
14.3: Validar el Método como Método Estándar




- Última actualización
- 30 oct 2022
- Guardar como PDF

( \newcommand{\kernel}{\mathrm{null}\,}\)
Para que un método analítico sea útil, un analista debe ser capaz de lograr resultados de precisión y precisión aceptables. Verificar un método, como se describe en el apartado anterior, establece este objetivo para un solo analista. Otro requisito para un método analítico útil es que un analista obtenga el mismo resultado del día a día, y diferentes laboratorios deben obtener el mismo resultado al analizar la misma muestra. El proceso por el cual aprobamos un método de uso general se conoce como validación e implica una prueba colaborativa del método por parte de analistas en varios laboratorios. Las pruebas colaborativas son utilizadas rutinariamente por agencias reguladoras y organizaciones profesionales, como la Agencia de Protección Ambiental de los Estados Unidos, la Sociedad Americana de Pruebas y Materiales, la Asociación de Químicos Analíticos Oficiales y la Asociación Americana de Salud Pública. Muchos de los métodos representativos de capítulos anteriores son identificados por estas agencias como métodos validados.
Cuando un analista realiza un análisis único en una sola muestra, la diferencia entre el valor determinado experimentalmente y el valor esperado está influenciada por tres fuentes de error: errores aleatorios, errores sistemáticos inherentes al método y errores sistemáticos exclusivos del analista. Si el analista realiza suficientes análisis replicados, entonces podemos trazar una distribución de resultados, como se muestra en la Figura {{template.Index (ID:1)} a. El ancho de esta distribución se describe mediante una desviación estándar que proporciona una estimación de los errores aleatorios que afectan al análisis. La posición de la media de la distribución¯X, relativa al valor real de la muestraμ, está determinada tanto por errores sistemáticos inherentes al método como por aquellos errores sistemáticos únicos del analista. Para un solo analista no hay forma de separar el error sistemático total en sus partes componentes.

El objetivo de una prueba colaborativa es determinar la magnitud de las tres fuentes de error. Si varios analistas analizan cada uno la misma muestra una vez, la variación en sus resultados colectivos (ver Figura 14.3.1 b) incluye contribuciones de errores aleatorios y errores sistemáticos (sesgos) únicos para los analistas. Sin información adicional, no podemos separar la desviación estándar de estos datos agrupados en la precisión del análisis y los errores sistemáticos introducidos por los analistas. Podemos utilizar la posición de la distribución, para detectar la presencia de un error sistemático en el método.
Pruebas colaborativas de dos muestras
El diseño de una prueba colaborativa debe proporcionar la información adicional necesaria para separar los errores aleatorios de los errores sistemáticos introducidos por los analistas. Un enfoque sencillo —aceptado por la Asociación de Químicos Analíticos Oficiales— es que cada analista analice dos muestras que sean similares tanto en su matriz como en su concentración de analito. Para analizar los resultados representamos a cada analista como un punto único en una gráfica de dispersión de dos muestras, utilizando el resultado para una muestra como la coordenada x y el resultado para la otra muestra como la coordenada y [Youden, W. J. “Statistical Techniques for Collaborative Tests”, en Manual Estadístico de la Asociación de Químicos Analíticos Oficiales, Asociación de Químicos Analíticos Oficiales: Washington, D. C., 1975, pp 10—11].
Como se muestra en la Figura 14.3.2 , un gráfico de dos muestras coloca a cada analista en uno de los cuatro cuadrantes, los cuales identificamos como (+, +), (—, +), (—, —) y (+, —). Un signo más indica que el resultado del analista para una muestra es mayor que la media para todos los analistas y un signo menos indica que el resultado del analista es menor que la media para todos los analistas. El cuadrante (+, —), por ejemplo, contiene aquellos analistas que superaron la media para la muestra X y que subestimaron la media para la muestra Y. Si la variación en los resultados está dominada por errores aleatorios, entonces esperamos que los puntos se distribuyan aleatoriamente en los cuatro cuadrantes, con un número igual de puntos en cada cuadrante. Además, como se muestra en la Figura 14.3.2 a, los puntos se agruparán en un patrón circular cuyo centro son los valores medios para las dos muestras. Cuando los errores sistemáticos son significativamente mayores que los errores aleatorios, entonces los puntos caen principalmente en los cuadrantes (+, +) y (—, —), formando un patrón elíptico alrededor de una línea que biseca estos cuadrantes en un ángulo de 45 o, como se ve en la Figura 14.3.2 b.

