fijo (típicamente el eje x), ver Figura 16.A.3. Invocando el teorema de Pitágoras y la trigonometría básica,
encontramos fácilmente\(r=\sqrt{r_{x}^{2}+r_{y}^{2}}\) y\(\tan \theta= \frac{r_{y}}{r_{x}}\). Llamamos a r la longitud del vector\(\boldsymbol{r}\). También podríamos invertir las relaciones para r y\(\theta\) así podemos obtener los componentes cartesianos si se conocen la longitud y el ángulo:\(r_{x}=r \cos \theta\) y\(r_{y}=r \sin \theta\).
Al igual que los vectores de base cartesiana\(\hat{\boldsymbol{x}}\) y (\ hat {\ boldsymbol {y}}\), que apuntan en la dirección de aumentar los valores x e y, también podemos definir vectores unitarios apuntando en la dirección de aumentar r y\(\theta\). Estas direcciones sí dependen de nuestra posición en el espacio, pero sí tienen una clara interpretación geométrica:\ hat {\ boldsymbol {r}} siempre apunta radialmente hacia afuera desde el origen, y\ hat {\ boldsymbol {\ theta}} en la dirección que te moverías si estuvieras haciendo una rotación en sentido contrario a las agujas del reloj sobre el origen. Dado un vector de posición\(\boldsymbol{r}\), encontrar el vector en la dirección de aumentar r es muy fácil:\(\hat{\boldsymbol{r}}= \boldsymbol{r} / r\). La expresión de r en nuestra nueva base polar\((\hat{\boldsymbol{r}}, \hat{\boldsymbol{\theta}})\) es casi tautológica:\(\boldsymbol{r}=r \hat{\boldsymbol{r}}\).
Relacionar los vectores de base polar con los cartesianos es sencillo. Contamos con:
\[\boldsymbol{r}=r_{x} \hat{\boldsymbol{x}}+r_{y} \hat{\boldsymbol{y}}=r \hat{\boldsymbol{r}}\]
y usando también\(r_{x}=r \cos \theta, r_{y}=r \sin \theta\) tenemos
\[\boldsymbol{r}=r \cos \theta \hat{\boldsymbol{x}}+r \sin \theta \hat{\boldsymbol{y}}\]
Así nos encontramos con eso\(\hat{\boldsymbol{r}}=\cos \theta \hat{\boldsymbol{x}}+\sin \theta \hat{\boldsymbol{y}}\).
Porque\(\hat{\boldsymbol{\theta}\) notamos que para rotar alrededor del origen, la dirección del movimiento necesita ser perpendicular a\(\hat{\boldsymbol{r}}\). Por supuesto, hay dos direcciones de este tipo: elegimos el letrero exigiendo que la rotación en sentido contrario a las agujas del reloj sea positiva. Esto da\(\hat{\boldsymbol{\theta}}=\left(r_{y} / r\right) \hat{\boldsymbol{x}}-\left(r_{x} / r\right) \hat{\boldsymbol{y}}=\sin \theta \hat{\boldsymbol{x}}-\cos \theta \hat{\boldsymbol{y}}\). Escritos como vectores, tenemos:
\ [\ hat {\ boldsymbol {r}} =\ left (\ begin {array} {c}
{\ cos\ theta}\\
{\ sin\ theta}
\ end {array}\ derecha),\ quad\ hat {\ boldsymbol {\ theta}} =\ left (\ begin {array} {c}
{\ sin\ theta}\\
{-\ cos\ theta}
\ end {array}\ derecha)\]
Tenga en cuenta que
\[\hat{\boldsymbol{r}}=\frac{\partial \hat{\boldsymbol{\theta}}}{\partial \theta}, \quad \hat{\boldsymbol{\theta}}=-\frac{\partial \hat{\boldsymbol{r}}}{\partial \theta}\]
Naturalmente, también podemos expresar las bases cartesianas en términos de las polares:
\[\hat{\boldsymbol{x}}=\cos \theta \hat{\boldsymbol{r}}+\sin \theta \hat{\boldsymbol{\theta}}, \quad \hat{\boldsymbol{y}}=\sin \theta \hat{\boldsymbol{r}}-\cos \theta \hat{\boldsymbol{\theta}}\]
Resolver ecuaciones diferenciales
Una ecuación diferencial es una ecuación que contiene derivadas de la función a determinar. Pueden ser muy simples. Por ejemplo, se le puede dar la velocidad (constante) de un automóvil, que es la derivada de su posición, que escribiríamos matemáticamente como:
\[v=\frac{\mathrm{d} x}{\mathrm{d} t}=v_{0} \label{velocity}\]
Para determinar dónde termina el auto después de una hora, necesitamos resolver esta ecuación diferencial. También necesitamos un segundo dato: donde estaba el auto en algún momento de referencia (generalmente t = 0), la condición inicial. Si\(x(0) = 0\), no necesitas habilidades matemáticas avanzadas para averiguarlo\(x(1 hour) = v0 \cdot (1 hour)\). Desafortunadamente, las cosas no suelen ser así de fáciles.