Una inspección visual de un gráfico de dos muestras es un método efectivo para evaluar cualitativamente las capacidades de un método estándar propuesto, como se muestra en la Figura 14.3.3 . La longitud de una línea perpendicular desde cualquier punto a la línea de 45 o es proporcional al efecto del error aleatorio en los resultados de ese analista. La distancia desde la intersección de los ejes —que corresponde a los valores medios de las muestras X e Y — hasta la proyección perpendicular de un punto en la línea de 45 o es proporcional al error sistemático del analista. Un método estándar ideal tiene pequeños errores aleatorios y pequeños errores sistemáticos debido a los analistas, y tiene una agrupación compacta de puntos que es más circular que elíptica.
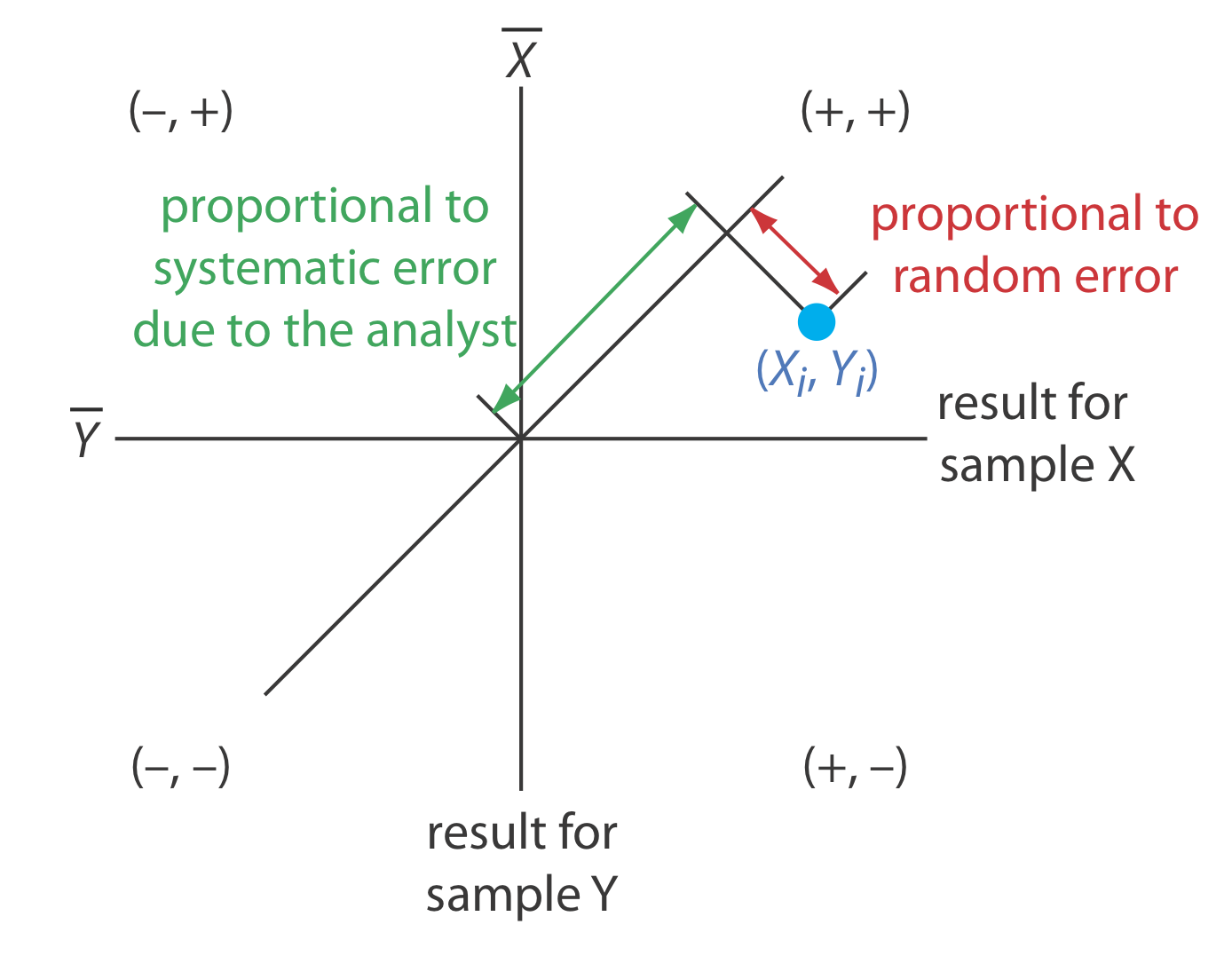
También podemos usar los datos en un gráfico de dos muestras para separar la variación total de los datos, en contribuciones de error aleatorioσtot, y de errores sistemáticos debidos a los analistasσrand,σsyst [Youden, W. J. “Statistical Techniques for Collaborative Tests”, en Statistical Manual de la Asociación de Químicos Analíticos Oficiales, Asociación de Químicos Analíticos Oficiales: Washington, D. C., 1975, pp 22—24]. Debido a que los errores sistemáticos de un analista están presentes en su análisis de ambas muestras, la diferencia, D, entre los resultados estima la contribución del error aleatorio.
D=Xi−Yi
Para estimar la contribución total a partir del error aleatorio utilizamos la desviación estándar de estas diferencias, s D, para todos los analistas
sD=√∑ni=1(Di−¯D)22(n−1)=srand≈σrand
donde n es el número de analistas. El factor de 2 en el denominador de la Ecuación\ ref {14.1} es el resultado de usar dos valores para determinar D i. El total, T, de los resultados de cada analista
Ti=Xi+Yi
contiene contribuciones tanto del error aleatorio como del doble del error sistemático del analista.
La desviación estándar de los totales, s T, proporciona una estimación paraσtot.
sT=√∑ni=1(Ti−¯T)22(n−1)=stot≈σtot
Nuevamente, el factor de 2 en el denominador es el resultado de utilizar dos valores para determinar T i.
Si los errores sistemáticos son significativamente mayores que los errores aleatorios, entonces s T es mayor que s D, hipótesis que podemos evaluar usando una prueba F de una cola
F=s2Ts2D
donde los grados de libertad tanto para el numerador como para el denominador son n — 1. Como se muestra en el siguiente ejemplo, si s T es significativamente mayor que s D podemos usar la Ecuación\ ref {14.2} para separarσ2tot en componentes que representan el error aleatorio y el error sistemático.
Como parte de un estudio colaborativo de un nuevo método para determinar la cantidad de colesterol total en sangre, se envían dos muestras a 10 analistas con instrucciones que analizan cada muestra una vez. Se le devuelven los siguientes resultados, en mg de colesterol total por cada 100 mL de suero.
| analista | muestra 1 | muestra 2 |
|---|---|---|
| 1 | 245.0 | 229.4 |
| 2 | 247.4 | 249.7 |
| 3 | 246.0 | 240.4 |
| 4 | 244.9 | 235.5 |
| 5 | 255.7 | 261.7 |
| 6 | 248.0 | 239.4 |
| 7 | 249.2 | 255.5 |
| 8 | 255.1 | 224.3 |
| 9 | 255.0 | 246.3 |
| 10 | 243.1 | 253.1 |
Utilice esta estimación de datosσrand yσsyst para el método.