Antes de proceder a algunas técnicas para resolver ecuaciones diferenciales, necesitamos algo de terminología. El orden de una ecuación diferencial es el orden de la derivada más alta que se encuentra en la ecuación; la Ecuación\ ref {velocidad} es así de primer orden. Una ecuación diferencial se llama ordinaria si solo contiene derivadas con respecto a una variable, y parcial si contiene derivadas a múltiples variables. La ecuación es lineal si no contiene ningún producto de (derivados de) la función desconocida. Finalmente, una ecuación diferencial es homogénea si solo contiene términos que contienen la función desconocida, y no homogénea si también contiene otros términos. La ecuación\ ref {velocity} es ordinaria y no homogénea, ya que el\(v_0\) término de la derecha no contiene la función desconocida\(x(t )\). En las secciones siguientes, discutimos los diversos casos que encontrarás en este libro; hay muchos otros (muchos de los cuales no se pueden resolver explícitamente) a los que se dedica todo un subcampo de las matemáticas.
A.3.1. ECUACIONES DIFERENCIALES ORDINARIAS LINEALES DE PRIMER ORDEN
Supongamos que tenemos una ecuación general de la forma
\[a(t) \frac{\mathrm{d} x}{\mathrm{d} t}+b(t) x(t)=f(t) \label{A.11}\]
donde\(a(t ), b(t )\) y\(f (t )\) son funciones conocidas de\(t \), y\(x(t )\) es nuestra función desconocida. La ecuación\ ref {A.11} es una ecuación diferencial no homogénea, ordinaria, lineal, de primer orden. Para resolverlo utilizaremos dos técnicas que son tremendamente útiles: separación de variables y separación en soluciones homogéneas y particulares.
Supongamos que teníamos\(f (t ) = 0\). Entonces, si tuviéramos dos soluciones\(x_1 (t )\) y\(x_2 (t )\) de Ecuación\ ref {A.11}, podríamos construir una tercera como\(x_{1}(t)+x_{2}(t)\) (o cualquier combinación lineal de\(x_1 (t )\) y\(x_2 (t )\)), ya que la ecuación es lineal. Ahora como no\(f (t )\) es cero, no podemos hacer esto, pero podemos hacer otra cosa. Primero, encontramos la solución más general a la ecuación dónde\(f (t ) = 0\), que llamamos la solución homogénea\(x_h (t )\). Segundo, encontramos una solución (cualquiera en absoluto) de la Ecuación completa\ ref {A.11}, que llamamos la solución particular\(x_p (t )\). La solución completa es entonces la suma de estas dos soluciones,\(x(t)=x_{\mathrm{h}}(t)+x_{\mathrm{p}}(t)\). Te puede preocupar que pueda haber múltiples soluciones particulares: ¿cómo elegiríamos la “correcta”? Afortunadamente, no necesitamos preocuparnos: la solución homogénea contendrá una variable desconocida, la cual será establecida por la condición inicial. Cambiar la solución particular cambiará el valor de la variable, de tal manera que la solución final será la misma y satisfará tanto la ecuación diferencial como la condición inicial.