Solución
La Figura 14.3.4 proporciona una gráfica de dos muestras de los resultados. La agrupación de puntos sugiere que los errores sistemáticos de los analistas son significativos. La línea vertical a 245.9 mg/100 mL es el valor promedio para la muestra 1 y el valor promedio para la muestra 2 se indica por la línea horizontal en 243.5 mg/100 mL. Estimarσrand y primeroσsyst calculamos los valores para D i y T i.
| analista | D i | T i |
|---|---|---|
| 1 | 15.6 | 474.4 |
| 2 | —2.3 | 497.1 |
| 3 | 5.6 | 486.4 |
| 4 | 9.4 | 480.4 |
| 5 | —6.0 | 517.4 |
| 6 | 8.6 | 487.4 |
| 7 | —6.3 | 504.7 |
| 8 | 0.8 | 449.4 |
| 9 | 8.7 | 501.3 |
| 10 | —10.0 | 496.2 |
A continuación, calculamos las desviaciones estándar para las diferencias, s D, y los totales, s T, usando la Ecuación\ ref {14.1} y la Ecuación\ ref {14.2}, obteniendo s D = 5.95 y s T = 13.3. Para determinar si los errores sistemáticos entre los analistas son significativos, utilizamos una prueba F para comparar s T y s D.
F=s2Ts2D=(13.3)2(5.95)2=5.00
Debido a que la relación F es mayor que F (0.05,9,9), que es 3.179, concluimos que los errores sistemáticos entre los analistas son significativos en el nivel de confianza del 95%. La precisión estimada para un solo analista es
σrand≈srand=sD=5.95
La desviación estándar estimada por errores sistemáticos entre analistas se calcula a partir de la Ecuación\ ref {14.2}.
σsyst=√σ2tot−σ2rand2≈√s2t−s2D2=√(13.3)2−(5.95)22=8.41

Si se conocen los valores verdaderos para las dos muestras, también podemos probar la presencia de un error sistemático en el método. Si no hay errores sistemáticos del método, entonces la suma de los valores verdaderos,μtot, para las muestras X e Y
μtot=μX+μY
debe caer dentro del intervalo de confianza alrededor de T. Podemos usar una prueba t de dos colas de las siguientes hipótesis nulas y alternativas
H0:¯T=μtotHA:¯T≠μtot
para determinar si existe evidencia de un error sistemático en el método. El estadístico de prueba, t exp, es
con n — 1 grados de libertad. Incluimos el 2 en el denominador porque s T (ver Ecuación\ ref {14.3} subestima la desviación estándar¯T al comparar conμtot.
Se sabe que las dos muestras analizadas en el Ejemplo 14.3.1 contienen las siguientes concentraciones de colesterol:μsamp 1 = 248.3 mg/100 mL yμsamp 2 = 247.6 mg/100 mL. Determinar si existe alguna evidencia de error sistemático en el método al nivel de confianza del 95%.
Solución
Usando los datos del Ejemplo 14.3.1 y los valores verdaderos para las muestras, sabemos que s T es 13.3, y que
¯T=¯Xsamp 1 +¯Xsamp 2 =245.9+243.5=489.4 mg/100 mL
μtot=μsamp 1 +musamp 2 =248.3+247.6=495.9 mg/100 mL
Sustituyendo estos valores en la Ecuación\ ref {14.4} da
texp=|489.4−495.9|√1013.3√2=1.09
Debido a que este valor para t exp es menor que el valor crítico de 2.26 para t (0.05, 9), no hay evidencia de un error sistemático en el método al nivel de confianza del 95%.
Ejemplo 14.3.1 y Ejemplo 14.3.2 ilustran cómo podemos usar un par de muestras similares en una prueba colaborativa de un nuevo método. Idealmente, una prueba colaborativa involucra varios pares de muestras que abarcan el rango de concentraciones de analito para las que planeamos usar el método. Al hacerlo, evaluamos el método para fuentes constantes de error y establecemos la desviación estándar relativa esperada y el sesgo para diferentes niveles de analito.
Pruebas colaborativas y análisis de varianza
En una prueba colaborativa de dos muestras pedimos a cada analista que realice una sola determinación en cada una de las dos muestras separadas. Después de reducir los datos a un conjunto de diferencias, D, y un conjunto de totales, T, cada uno caracterizado por una media y una desviación estándar, extraemos valores para los errores aleatorios que afectan la precisión y las diferencias sistemáticas entre entonces analistas. Los cálculos son relativamente simples y directos.
Un enfoque alternativo a una prueba colaborativa es hacer que cada analista realice varias determinaciones replicadas en una sola muestra común. Este enfoque genera un conjunto de datos separado para cada analista y requiere un tratamiento estadístico diferente para proporcionar estimaciones paraσrand y paraσsyst.
Existen varios métodos estadísticos para comparar tres o más conjuntos de datos. El enfoque que consideramos en esta sección es un análisis de varianza (ANOVA). En su forma más simple, un ANOVA unidireccional nos permite explorar la importancia de una sola variable —la identidad del analista es un ejemplo— sobre la varianza total. Para evaluar la importancia de esta variable, comparamos su varianza con la varianza explicada por fuentes indeterminadas de error.
Primero introdujimos la varianza en el Capítulo 4 como una medida de la dispersión de un conjunto de datos alrededor de su tendencia central. En el contexto de un análisis de varianza, es útil para nosotros entender que la varianza es simplemente una relación de dos términos: una suma de cuadrados para las diferencias entre los valores individuales y su media, y los grados de libertad. Por ejemplo, la varianza, s 2, de un conjunto de datos que consiste en n mediciones es
s2=∑ni=1(Xi−¯X)2n−1
donde X i es el valor de una sola medida y¯X es la media. La capacidad de dividir la varianza en una suma de cuadrados y los grados de libertad simplifica enormemente los cálculos en un ANOVA unidireccional.
Vamos a usar un ejemplo simple para desarrollar la justificación detrás de un cálculo ANOVA unidireccional. Los datos de la Tabla 14.3.1 son de cuatro analistas, a cada uno de los cuales se les pidió determinar la pureza de una sola preparación farmacéutica de sulfanilamida. Cada columna de la Tabla 14.3.1 proporciona los resultados para un analista individual. Para ayudarnos a realizar un seguimiento de estos datos, representaremos cada resultado como X ij, donde i identifica al analista y j indica la réplica. Por ejemplo, X 3,5 es la quinta réplica para el tercer analista, o 94.24%.
Los datos de la Tabla 14.3.1 muestran variabilidad en los resultados obtenidos por cada analista y en la diferencia en los resultados entre los analistas. Existen dos fuentes para esta variabilidad: los errores indeterminados asociados al procedimiento analítico que cada analista experimenta por igual, y los errores sistemáticos o determinados introducidos por los analistas individuales.
Una forma de ver los datos en la Tabla 14.3.1 es tratarlos como una sola muestra grande, caracterizada por una media global y una varianza global
donde h es el número de muestras (en este caso el número de analistas), n i es el número de réplicas para la i-ésima muestra (en este caso el i-ésimo analista), y N es el número total de puntos de datos (en este caso 22). La variación global, que incluye todas las fuentes de variabilidad que afectan a los datos, proporciona una estimación de la influencia combinada de errores indeterminados y errores sistemáticos.
Una segunda forma de trabajar con los datos de la Tabla 14.3.1 es tratar los resultados de cada analista por separado. Si asumimos que cada analista experimenta los mismos errores indeterminados, entonces la varianza, s 2, para cada analista proporciona una estimación separada deσ2rand. Para agrupar estas varianzas individuales, que llamamos varianza dentro de la muestras2w, cuadramos la diferencia entre cada réplica y su media correspondiente, las sumamos y dividimos por los grados de libertad.
σ2rnd≈s2w=∑hi=1∑nij=1(Xij−¯Xi)2N−h
Compare cuidadosamente nuestra descripción de la Ecuación\ ref {14.7} con la ecuación misma. Es importante que entiendas por qué la ecuación\ ref {14.7} proporciona nuestra mejor estimación de los errores indeterminados que afectan a los datos en la Tabla 14.3.1 . Tenga en cuenta que perdemos un grado de libertad por cada una de las h medias incluidas en el cálculo.