Para encontrar la solución a la ecuación homogénea
\[a(t) \frac{\mathrm{d} x_{\mathrm{h}}}{\mathrm{d} t}+b(t) x_{\mathrm{h}}(t)=0 \label{A.12}\]
vamos a utilizar una técnica llamada separación de variables. Hay dos variables en este sistema: el parámetro independiente t y el parámetro dependiente x El truco es obtener todo dependiendo de t en un lado del signo igual, y todo dependiendo de x del otro. Para ello, vamos a tratar a dx/dt como si se tratara de una fracción 1 real. En ese caso, no es difícil ver que podemos reorganizar la Ecuación\ ref {A.12} para
\[\frac{1}{x_{\mathrm{h}}} \mathrm{d} x_{\mathrm{h}}=-\frac{b(t)}{a(t)} \mathrm{d} t \label{A.13}\]
Por sí misma, la Ecuación\ ref {A.13} significa poco, pero si integramos ambos lados, obtenemos algo que tiene sentido:
\[\int \frac{1}{x_{\mathrm{h}}} \mathrm{d} x_{\mathrm{h}}=\log \left(x_{\mathrm{h}}\right)+C=-\int \frac{b(t)}{a(t)} \mathrm{d} t\]
o
\[x_{\mathrm{h}}(t)=A \exp \left[-\int \frac{b(t)}{a(t)} \mathrm{d} t\right] \label{A.15}\]
donde\(A = exp(C)\) es una constante de integración (la constante desconocida que será establecida por nuestra condición inicial). Por supuesto, en principio puede que no sea posible evaluar la integral en la Ecuación\ ref {A.15}, pero aún entonces la solución es válida. En la práctica, a menudo te encontrarás con situaciones en las que\(a(t )\) y\(b(t )\) son funciones simples o incluso constantes, y la evaluación de la integral es directa. Ahora que tenemos nuestra solución homogénea, todavía necesitamos una en particular. A veces tienes suerte, y puedes adivinar fácilmente uno, por ejemplo uno en el que\(x_p (t )\) no depende\(t\) en absoluto. En caso de que no tengas suerte, hay otras dos técnicas que puedes probar, ya sea usando variación de constantes o encontrando un factor integrador. Para demostrar la variación de constantes, elegiremos un ejemplo específico, para no perderse en un montón de funciones abstractas. Dejar\(a(t ) = a\) ser una constante y\(b(t ) = bt\) ser lineal. La solución homogénea se vuelve entonces\(x_{\mathrm{h}}(t)=A \exp \left[-\frac{1}{2} \frac{b}{a} t^{2}\right]\). La constante que vamos a variar es nuestra constante de integración\(A\), así que nuestra suposición para la solución particular será
\[x_{\mathrm{p}}(t)=A(t) \exp \left[-\frac{1}{2} \frac{b}{a} t^{2}\right] \label{A.16}\]
Sustituimos\ ref {A.16} de nuevo en la ecuación diferencial completa\ ref {A.11}, que da:
\[\left[a \frac{\mathrm{d} A}{\mathrm{d} t}-a A(t) \frac{b t}{a}+b t A(t)\right] \exp \left[-\frac{1}{2} \frac{b}{a} t^{2}\right]=a \frac{\mathrm{d} A}{\mathrm{d} t} \exp \left[-\frac{1}{2} \frac{b}{a} t^{2}\right]=f(t)\]
Una gran parte del lado izquierdo se cancela así, y eso no es una coincidencia, es porque se basa en la ecuación homogénea. Lo que queda es una ecuación diferencial en la\(A(t )\) que se puede resolver trivialmente mediante la integración directa:
\[A(t)=\int \frac{\mathrm{d} A}{\mathrm{d} t} \mathrm{d} t=\frac{1}{a} \int f(t) \exp \left[\frac{1}{2} \frac{b}{a} t^{2}\right] \mathrm{d} t \label{A.18}\]
Nuevamente, puede que no sea posible evaluar la integral en la Ecuación\ ref {A.18}, pero en principio la solución podría insertarse en la Ecuación\ ref {A.16} para darnos nuestra solución particular, y se resolverá toda la ecuación diferencial.
Alternativamente, podemos intentar encontrar un factor de integración para la Ecuación\ ref {A.11}. Esto significa que intentamos reescribir el lado izquierdo de la ecuación como una derivada total, después de lo cual simplemente podemos integrarnos para obtener la solución. Para ello, primero dividimos la ecuación completa por\(a(t )\), luego buscamos una función\(\mu (t )\) que satisfaga la condición de que
\[\frac{\mathrm{d}}{\mathrm{d} t}[\mu(t) x(t)]=\mu(t) \frac{\mathrm{d} x}{\mathrm{d} t}+x(t) \frac{\mathrm{d} \mu}{\mathrm{d} t} \bmod e l s \mu(t) \frac{\mathrm{d} x}{\mathrm{d} t}+\mu(t) \frac{b(t)}{a(t)} x(t)\]
de donde podemos leer que necesitamos resolver la ecuación homogénea
\[\frac{\mathrm{d} \mu}{\mathrm{d} t}=\frac{b(t)}{a(t)} \mu(t) \label{A.20}\]
Podemos resolver\ ref {A.20} por separación de constantes, lo que nos da
\[\mu(t)=\exp \left(\int \frac{b(t)}{a(t)} \mathrm{d} t\right)\]
donde establecemos la constante de integración en uno, ya que cae fuera de la ecuación de\(x(t )\) todos modos. Con esta función\(\mu (t )\), podemos reescribir la Ecuación\ ref {A.11} como
\[\frac{\mathrm{d}}{\mathrm{d} t}[\mu(t) x(t)]=\mu(t) \frac{f(t)}{a(t)}\]
que podemos integrar para encontrar\(x(t )\):
\[x(t)=\frac{1}{\mu(t)} \int \mu(t) \frac{f(t)}{a(t)} \mathrm{d} t\]
A.3.2. ECUACIONES DIFERENCIALES ORDINARIAS LINEALES DE SEGUNDO ORDEN CON COEFICIENTES CONSTANTES
Las ecuaciones diferenciales ordinarias de segundo orden son esenciales para el estudio de la mecánica, ya que su ecuación central, la segunda ley del movimiento de Newton (Ecuación 2.1.4) es de este tipo. En el caso de que la ecuación también sea lineal, tenemos algunas esperanzas de resolverla analíticamente. Existen varios ejemplos de este tipo de ecuaciones en el texto principal, especialmente en la Sección 2.6, donde resolvemos la ecuación de movimiento resultante de la segunda ley de Newton para tres casos especiales, y la Sección 8.1, donde estudiamos una serie de variantes del oscilador armónico. Para el caso de que la ecuación sea homogénea y tenga coeficientes constantes, podemos anotar la solución general 2. La ecuación a resolver es de la forma
\[a \frac{\mathrm{d}^{2} x}{\mathrm{d} t^{2}}+b \frac{\mathrm{d} x}{\mathrm{d} t}+c x(t)=0 \label{A.24}\]
Para el caso de que\(a = 0\), recuperamos una ecuación diferencial de primer orden, cuya solución es una exponencial (como se puede encontrar por separación de variables e integración):\(x(t) = C exp(c t/b)\). En muchos casos un exponencial es también una solución de la Ecuación\ ref {A.24}. Para averiguar cuál exponencial, comencemos con la función trial (o 'Ansatz')\(x(t) = exp(\lambda t)\), donde\(\lambda\) es un parámetro desconocido. Sustituyendo este Ansatz en la Ecuación\ ref {A.24} produce el polinomio característico para esta oda:
\[a \lambda^{2}+b \lambda+c=0\]
que casi siempre tiene dos soluciones:
\[\lambda_{\pm}=-\frac{b}{2 a} \pm \frac{\sqrt{b^{2}-4 a c}}{2 a} \label{A.26}\]
Tenga en cuenta que las soluciones pueden ser reales o complejas. Si hay dos de ellos, podemos escribir la solución general 3 de la Ecuación\ ref {A.24} como una combinación lineal del Ansatz con los dos casos:
\[x(t)=A e^{\lambda_{+} t}+B e^{\lambda_{-} t} \label{A.27}\]
donde A y B se establecen por condiciones iniciales o de límite. Dado que el\(\lambda_{\pm}\) puede ser complejo, también puede A y B; es su combinación la que debería dar un número real (como\(x(t)\) es real), ver problema A.3.1a.
En el caso de que la Ecuación\ ref {A.26} dé una sola solución, la función exponencial correspondiente sigue siendo una solución de la Ecuación\ ref {A.24}, pero no es la más general, ya que sólo podemos poner una sola constante indeterminada frente a ella. Por lo tanto, necesitamos una segunda solución independiente. Para adivinar uno, aquí hay un tercer truco útil 4: tomar la derivada de nuestra solución conocida\(e^{\lambda t}\),, con respecto al parámetro\(\lambda\). Esto da un segundo Ansatz:\(t e^{\lambda t}\), dónde\(\lambda = −b/2a\). Sustituyendo este Ansatz en la Ecuación\ ref {A.24} para el caso que\(c=b^{2} / 2 a\), encontramos:
\[\frac{\mathrm{d}^{2} x}{\mathrm{d} t^{2}}+b \frac{\mathrm{d} x}{\mathrm{d} t}+\frac{b^{2}}{2 a} x(t)=a\left(-\frac{b}{a}+\frac{b^{2}}{4 a^{2}} t\right) e^{-\frac{b t}{2 a}}+b\left(1-\frac{b}{2 a} t\right) e^{-\frac{b t}{2 a}}+\frac{b^{2}}{4 a} t e^{-\frac{b t}{2 a}}=0\]
por lo que nuestro Ansatz vuelve a ser una solución. Para este caso especial, la solución general viene dada por
\[x(t)=A e^{-\frac{b t}{2 a}}+B t e^{-\frac{b t}{2 a}}\]
En la Sección 8.2, donde discutimos el oscilador armónico amortiguado, el caso especial corresponde al oscilador amortiguado críticamente. Obtenemos un oscilador subamortiguado cuando las raíces del polinomio característico son complejas, y uno sobreamortiguado cuando son reales.