Para estimar los errores sistemáticosσ2syst,, que afectan los resultados en la Tabla 14.3.1 necesitamos considerar las diferencias entre los analistas. La varianza de los valores medios individuales sobre la media global, a la que llamamos varianza entre muestras,s2b, es
donde perdemos un grado de libertad para la media global. La varianza entre muestras incluye contribuciones tanto de errores indeterminados como de errores sistemáticos; así
donde¯n es el promedio de réplicas por analista.
¯n=∑hi=1nih
Observe la similitud entre la Ecuación\ ref {14.9} y la Ecuación\ ref {14.2}. El análisis de los datos en una gráfica de dos muestras es lo mismo que un análisis de varianza unidireccional con h = 2.
En un ANOVA unidireccional de los datos de la Tabla 14.3.1 hacemos la hipótesis nula de que no hay diferencias significativas entre los valores medios para los analistas. La hipótesis alternativa es que al menos uno de los valores medios es significativamente diferente. Si la hipótesis nula es verdadera, entoncesσ2syst debe ser cero ys2w ys2b debe tener valores similares. Sis2b es significativamente mayor ques2w, entoncesσ2syst es mayor que cero. En este caso debemos aceptar la hipótesis alternativa de que existe una diferencia significativa entre los medios para los analistas. El estadístico de prueba es la relación F
Fexp=s2bs2w
que se compara con el valor crítico F (a, h — 1, N — h). Se trata de una prueba de significancia de una cola porque sólo nos interesa sis2b es significativamente mayor ques2w.
Amboss2b ys2w son fáciles de calcular para conjuntos de datos pequeños. Para conjuntos de datos más grandes, calculars2w es tedioso. Podemos simplificar los cálculos aprovechando la relación entre los términos de suma de cuadrados para la varianza global (Ecuación\ ref {14.6}), la varianza dentro de la muestra (ecuación ref {14.7}) y la varianza entre muestras (Ecuación\ ref {14.8}). Podemos dividir el numerador de la Ecuación\ ref {14.6}, que es la suma total de cuadrados, SS t, en dos términos
SSt=SSw+SSb
donde SS w es la suma de cuadrados para la varianza dentro de la muestra y SS b es la suma de cuadrados para la varianza entre muestras. El cálculo de SS t y SS b da SS w por diferencia. Finalmente, dividir SS w y SS b por sus respectivos grados de libertad das2w ys2b. La Tabla 14.3.2 resume las ecuaciones para un cálculo ANOVA unidireccional. El ejemplo 14.3.3 te guía a través de los cálculos, usando los datos de la Tabla 14.3.1 .
Los datos de la Tabla 14.3.1 son de cuatro analistas, a cada uno de los cuales se les pidió determinar la pureza de una sola preparación farmacéutica de sulfanilamida. Determinar si la diferencia en sus resultados es significativa enα=0.05. Si existe tal diferencia, estime los valores paraσ2rand yσsyst.
Solución
Para comenzar calculamos la media global (Ecuación\ ref {14.5}) y la varianza global (Ecuación\ ref {14.6}) para los datos agrupados, y las medias para cada analista; estos valores se resumen aquí.
¯¯X=95.87¯¯s2=5.506
¯XA=94.56¯XB=99.88¯XC=94.77¯XD=94.75
Usando estos valores calculamos la suma total de cuadrados
SSt=¯¯s2(N−1)=(5.506)(22−1)=115.63
la suma de cuadrados entre muestras
SSb=h∑i=1ni(¯Xi−¯¯X)2=6(94.56−95.87)2+5(99.88−95.87)2+5(94.77−95.87)2+6(94.75−95.87)2=104.27
y la suma de cuadrados dentro de la muestra
SSw=SSt−SSb=115.63−104.27=11.36
El resto de los cálculos necesarios se resumen en la siguiente tabla.