A.3.3. ECUACIONES DIFERENCIALES ORDINARIAS LINEALES DE SEGUNDO ORDEN DE TIPO EULER
Hay una segunda clase de ecuaciones diferenciales ordinarias lineales que podemos resolver explícitamente: las del tipo Euler (o Cauchy-Euler), donde el coeficiente frente a una derivada contiene la variable a la potencia de la derivada, es decir, para una ecuación diferencial de segundo orden, tenemos como la más general forma:
\[a x^{2} \frac{d^{2} y}{d x^{2}}+b x \frac{d y}{d x}+c y(x)=0 \label{A.30}\]
Tenga en cuenta que ahora estamos resolviendo\(y(x)\); lo hacemos porque este tipo de ecuación generalmente ocurre en el contexto de funciones dependientes de la posición en lugar de funciones dependientes del tiempo. Un ejemplo es la ecuación de Laplace\(\left(\nabla^{2} y=0\right)\) en coordenadas polares. Al igual que para la oda de segundo orden con coeficientes constantes, la oda de tipo Euler puede generalizarse a ecuaciones de orden superior.
Hay (al menos) dos formas de resolver la Ecuación\ ref {A.30}: a través de un Ansatz, y a través de un cambio de variables. Para el Ansatz, tenga en cuenta que para cualquier polinomio, la derivada de cada término reduce la potencia por uno, y aquí estamos multiplicando cada uno de esos términos con la variable a la potencia el número de derivadas 5. Esto sugiere que simplemente probamos un polinomio, así será nuestro Ansatz aquí\(y(x)=x^{n}\). Sustituyendo en la Ecuación\ ref {A.30} da:
\[a x^{2} n(n-1) x^{n-2}+b x n x^{n-1}+c x^{n}=[a n(n-1)+b n+c] x^{n}=0\]
así conseguimos otro polinomio de segundo orden para resolver, esta vez en\(n\):
\[a n^{2}+(b-a) n+c=0 \quad \Rightarrow \quad n_{\pm}=\frac{1}{2}-\frac{b}{2 a} \pm \frac{1}{2} \sqrt{(a-b)^{2}-4 a c} \label{A.32}\]
Si las raíces en la Ecuación\ ref {A.32} son ambas reales (el caso más común en problemas de física), tenemos dos soluciones independientes, y ya terminamos. Si las raíces son complejas, también tenemos dos soluciones independientes, aunque implican potencias complejas de\(x\); como para la ecuación con coeficientes constantes, podemos reescribirlas como funciones reales con la fórmula de Euler (ver problema A.3.1b). Para el caso de que solo tengamos una raíz, nuevamente aplicamos nuestro truco para obtener una segunda: lo intentamos\(\frac{\mathrm{d} x^{n}}{\mathrm{d} n}=x^{n} \ln (x)\), lo que resulta ser efectivamente una solución (problema A.3.1c), y la solución general es nuevamente una combinación lineal de las dos soluciones encontradas.
Alternativamente, podríamos haber resuelto la Ecuación\ ref {A.30} mediante un cambio de variables. Si bien este método ocasionalmente es útil (y así es bueno estar al tanto de su existencia), no existe una forma sistemática de derivar qué cambio de variables va a hacer el truco, así que tendrás que ir por prueba y error (sin garantía a priori de éxito). En este caso, este proceso lleva a la siguiente sustitución:
\[x=e^{t}, \quad y(x)=y\left(e^{t}\right) \equiv \phi(t) \label{A.33}\]
donde presentamos\(\phi (t)\) por conveniencia. Tomando derivados de\(y(x)\) con la regla de la cadena da
\[\frac{\mathrm{d} y}{\mathrm{d} x}=\frac{\mathrm{d} y}{\mathrm{d} t} \frac{\mathrm{d} t}{\mathrm{d} x}=\frac{1}{x} \frac{\mathrm{d} \phi}{\mathrm{d} t}, \quad \frac{\mathrm{d}^{2} y}{\mathrm{d} x^{2}}=\frac{1}{x^{2}}\left(\frac{\mathrm{d}^{2} \phi}{\mathrm{d} t^{2}}-\frac{\mathrm{d} \phi}{\mathrm{d} t}\right) \label{A.34}\]
que es una ecuación diferencial de segundo orden con coeficientes constantes, y por lo tanto de la forma dada en la Ecuación\ ref {A.24}. Por lo tanto, sabemos encontrar sus soluciones, y podemos usar la Ecuación\ ref {A.33} para transformar esas soluciones de nuevo en funciones\(y(x)\).
A.3.4. Reducción de Orden
Si te encuentras con una ecuación diferencial de segundo orden no homogénea donde la ecuación homogénea tiene coeficientes constantes o es de tipo Euler, nuevamente puedes usar la técnica de variación de constantes para encontrar una solución particular. Una técnica similar, conocida como reducción de orden, puede ayudarte a encontrar soluciones a una ecuación de segundo (o superior) orden donde los coeficientes no son constantes. Para poder utilizar esta técnica, es necesario conocer una solución a la ecuación homogénea, por lo que no es tan universalmente aplicable como las técnicas de las dos secciones anteriores, pero sigue siendo frecuentemente muy útil.
Escribamos la ecuación diferencial lineal general no homogénea de segundo orden como
\[\frac{\mathrm{d}^{2} y}{\mathrm{d} x^{2}}+p(t) \frac{\mathrm{d} y}{\mathrm{d} x}+q(x) y(x)=r(x) \label{A.36}\]
Tenga en cuenta que esta es la forma más general: si hay un coeficiente (constante o no) frente a la segunda derivada, simplemente dividimos toda la ecuación por ese coeficiente y redefinimos los coeficientes para que coincidan con la Ecuación\ ref {A.36}. Ahora supongamos que tenemos una solución\(y_1 (x)\) de la ecuación homogénea (así para el caso que\(r (x) = 0\)). Como la ecuación es homogénea, para cualquier constante\(v\) la función también\(v y_1 (x)\) será una solución. Como Ansatz para la segunda solución, probaremos una variante de variación de constantes, y tomaremos
\[y_{2}(x)=v(x) y_{1}(x) \label{A.37}\]
donde\(v(x)\) es una función arbitraria. Sustituyendo\ ref {A.37} de nuevo en\ ref {A.36}, encontramos
\[y_{1}(x) \frac{\mathrm{d}^{2} v}{\mathrm{d} x^{2}}+\left[2 \frac{\mathrm{d} y_{1}}{\mathrm{d} x}+p(x) y_{1}(x)\right] \frac{\mathrm{d} v}{\mathrm{d} x}+\left[\frac{\mathrm{d}^{2} y_{1}}{\mathrm{d} x^{2}}+p(x) \frac{\mathrm{d} y_{1}}{\mathrm{d} x}+q(x) y_{1}(x)\right] v(x)=r(x)\]
Reconocemos el prefactor de\(v(x)\) como exactamente la ecuación homogénea, que\(y_1 (x)\) satisface, por lo que este término se desvanece. Ahora definiendo\(w(x)= \frac{\mathrm{d} v}{\mathrm{d} x}\), nos queda una ecuación de primer orden para\(w(x)\):
\[y_{1}(x) \frac{\mathrm{d} w}{\mathrm{d} x}+\left[2 \frac{\mathrm{d} y_{1}}{\mathrm{d} x}+p(x) y_{1}(x)\right] w(x)=r(x) \label{A.39}\]
La ecuación\ ref {A.39} es una ecuación diferencial lineal de primer orden, y puede resolverse mediante las técnicas de la Sección A.3.1. La integración de la ecuación nos da\(w(x)= \frac{\mathrm{d} v}{\mathrm{d} x}\) entonces\(v(x)\), y de ahí la segunda solución\ ref {A.37} de la ecuación diferencial de segundo orden (no homogénea).
A.3.5. SERIE DE POWER
Si ninguna de las técnicas en las secciones anteriores se aplica a tu ecuación diferencial, hay un último Ansatz que puedes probar: una expansión en serie de potencia de tu solución. Para ilustrar, volveremos a elegir un ejemplo concreto: la ecuación diferencial de Legendre, dada por
\[\frac{\mathrm{d}}{\mathrm{d} x}\left[\left(1-x^{2}\right) \frac{\mathrm{d} y}{\mathrm{d} x}\right]+n(n+1) y(x)=\left(1-x^{2}\right) \frac{\mathrm{d}^{2} y}{\mathrm{d} x^{2}}-2 x \frac{\mathrm{d} y}{\mathrm{d} x}+n(n+1) y(x)=0 \label{A.40}\]
donde\(n\) es un entero. Como Ansatz para la solución, probaremos una expansión de la serie de potencia de\(y(x)\):