| fuente | suma de cuadrados | grados de libertad | varianza |
|---|---|---|---|
| entre muestras | 104.27 | h−1=4−1=3 | 34.76 |
| dentro de muestras | 11.36 | N−h=22−4=18 | 0.631 |
Comparando las varianzas encontramos que
Fexp=s2bs2w=34.760.631=55.09
Debido a que F exp es mayor que F (0.05, 3, 18), que es 3.16, rechazamos la hipótesis nula y aceptamos la hipótesis alternativa de que el trabajo de al menos un analista es significativamente diferente del resto de analistas. Nuestra mejor estimación de la varianza dentro de la muestra es
σ2rand≈s2w=0.631
y nuestra mejor estimación de la varianza entre muestras es
σ2syst=s2b−s2w¯n=35.76−0.63122/4=6.205
En este ejemplo la varianza debida a diferencias sistemáticas entre los analistas es casi un orden de magnitud mayor que la varianza debida a la precisión del método.
Habiendo demostrado que existe una diferencia significativa entre los analistas, podemos usar una versión modificada de la prueba t, conocida como la diferencia menos significativa de Fisher, para determinar la fuente de la diferencia. El estadístico de prueba para comparar dos valores medios es la prueba t del Capítulo 4, excepto que reemplazamos la desviación estándar agrupada, s pool, por la raíz cuadrada de la varianza dentro de la muestra del análisis de varianza.
Comparamos t exp con su valor críticot(α,ν) utilizando el mismo nivel de significancia que el cálculo del ANOVA. Los grados de libertad son los mismos que para la varianza dentro de la muestra. Dado que nos interesa saber si la mayor de las dos medias es significativamente mayor que la otra media, el valor det(α,ν) es el de una prueba de significancia de una cola.
Podría preguntarse por qué nos molestamos con el análisis de varianza si estamos planeando usar una prueba t para comparar pares de analistas. Cada t -test lleva una probabilidad,α, de afirmar que una diferencia es significativa aunque no lo sea (un error tipo 1). Siα establecemos en 0.05 y completamos seis pruebas t, la probabilidad de un error tipo 1 aumenta a 0.265. Saber que hay una diferencia significativa dentro de un conjunto de datos, lo que obtenemos del análisis de la varianza, protege la prueba t.
En Ejemplo 14.3.3 mostramos que existe una diferencia significativa entre el trabajo de los cuatro analistas en la Tabla 14.3.1 . Determinar la fuente de esta diferencia significativa.
Solución
Las comparaciones individuales mediante la prueba de diferencia menos significativa de Fisher se basan en la siguiente hipótesis nula y la hipótesis alternativa de una cola apropiada.
H0:¯X1=¯X2HA:¯X1>¯X2orHA:¯X1<¯X2
Usando la ecuación\ ref {14.10} calculamos valores de t exp para cada posible comparación y los comparamos con el valor crítico de una cola de 1.73 para t (0.05, 18). Por ejemplo, t exp para los analistas A y B es
(texp)AB=|94.56−99.88|√0.631×√6×56+5=11.06
Debido a que (t exp) AB es mayor que t (0.05,18) rechazamos la hipótesis nula y aceptamos la hipótesis alternativa de que los resultados para el analista B son significativamente mayores que los del analista A. Continuando con los otros pares es fácil demostrar que (t exp) AC es 0.437, (t exp) AD es 0.414, (t exp) BC es 10.17, (t exp exp) BD es 10.67, y (t exp) CD es 0.04.. Colectivamente, estos resultados sugieren que existe una diferencia sistemática significativa entre el trabajo del analista B y el trabajo de los demás analistas. Por supuesto, no hay forma de decidir si alguno de los cuatro analistas ha realizado un trabajo acertado.
Tenemos evidencia de que el resultado del analista B es significativamente diferente de los resultados de los analistas A, C y D, y no tenemos evidencia de que haya alguna diferencia significativa entre los resultados de los analistas A, C y D . No sabemos si los resultados del analista B son precisos, o si los resultados de los analistas A, C y D son precisos. De hecho, es posible que ninguno de los resultados de la Tabla 14.3.1 sea exacto.