\[y(x)=\sum_{k=0}^{\infty} a_{k} x^{k} \label{A.41}\]
Nuestra tarea es ahora encontrar números\(a_k\) (muchos de los cuales pueden ser cero) de tal manera que\ ref {A.41} sea una solución de\ ref {A.40}. Afortunadamente, simplemente podemos sustituir nuestra solución de prueba y reorganizar para obtener
\ [\ begin {align}
0 &=\ izquierda (1-x^ {2}\ derecha)\ frac {\ mathrm {d} ^ {2}} {\ mathrm {d} x^ {2}}\ izquierda (\ sum_ {k=0} ^ {\ infty} a_ {k} x^ {k}\ derecha) -2 x\ frac {\ mathrm {d}}\ mathrm {d} x}\ izquierda (\ suma_ {k=0} ^ {\ infty} a_ {k} x^ {k}\ derecha) +n (n+1)\ suma_ {k=1} ^ {\ infty} a_ {k} x^ {k}\\
&=\ izquierda (1-x^ {2}\ derecha)\ izquierda (\ suma_ {k=0} ^ {\ infty} k (k-1) a_ {k} x^ {k-2}\ derecha) -2 x\ izquierda (\ suma_ {k=0} ^ {\ infty} k a_ {k} x^ {k-1}\ derecha) +n (n+1)\ sum_ {k=1} ^ {\ infty} a_ {k} x^ k {}\\
&=\ sum_ {k=0} ^ {\ infty}\ izquierda [(-k (k-1) -2 k+n (n+1)) a_ {k} x^ {k} +k (k-1) a_ {k} x^ {k-2}\ derecha]\\
&=\ sum_ {k=0} ^ {\ infty}\ izquierda [(-k (+1) +n (n+1)) a_ {k} + (k+2) (k+1) a_ {k+2}\ derecha] x^ {k}\ etiqueta {a.42d}
\ end {align}\]
donde en la última línea, 'cambiamos' el índice del último término 6. Lo hacemos con el fin de llegar a una expresión para el coeficiente de\(x^i\) para cualquier valor de\(k\). Como las funciones\(x^k\) son linealmente independientes 7 (es decir, no se puede escribir\(x^k\) como una combinación lineal de otras funciones\(x^m\) donde\(m \neq k\)), el coeficiente de cada una de las potencias en la suma en la Ecuación\ ref {a.42D} tiene que desaparecer para que la suma sea idéntica a cero. Esto nos da una relación de recurrencia entre los coeficientes\(a_k\):
\[a_{k+2}=\frac{k(k+1)-n(n+1)}{(k+2)(k+1)} a_{k} \label{A.43}\]
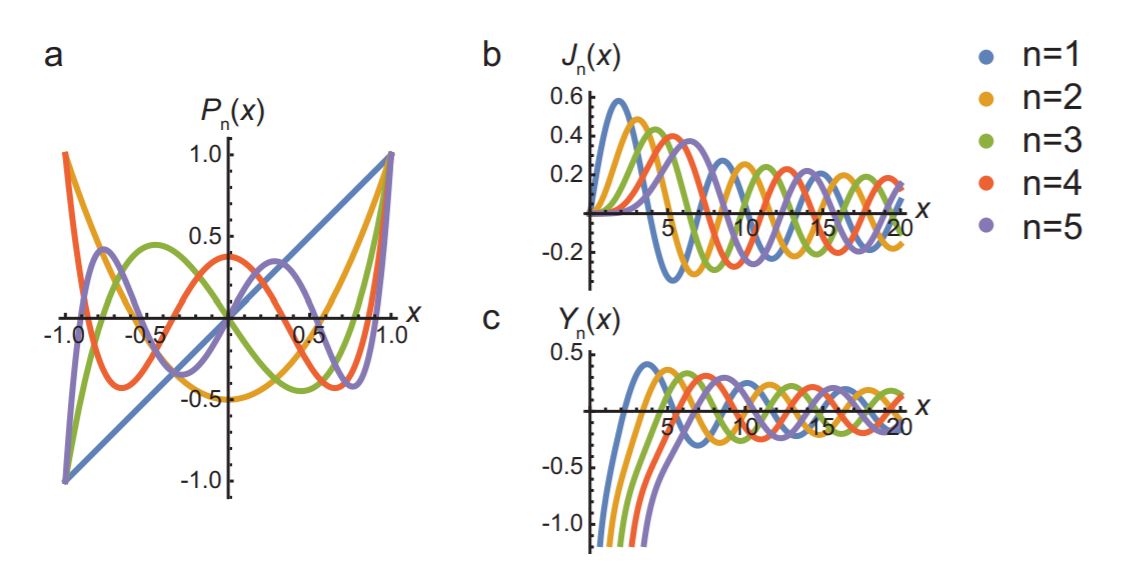
Dados los valores de\(a_0\) y\(a_1\) (los dos grados de libertad que nos permite nuestra ecuación diferencial de segundo orden), podemos aplicar repetidamente la Ecuación\ ref {A.43} para obtener todos los coeficientes. Tenga en cuenta que para\(k = n\) el coeficiente es igual a cero. Por lo tanto, si para un valor par de\(n\), establecemos\(a_1 = 0\), y para un valor impar de\(n\), establecemos\(a_0 = 0\), obtenemos un número finito de coeficientes distintos de cero. Las soluciones resultantes son polinomios, caracterizados por el número\(n\); en este caso, se les conoce como polinomios de Legendre, típicamente denotados\(P_n (x)\), y normalizados (estableciendo el valor del coeficiente libre restante) tal que\(P_n (1) = 1\). En el Cuadro A.1 se enumeran los cinco primeros, que también se representan gráficamente en la Figura 16.A.4a.