Podemos extender un análisis de varianza a sistemas que involucren más de una sola variable. Por ejemplo, podemos usar un ANOVA bidireccional para determinar el efecto sobre un método analítico tanto del analista como de la instrumentación. El tratamiento del ANOVA multivariado está fuera del alcance de este texto, pero está cubierto en varios de los textos enumerados en los recursos adicionales de este capítulo.
¿Qué es un resultado razonable para un estudio colaborativo?
Las pruebas colaborativas nos proporcionan un método para estimar la variabilidad (o reproducibilidad) entre analistas en diferentes laboratorios. Si la variabilidad es significativa, podemos determinar qué porción se debe a errores de método indeterminados,σ2rand, y qué porción se debe a diferencias sistemáticas entre los analistas,σ2syst. Lo que queda sin respuesta es la siguiente pregunta importante: ¿Cuál es un valor razonable para la reproducibilidad de un método?
Un análisis de casi 10 000 estudios colaborativos sugiere que una estimación razonable para la reproducibilidad de un método es
donde R es el porcentaje de desviación estándar relativa para los resultados incluidos en el estudio colaborativo y C es la cantidad fraccionaria de analito en la muestra sobre una base peso a peso. Se cree que la ecuación\ ref {14.1} es independiente del tipo de analito, el tipo de matriz y el método de análisis. Por ejemplo, cuando una muestra en un estudio colaborativo contiene 1 microgramo de analito por gramo de muestra, C es 10 —6 la desviación estándar relativa estimada es
R=2(1−0.5log10−6)=16%
¿Cuál es la desviación estándar relativa estimada para los resultados de un estudio colaborativo cuando la muestra es analito puro (100% w/w analito)? Repita para el caso donde la concentración del analito sea 0.1% w/w.
Solución
Cuando la muestra es 100% p/p de analito (C = 1) la desviación estándar relativa estimada es
R=2(1−0.5log1)=2%
Esperamos que aproximadamente dos tercios de los participantes en el estudio colaborativo (±1σ) reportarán la concentración del analito dentro del rango de 98% w/w a 102% w/w. Si la concentración del analito es 0.1% w/w (C = 0.001), la desviación estándar relativa estimada es
R=2(1−0.5log0.01)=5.7%
y esperamos que aproximadamente dos tercios de los analistas reportarán la concentración del analito dentro del rango de 0.094% w/w a 0.106% w/w.
Por supuesto, la Ecuación\ ref {14.11} solo estima el estándar relativo esperado. Si la desviación estándar relativa del método cae con un rango de la mitad al doble del valor estimado, entonces es aceptable para su uso por analistas en diferentes laboratorios. El porcentaje de desviación estándar relativa para un solo analista debería ser de la mitad a dos tercios de la desviación estándar relativa para la variabilidad entre analistas.
Para obtener detalles sobre la Ecuación\ ref {14.11}, véase (a) Horwitz, W. Anal. Chem. 1982, 54, 67A—76A; b) Hall, P.; Selinger, B. Anal. Chem. 1989, 61, 1465—1466; c) Albert, R.; Horwitz, W. Anal. Chem. 1997, 69, 789—790, (d) “La increíble función de Horwitz”, Resumen Técnico AMC 17, julio de 2004; (e) Lingser, T. P. J. Tendencias Anal. Chem. 2006, 25, 1125. Para una discusión de las limitaciones de la ecuación, véase Linsinger, T. P. J.; Josephs, R. D. “Limitaciones de la aplicación de la ecuación de Horwitz”, Trends Anal. Chem. 2006, 25, 1125—1130, así como una refutación (Thompson, M. “Limitaciones de la aplicación de la ecuación de Horwitz: una refutación”, Trends Anal. Chem. 2007, 26, 659—661) y respuesta a la refutación (Linsinger, T. P. J.; Josephs, R. D. “Responder a la refutación del profesor Michael Thompson”, Tendencias Anal. Chem. 2007, 26, 662—663.