Los polinomios de Legendre tienen muchas otras propiedades interesantes (muchas de las cuales se pueden encontrar en libros de texto de matemáticas o en su página de Wikipedia). Ocurren con frecuencia en la física, por ejemplo en la resolución de problemas que involucran la gravedad newtoniana o la ecuación de Laplace a partir de la electrostática.
Si reemplazamos el\(n(n + 1)\) factor en la ecuación diferencial de Legendre por un número arbitrario\(\lambda\), la solución en serie sigue siendo una solución, pero ya no termina 8. Hay muchas otras ecuaciones diferenciales que conducen tanto a series infinitas como a soluciones polinómicas. Un ejemplo bien conocido es la ecuación diferencial de Bessel:
\[x^{2} \frac{\mathrm{d}^{2} y}{\mathrm{d} x^{2}}+x \frac{\mathrm{d} y}{\mathrm{d} x}+\left(x^{2}-n^{2}\right) y(x)=0 \label{A.44}\]
Las soluciones a esta ecuación se conocen como las funciones de Bessel de primer y segundo tipo (ver Problema A.3.3, donde demostrarás que para estas funciones la serie nunca termina). Estas funciones generalizan la función seno y coseno y ocurren en las vibraciones de superficies bidimensionales. Otros ejemplos incluyen los polinomios Hermite y Laguerre, que aparecen en la mecánica cuántica, y las funciones Airy, que puedes encontrar al estudiar óptica.
| \(n\) | \(P_n (x)\) |
|---|---|
| \ (n\) ">0 | \ (P_n (x)\) ">1 |
| \ (n\) ">1 | \ (P_n (x)\) ">x |
| \ (n\) ">2 | \ (P_n (x)\) ">\(\frac{1}{2}(3 x-1)\) |
| \ (n\) ">3 | \ (P_n (x)\) ">\(\frac{1}{2}\left(5 x^{3}-3 x\right)\) |
| \ (n\) ">4 | \ (P_n (x)\) ">\(\frac{1}{8}\left(35 x^{4}-30 x^{2}+3\right)\) |
| \ (n\) ">5 | \ (P_n (x)\) ">\(\frac{1}{8}\left(63 x^{5}-70 x^{3}+15 x\right)\) |
A.3.6. Problemas
A.3.1
- Supongamos que tenemos una solución de Ecuación\ ref {A.24} donde las raíces\(\lambda _{\pm}\) del polinomio característico (Ecuación\ ref {A.26}) son complejas, entonces\(\lambda _{\pm} = \alpha \pm i \beta\). Reescribe la solución general\ ref {A.27} en funciones reales con coeficientes reales C y D, y expresa C y D en términos de A y B. Pista: usa la fórmula de Euler\(e^{i x}=\cos (x)+i \sin (x)\).
- Supongamos que tenemos una solución de Ecuación\ ref {A.32} donde las raíces\(n _{\pm}\) son complejas, entonces\(n_{\pm} = \alpha \pm i \beta\). Para obtener una solución de la Ecuación\ ref {A.30} sin números complejos, hacemos la sustitución\(x = e^t\), así que vuelve a\[x^{n_{\pm}}=x^{\alpha \pm i \beta}=e^{\alpha t} e^{\pm i \beta t}\] usar la fórmula de Euler para reescribir el exponencial complejo en términos de senos y cosenos, y hacer la retro-sustitución a x para mostrar que la solución general de la Ecuación\ ref {A.30} en esta caso es dado por\[y(x)=x^{\alpha}[A \cos (\beta \ln (x))+\sin (\beta \ln (x))]\]
- Supongamos que tenemos una solución de Ecuación\ ref {A.32} para la cual solo hay una sola raíz n. Demostrar que la derivada de\(x^n\) con respecto a n es en este caso también una solución de Ecuación\ ref {A.30}, y que la solución general viene dada por\[y(x)=x^{n}[A+B \ln (x)]\]
A.3.2 Utilizar el método de reducción de orden para obtener una segunda solución de la Ecuación\ ref {A.24} para el caso de que el polinomio característico (Ecuación\ ref {A.26}) tenga una sola raíz.
A.3.3
- Utilice la técnica de series de potencia para encontrar una solución a la Ecuación diferencial de Bessel\ ref {A.44}. ¿Por qué no termina la serie en este caso? ¿Por qué solo obtienes una familia de soluciones? Llamaremos a estas soluciones 'funciones de Bessel de primer tipo' y las etiquetaremos como\(J_n (x)\) (ver Figura 16.A.4b).
- Utilizar el método de reducción de orden para encontrar una segunda familia de soluciones a la ecuación diferencial de Bessel, conocida como 'funciones de Bessel del segundo tipo' (\(Y_n (x)\), ver Figura 16.A.4c).